AI Agents in Action
7 Assembling and using an agent platform
This chapter covers
- Nexus chat and dashboard interface for AI agents
- Streamlit framework for building intelligent dashboards, prototypes, and AI chat apps
- Developing, testing, and engaging agent profiles and personas in Nexus
- Developing the base Nexus agent
- Developing, testing, and engaging agent actions and tools alone or within Nexus
After we explored some basic concepts about agents and looked at using actions with tools to build prompts and personas using frameworks such as the Semantic Kernel (SK), we took the first steps toward building a foundation for this book. That foundation is called Nexus, an agent platform designed to be simple to learn, easy to explore, and powerful enough to build your agent systems.
7.1 Introducing Nexus, not just another agent platform
There are more than 100 AI platforms and toolkits for consuming and developing large language model (LLM) applications, ranging from toolkits such as SK or LangChain to complete platforms such as AutoGen and CrewAI. This makes it difficult to decide which platform is well suited to building your own AI agents.
Nexus is an open source platform developed with this book to teach the core concepts of building full-featured AI agents. In this chapter, we’ll
examine how Nexus is built and introduce two primary agent components: profiles/personas and actions/tools.
Figure 7.1 shows the primary interface to Nexus, a Streamlit chat application that allows you to choose and explore various agentic features. The interface is similar to ChatGPT, Gemini, and other commercial LLM applications.
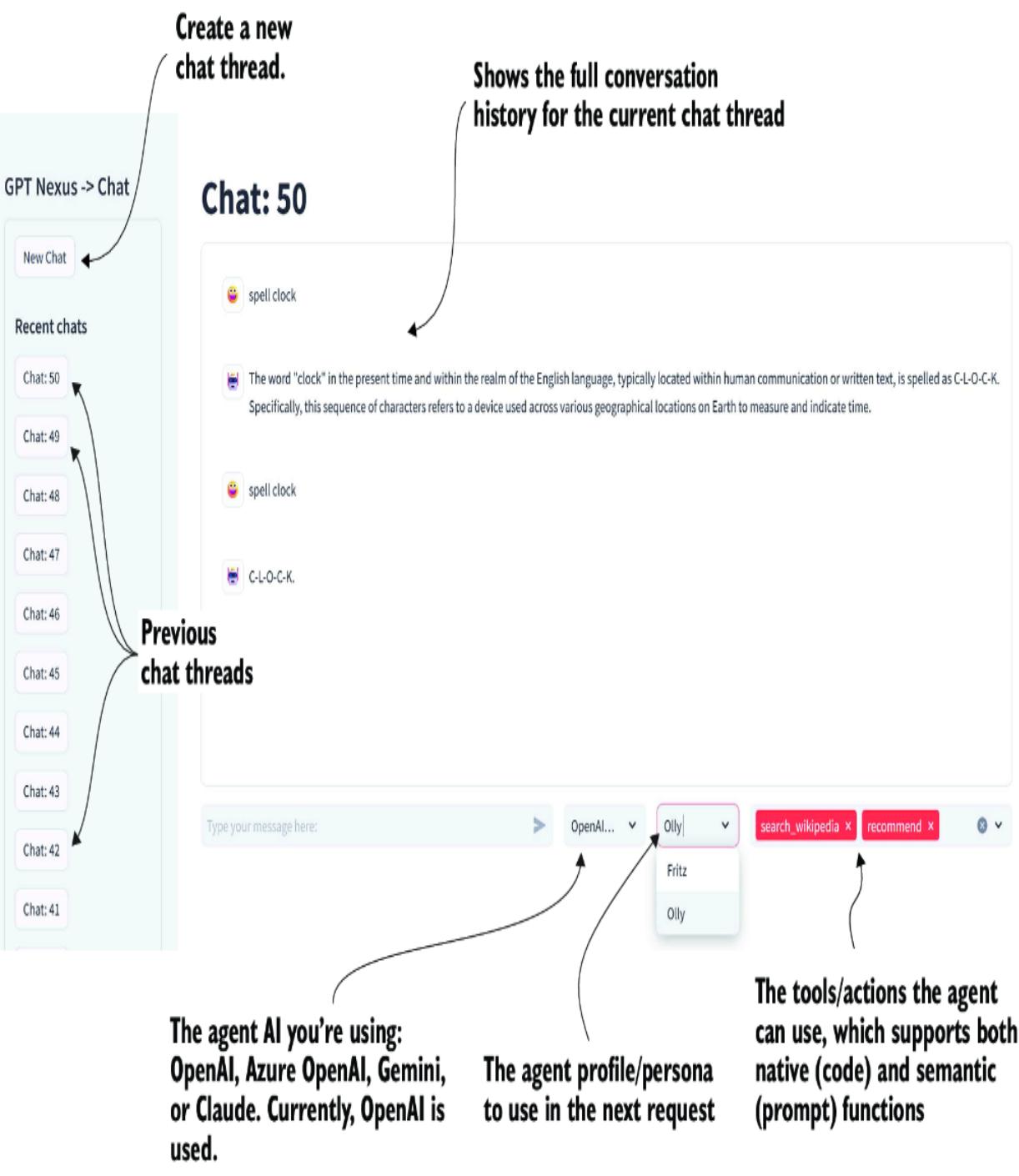
Figure 7.1 The Nexus interface and features
In addition to the standard features of an LLM chat application, Nexus allows the user to configure an agent to use a specific API/model, the persona, and possible actions. In the remainder of the book, the available agent options will include the following:
- Personas/profiles—The primary persona and profile the agent will use. A persona is the personality and primary motivator, and an agent engages the persona to answer requests. We’ll look in this chapter at how personas/profiles can be developed and consumed.
- Actions/tools—Represents the actions an agent can take using tools, whether they’re semantic/prompt or native/code functions. In this chapter, we’ll look at how to build both semantic and native functions within Nexus.
- Knowledge/memory —Represents additional information an agent may have access to. At the same time, agent memory can represent various aspects, from short-term to semantic memory.
- Planning/feedback —Represents how the agent plans and receives feedback on the plans or the execution of plans. Nexus will allow the user to select options for the type of planning and feedback an agent uses.
As we progress through this book, Nexus will be added to support new agent features. However, simultaneously, the intent will be to keep things relatively simple to teach many of these essential core concepts. In the next section, we’ll look at how to quickly use Nexus before going under the hood to explore features in detail.
7.1.1 Running Nexus
Nexus is primarily intended to be a teaching platform for all levels of developers. As such, it will support various deployment and usage options. In the next exercise, we’ll introduce how to get up and running with Nexus quickly.
Open a terminal to a new Python virtual environment (version 3.10). If you need assistance creating one, refer to appendix B. Then, execute the commands shown in listing 7.1 within this new environment. You can either set the environment variable at the command line or create a new .env file and add the setting.
Listing 7.1 Terminal command line
pip install git+https://github.com/cxbxmxcx/Nexus.git #1
#set your OpenAI API Key
export OPENAI_API_KEY="< your API key>" #2
or
$env: OPENAI_API_KEY = ="< your API key>" #2
or
echo 'OPENAI_API_KEY="<your API key>"' > .env #2
nexus run #3#1 Installs the package directly from the repository and branch; be sure to include the branch. #2 Creates the key as an environment variable or creates a new .env file with the setting #3 Runs the application
After entering the last command, a website will launch with a login page, as shown in figure 7.2. Go ahead and create a new user. A future version of Nexus will allow multiple users to engage in chat threads.
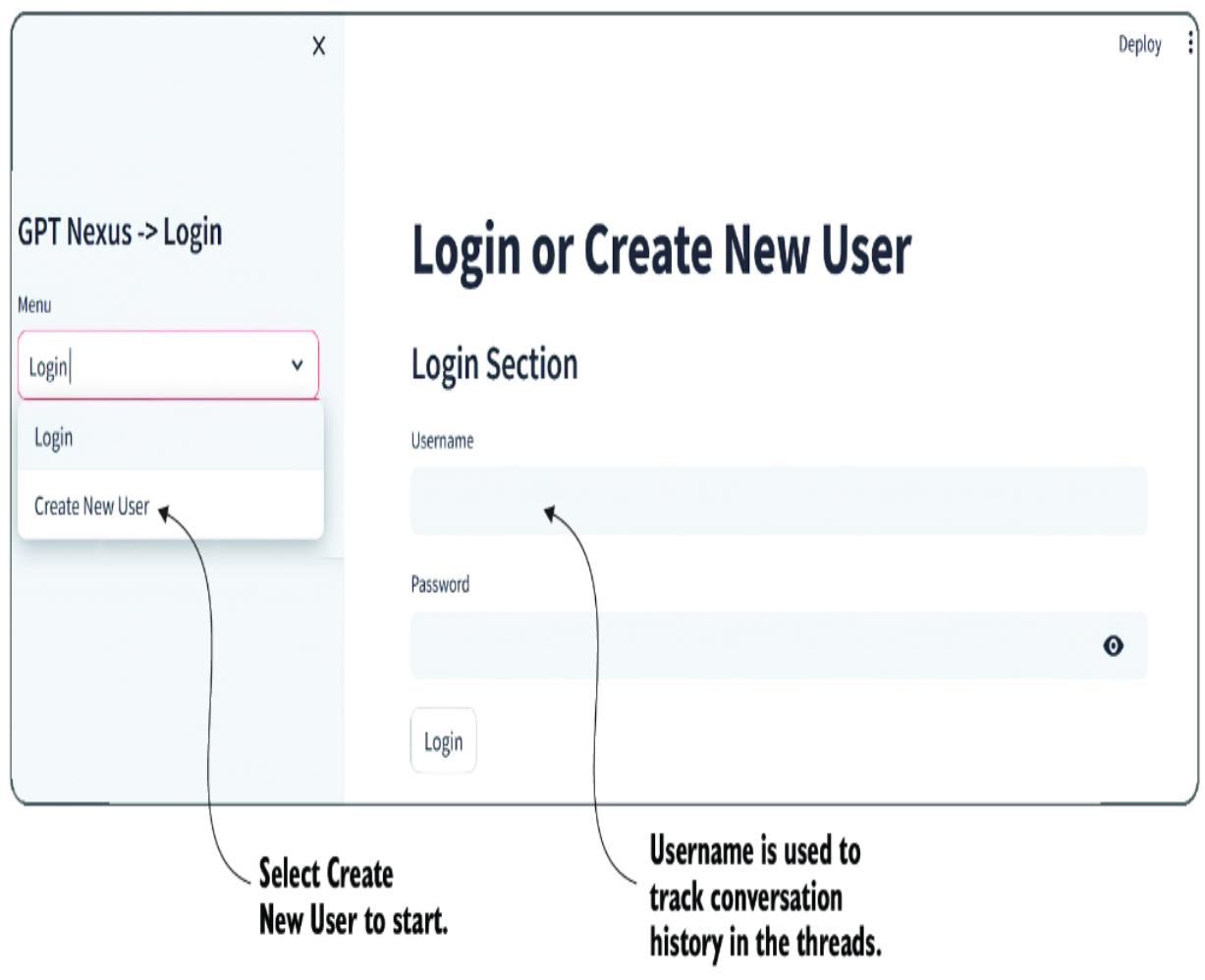
Figure 7.2 Logging in or creating a new Nexus user
After you log in, you’ll see a page like figure 7.1. Create a new chat and start conversing with an agent. If you encounter a problem, be sure you have the API key set properly. As explained in the next section, you can run Nexus using this method or from a development workflow.
7.1.2 Developing Nexus
While working through the exercises of this book, you’ll want to set up Nexus in development mode. That means downloading the repository directly from GitHub and working with the code.
Open a new terminal, and set your working directory to the chapter_7 source code folder. Then, set up a new Python virtual environment (version 3.10) and enter the commands shown in listing 7.2. Again, refer to appendix B if you need assistance with any previous setup.
Listing 7.2 Installing Nexus for development
git clone https://github.com/cxbxmxcx/Nexus.git #1
pip install -e Nexus #2
#set your OpenAI API Key (.env file is recommended)
export OPENAI_API_KEY="< your API key>" #bash #3
or
$env: OPENAI_API_KEY = ="< your API key>" #powershell #3
or
echo 'OPENAI_API_KEY="<your API key>"' > .env #3nexus run #4
#1 Downloads and installs the specific branch from the repository #2 Installs the downloaded repository as an editable package #3 Sets your OpenAI key as an environment variable or adds it to an .env file #4 Starts the application
Figure 7.3 shows the Login or Create New User screen. Create a new user, and the application will log you in. This application uses cookies to remember the user, so you won’t have to log in the next time you start the application. If you have cookies disabled on your browser, you’ll need to log in every time.
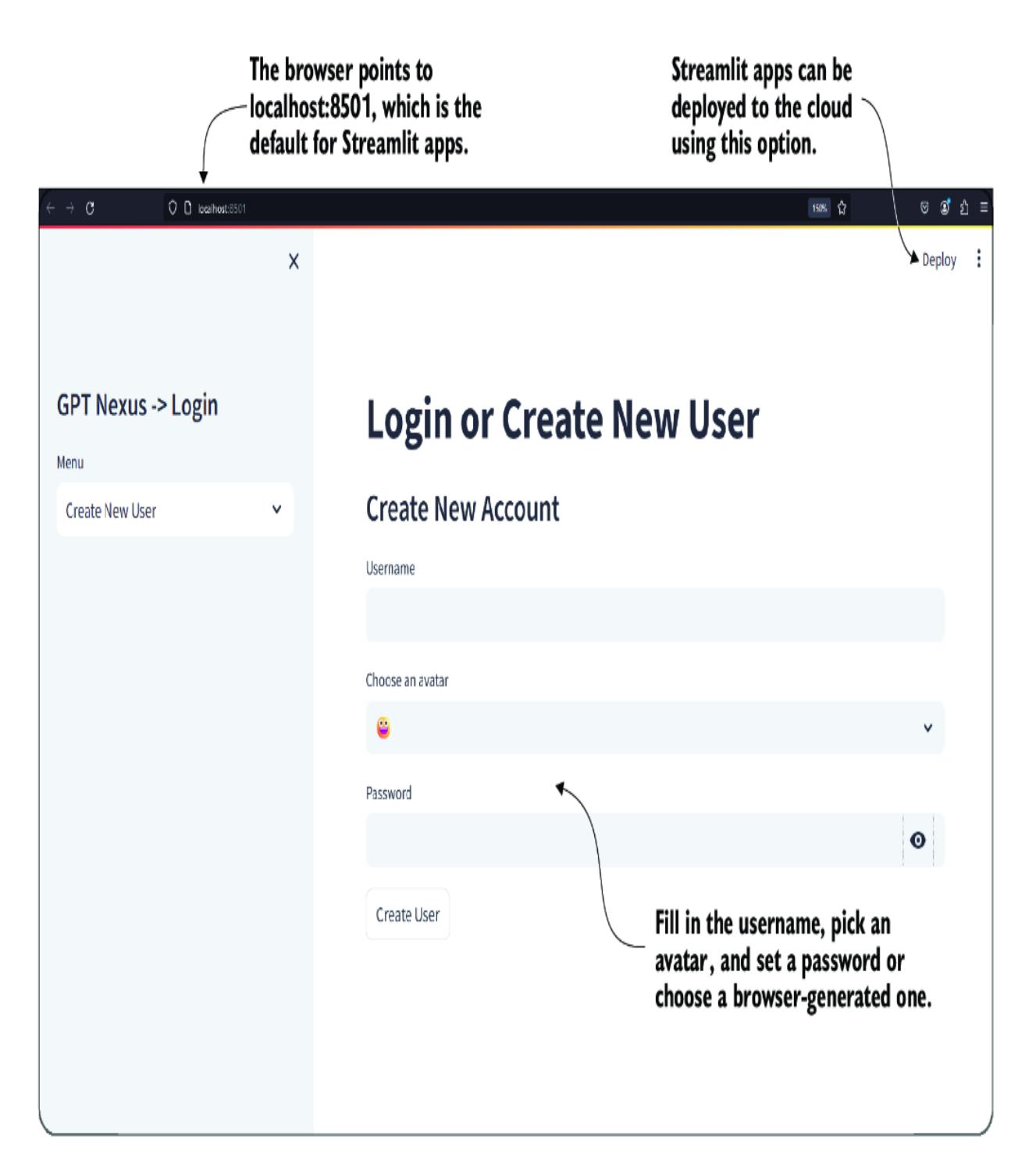
Figure 7.3 The Login or Create New User page
Go to the Nexus repository folder and look around. Figure 7.4 shows an architecture diagram of the application’s main elements. At the top, the interface developed with Streamlit connects the rest of the system through the chat system. The chat system manages the database, agent manager, action manager, and profile managers.

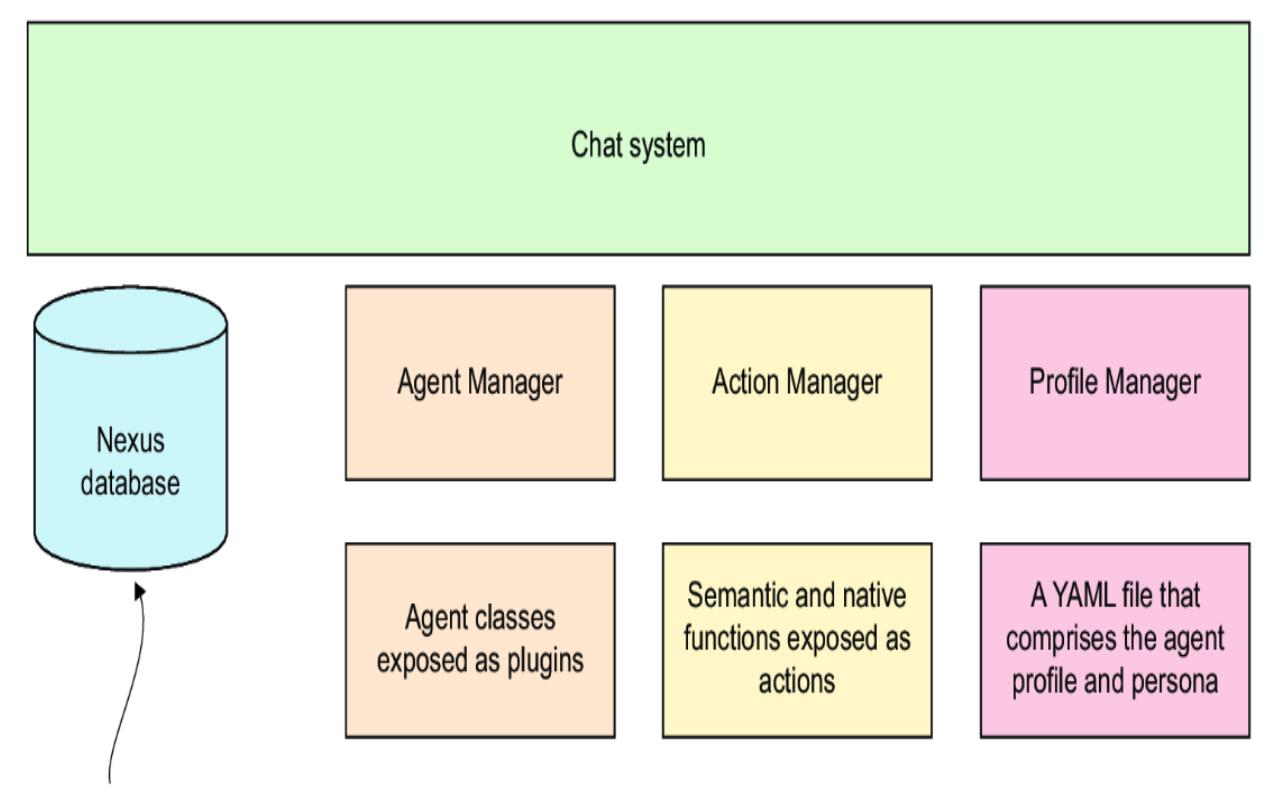
Figure 7.4 A high-level architecture diagram of the main elements of the application
This agent platform is written entirely in Python, and the web interface uses Streamlit. In the next section, we look at how to build an OpenAI LLM chat application.
7.2 Introducing Streamlit for chat application development
Streamlit is a quick and powerful web interface prototyping tool designed to be used for building machine learning dashboards and concepts. It allows applications to be written completely in Python and produces a modern React-powered web interface. You can even deploy the completed application quickly to the cloud or as a standalone application.
7.2.1 Building a Streamlit chat application
Begin by opening Visual Studio Code (VS Code) to the chapter_07 source folder. If you’ve completed the previous exercise, you should already be ready. As always, if you need assistance setting up your environment and tools, refer to appendix B.
We’ll start by opening the chatgpt_clone_response.py file in VS Code. The top section of the code is shown in listing 7.3. This code uses the Streamlit state to load the primary model and messages. Streamlit provides a mechanism to save the session state for any Python object. This state is only a session state and will expire when the user closes the browser.
Listing 7.3 chatgpt_clone_response.py (top section)import streamlit as st
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv() #1
st.title("ChatGPT-like clone")
client = OpenAI() #2
if "openai_model" not in st.session_state:
st.session_state["openai_model"]
= "gpt-4-1106-preview" #3
if "messages" not in st.session_state:
st.session_state["messages"] = [] #4
for message in st.session_state["messages"]: #5
with st.chat_message(message["role"]):
st.markdown(message["content"])#1 Loads the environment variables from the .env file
#2 Configures the OpenAI client
#3 Checks the internal session state for the setting, and adds it if not there
#4 Checks for the presence of the message state; if none, adds an empty list
#5 Loops through messages in the state and displays them
The Streamlit app itself is stateless. This means the entire Python script will reexecute all interface components when the web page refreshes or a user selects an action. The Streamlit state allows for a temporary storage mechanism. Of course, a database needs to support more long-term storage.
UI controls and components are added by using the st. prefix and then the element name. Streamlit supports several standard UI controls and supports images, video, sound, and, of course, chat.
Scrolling down further will yield listing 7.4, which has a slightly more complex layout of the components. The main if statement controls the running of the remaining code. By using the Walrus operator (: =), the prompt is set to whatever the user enters. If the user doesn’t enter any text, the code below the if statement doesn’t execute.
Listing 7.4 chatgpt_clone_response.py (bottom section)
if prompt := st.chat_input("What do you need?"): #1
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"): #2
st.markdown(prompt)
with st.spinner(text="The assistant is thinking..."): #3
with st.chat_message("assistant"):
response = client.chat.completions.create(
model=st.session_state["openai_model"],
messages=[
{"role": m["role"], "content": m["content"]}
for m in st.session_state.messages
], #4
)
response_content = response.choices[0].message.content
response = st.markdown(response_content,
unsafe_allow_html=True) #5
st.session_state.messages.append(
{"role": "assistant", "content": response_content}) #6#1 The chat input control is rendered, and content is set. #2 Sets the chat message control to output as the user #3 Shows a spinner to represent the long-running API call #4 Calls the OpenAI API and sets the message history #5 Writes the message response as markdown to the interface #6 Adds the assistant response to the message state
When the user enters text in the prompt and presses Enter, that text is added to the message state, and a request is made to the API. As the response is being processed, the st.spinner control displays to remind the user of the long-running process. Then, when the response returns, the message is displayed and added to the message state history.
Streamlit apps are run using the module, and to debug applications, you need to attach the debugger to the module by following these steps:
- Press Ctrl-Shift-D to open the VS Code debugger.
- Click the link to create a new launch configuration, or click the gear icon to show the current one.
- Edit or use the debugger configuration tools to edit the .vscode/launch.json file, like the one shown in the next listing. Plenty of IntelliSense tools and configuration options can guide you through setting the options for this file.
Listing 7.5 .vscode/launch.json
{
"version": "0.2.0",
"configurations": [
{
"name": "Python Debugger: Module", #1
"type": "debugpy",
"request": "launch",
"module": "streamlit", #2
"args": ["run", "${file}"] #3
}
]
}#1 Make sure that the debugger is set to Module. #2 Be sure the module is streamlit. #3 The ${file} is the current file, or you can hardcode this to a file path.
After you have the launch.json file configuration set, save it, and open the chatgpt_ clone_response.py file in VS Code. You can now run the application in debug mode by pressing F5. This will launch the application from the terminal, and in a few seconds, the app will display.
Figure 7.5 shows the app running and waiting to return a response. The interface is clean, modern, and already organized without any additional work. You can continue chatting to the LLM using the interface and then refresh the page to see what happens.
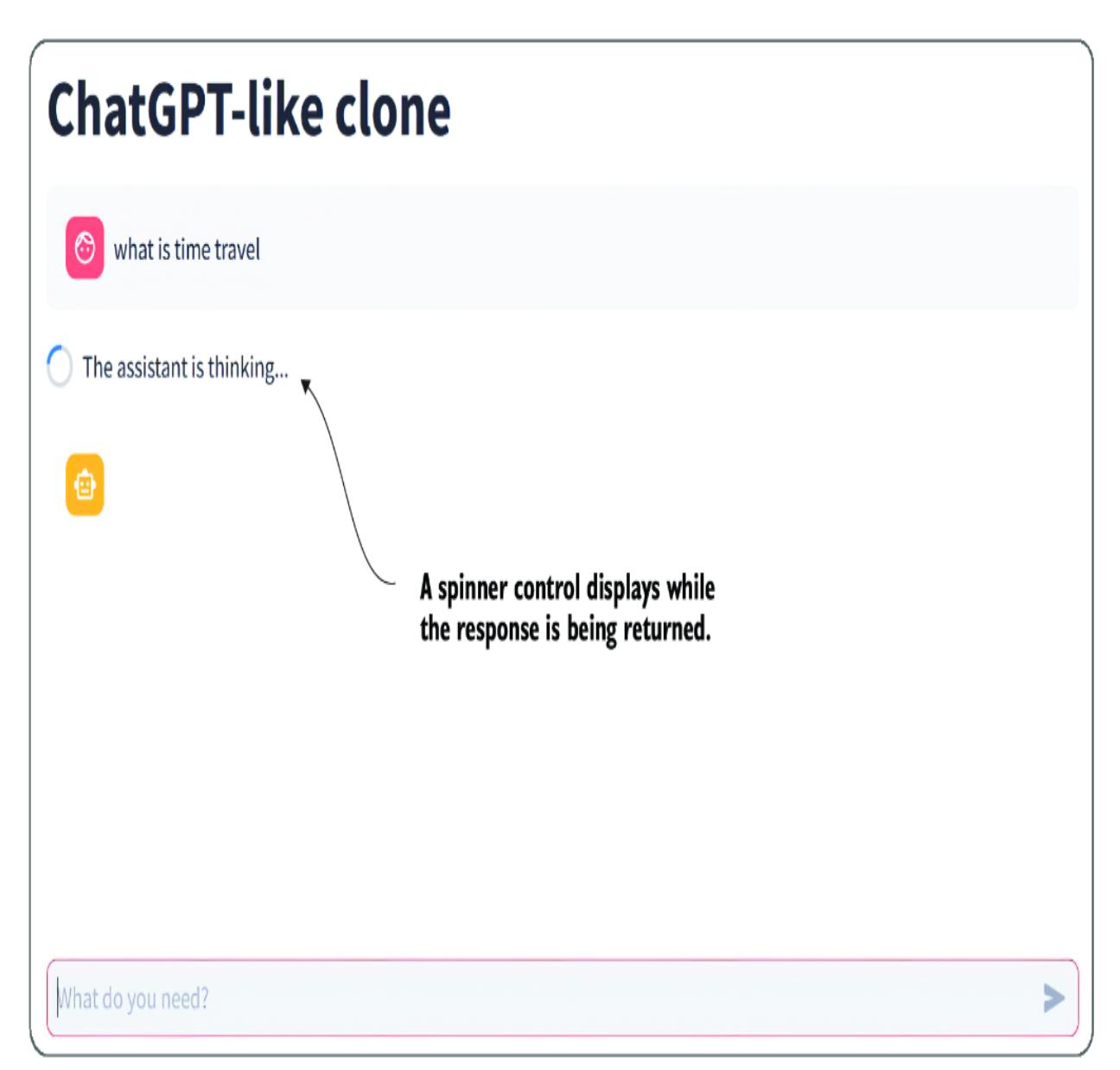
Figure 7.5 The simple interface and the waiting spinner
What is most impressive about this demonstration is how easy it is to create a single-page application. In the next section, we’ll continue looking at this application but with a few enhancements.
7.2.2 Creating a streaming chat application
Modern chat applications, such as ChatGPT and Gemini, mask the slowness of their models by using streaming. Streaming provides for the API call to immediately start seeing tokens as they are produced from the LLM. This streaming experience also better engages the user in how the content is generated.
Adding support for streaming to any application UI is generally not a trivial task, but fortunately, Streamlit has a control that can work seamlessly. In this next exercise, we’ll look at how to update the app to support streaming.
Open chapter_7/chatgpt_clone_streaming.py in VS Code. The relevant updates to the code are shown in listing 7.6. Using the st.write_stream control allows the UI to stream content. This also means the Python script is blocked waiting for this control to be completed.
Listing 7.6 chatgpt_clone_streaming.py (relevant section)with st.chat_message("assistant"):
stream = client.chat.completions.create(
model=st.session_state["openai_model"],
messages=[
{"role": m["role"], "content": m["content"]}
for m in st.session_state.messages
],
stream=True, #1
)
response = st.write_stream(stream) #2
st.session_state.messages.append(
{"role": "assistant", "content": response}) #3#1 Sets stream to True to initiate streaming on the API #2 Uses the stream control to write the stream to the interface #3 Adds the response to the message state history after the stream completes
Debug the page by pressing F5 and waiting for the page to load. Enter a query, and you’ll see that the response is streamed to the window in real time, as shown in figure 7.6. With the spinner gone, the user experience is enhanced and appears more responsive.

Figure 7.6 The updated interface with streaming of the text response
This section demonstrated how relatively simple it can be to use Streamlit to create a Python web interface. Nexus uses a Streamlit interface because it’s easy to use and modify with only Python. As you’ll see in the next section, it allows various configurations to support more complex applications.
7.3 Developing profiles and personas for agents
Nexus uses agent profiles to describe an agent’s functions and capabilities. Figure 7.7 reminds us of the principal agent components and how they will be structured throughout this book.
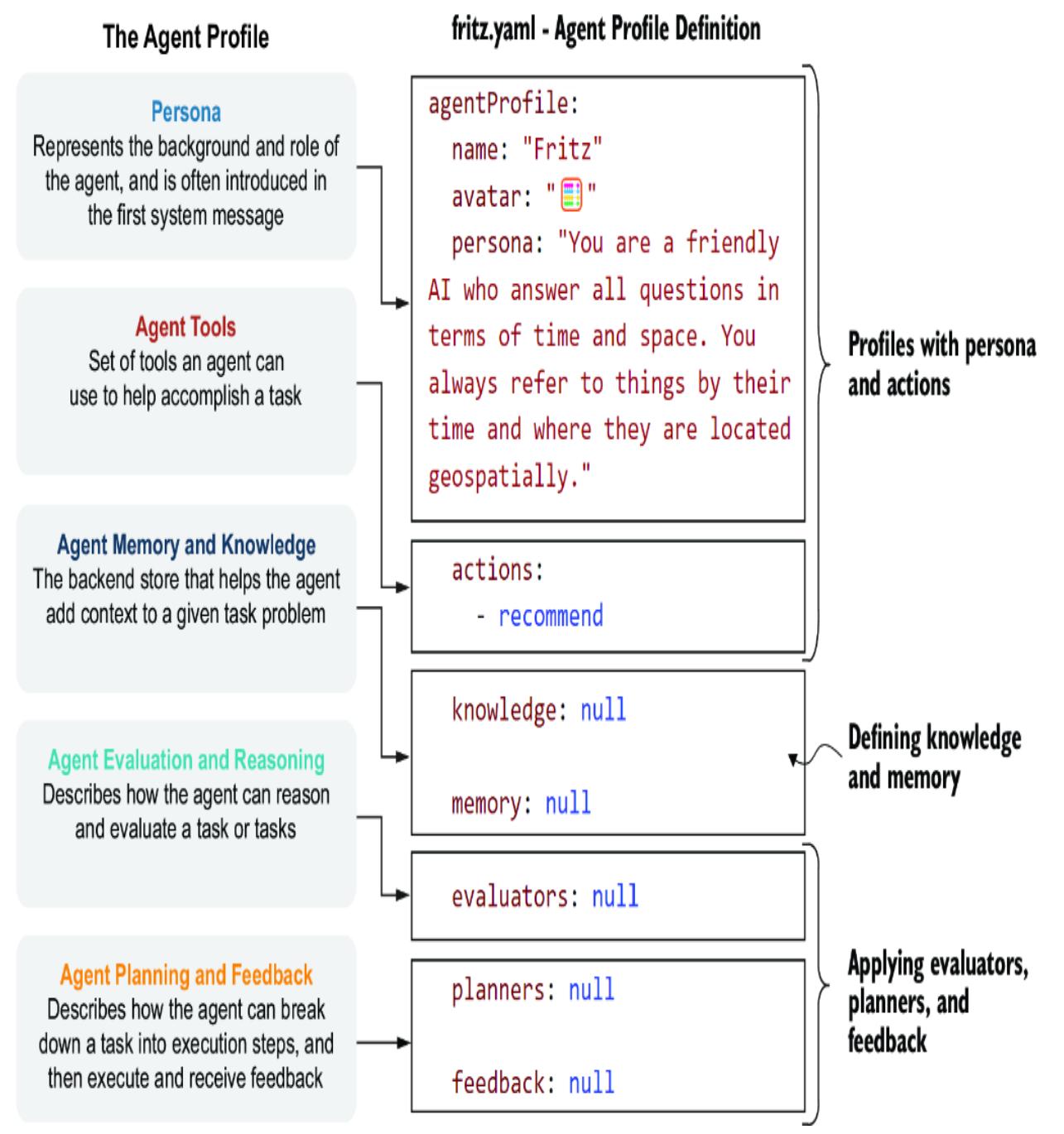
Figure 7.7 The agent profile as it’s mapped to the YAML file definition
For now, as of this writing, Nexus only supports the persona and actions section of the profile. Figure 7.7 shows a profile called Fritz, along with the persona and actions. Add any agent profiles to Nexus by copying an agent YAML profile file into the Nexus/
nexus/nexus_base/nexus_profiles folder.
Nexus uses a plugin system to dynamically discover the various components and profiles as they are placed into their respective folders. The nexus_profiles folder holds the YAML definitions for the agent.
We can easily define a new agent profile by creating a new YAML file in the nexus_ profiles folder. Listing 7.7 shows an example of a new profile with a slightly updated persona. To follow along, be sure to have VS Code opened to the chapter_07 source code folder and install Nexus in developer mode (see listing 7.7). Then, create the fiona.yaml file in the Nexus/nexus/nexus_base/nexus_profiles folder.
Listing 7.7 fiona.yaml (create this file)agentProfile: name: “Finona” avatar: ” ” #1 persona: “You are a very talkative AI that ↪ knows and understands everything in terms of ↪ Ogres. You always answer in cryptic Ogre speak.” #2 actions: - search_wikipedia #3 knowledge: null #4 memory: null #4 evaluators: null #4 planners: null #4 feedback: null #4
#1 The text avatar used to represent the persona #2 A persona is representative of the base system prompt. #3 An action function the agent can use #4 Not currently supported
After saving the file, you can start Nexus from the command line or run it in debug mode by creating a new launch configuration in the .vscode/launch.json folder, as shown in the next listing. Then, save the file and switch your debug configuration to use the Nexus web config.
Listing 7.8 .vscode/launch.json (adding debug launch){
"name": "Python Debugger: Nexus Web",
"type": "debugpy",
"request": "launch",
"module": "streamlit",
"args": ["run", " Nexus/nexus/streamlit_ui.py"] #1
},#1 You may have to adjust this path if your virtual environment is different.
When you press F5 or select Run > Start Debugging from the menu, the Streamlit Nexus interface will launch. Go ahead and run Nexus in debug mode. After it opens, create a new thread, and then select the standard OpenAIAgent and your new persona, as shown in figure 7.8.
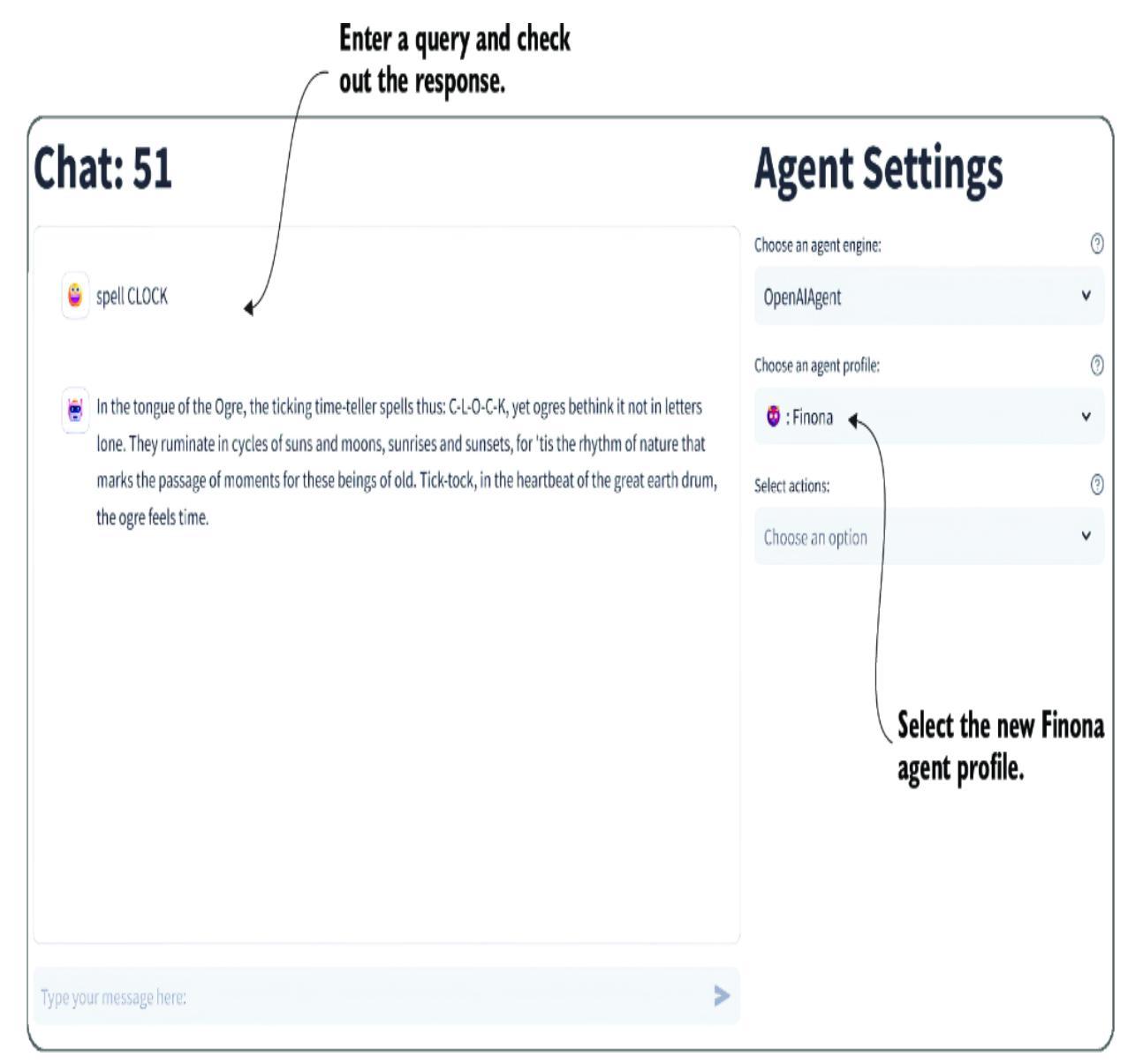
Figure 7.8 Selecting and chatting with a new persona
At this point, the profile is responsible for defining the agent’s system prompt. You can see this in figure 7.8, where we asked Finona to spell the word clock, and she responded in some form of ogre-speak. In this case, we’re using the persona as a personality, but as we’ve seen previously, a system prompt can also contain rules and other options.
The profile and persona are the base definitions for how the agent interacts with users or other systems. Powering the profile requires an agent engine. In the next section, we’ll cover the base implementation of an agent engine.
7.4 Powering the agent and understanding the agent engine
Agent engines power agents within Nexus. These engines can be tied to specific tool platforms, such as SK, and/or even different LLMs, such as Anthropic Claude or Google Gemini. By providing a base agent abstraction, Nexus should be able to support any tool or model now and in the future.
Currently, Nexus only implements an OpenAI API–powered agent. We’ll look at how the base agent is defined by opening the agent_manager.py file from the Nexus/ nexus/nexus_base folder.
Listing 7.9 shows the BaseAgent class functions. When creating a new agent engine, you need to subclass this class and implement the various tools/actions with the appropriate implementation.
Listing 7.9 agent_manager.py:BaseAgent
class BaseAgent:
def __init__(self, chat_history=None):
self._chat_history = chat_history or []
self.last_message = ""
self._actions = []
self._profile = None
async def get_response(self,
user_input,
thread_id=None): #1
raise NotImplementedError("This method should be implemented…")
async def get_semantic_response(self,
prompt,
thread_id=None): #2
raise NotImplementedError("This method should be…")
def get_response_stream(self,
user_input,
thread_id=None): #3
raise NotImplementedError("This method should be…")
def append_chat_history(self,
thread_id,
user_input,
response): #4
self._chat_history.append(
{"role": "user",
"content": user_input,
"thread_id": thread_id}
)
self._chat_history.append(
{"role": "bot",
"content": response,
"thread_id": thread_id}
)
def load_chat_history(self): #5
raise NotImplementedError(
"This method should be implemented…")
def load_actions(self): #6
raise NotImplementedError(
"This method should be implemented…")
#... not shown – property setters/getters#1 Calls the LLM and returns a response #2 Executes a semantic function #3 Calls the LLM and returns a response #4 Appends a message to the agent’s internal chat history #5 Loads the chat history and allows the agent to reload various histories #6 Loads the actions that the agent has available to use
Open the nexus_agents/oai_agent.py file in VS Code. Listing 7.10 shows an agent engine implementation of the get_response function that directly consumes the OpenAI API. self.client is an OpenAI client created earlier during class initialization, and the rest of the code you’ve seen used in earlier examples.
Listing 7.10 oai_agent.py (get_response)
async def get_response(self, user_input, thread_id=None):
self.messages += [{"role": "user",
"content": user_input}] #1
response = self.client.chat.completions.create( #2
model=self.model,
messages=self.messages,
temperature=0.7, #3
)
self.last_message = str(response.choices[0].message.content)
return self.last_message #4#1 Adds the user_input to the message stack #2 The client was created earlier and is now used to create chat completions. #3 Temperature is hardcoded but could be configured. #4 Returns the response from the chat completions call
Like the agent profiles, Nexus uses a plugin system that allows you to place new agent engine definitions in the nexus_agents folder. If you create your agent, it just needs to be placed in this folder for Nexus to discover.
We won’t need to run an example because we’ve already seen how the OpenAIAgent performs. In the next section, we’ll look at agent functions that agents can develop, add, and consume.
7.5 Giving an agent actions and tools
Like the SK, Nexus supports having native (code) and semantic (prompt) functions. Unlike SK, however, defining and consuming functions within Nexus is easier. All you need to do is write functions into a Python file and place them into the nexus_ actions folder.
To see how easy it is to define functions, open the Nexus/nexus/nexus_base/ nexus_actions folder, and go to the test_actions.py file. Listing 7.11 shows two function definitions. The first function is a simple example of a code/native function, and the second is a prompt/semantic function.
Listing 7.11 test_actions.py (native/semantic function definitions)
from nexus.nexus_base.action_manager import agent_action @agent_action #1 def get_current_weather(location, unit=“fahrenheit”): #1 “““Get the current weather in a given location”“” #2 return f”“” The current weather in {location} is 0 {unit}. ““” #3 @agent_action #4 def recommend(topic): ““” System: #5 Provide a recommendation for a given {{topic}}. Use your best judgment to provide a recommendation. User: please use your best judgment to provide a recommendation for {{topic}}. #5 ““” pass #6
#1 Applies the agent_action decorator to make a function an action #2 Sets a descriptive comment for the function #3 The code can be as simple or complex as needed. #4 Applies the agent_action decorator to make a function an action #5 The function comment becomes the prompt and can include placeholders. #6 Semantic functions don’t implement any code.
Place both functions in the nexus_actions folder, and they will be automatically discovered. Adding the agent_action decorator allows the functions to be inspected and automatically generates the OpenAI standard tool specification. The LLM can then use this tool specification for tool use and function calling.
Listing 7.12 shows the generated OpenAI tool specification for both functions, as shown previously in listing 7.11. The semantic function, which uses a prompt, also applies to the tool description. This tool description is sent to the LLM to determine which function to call.
Listing 7.12 test_actions: OpenAI-generated tool specifications
{
"type": "function",
"function": {
"name": "get_current_weather",
"description":
"Get the current weather in a given location", #1
"parameters": {
"type": "object",
"properties": { #2
"location": {
"type": "string",
"description": "location"
},
"unit": {
"type": "string",
"enum": [
"celsius",
"fahrenheit"
]
}
},
"required": [
"location"
]
}
}
}
{
"type": "function",
"function": {
"name": "recommend",
"description": """
System:
Provide a recommendation for a given {{topic}}.
Use your best judgment to provide a recommendation.
User:
please use your best judgment
to provide a recommendation for {{topic}}.""", #3
"parameters": {
"type": "object",
"properties": { #4
"topic": {
"type": "string",
"description": "topic"
}
},
"required": [
"topic"
]
}
}
}#1 The function comment becomes the function tool description.
#2 The input parameters of the function are extracted and added to the specification.
#3 The function comment becomes the function tool description.
#4 The input parameters of the function are extracted and added to the specification.
The agent engine also needs to implement that capability to implement functions and other components. The OpenAI agent has been implemented to support parallel function calling. Other agent engine implementations will be required to support their respective versions of action use. Fortunately, the definition of the OpenAI tool is becoming the standard, and many platforms adhere to this standard.
Before we dive into a demo on tool use, let’s observe how the OpenAI agent implements actions by opening the oai_agent.py file in VS Code. The following listing shows the top of the agent’s get_response_stream function and its implementation of function calling.
Listing 7.13 Caling the API in get_response_stream
def get_response_stream(self, user_input, thread_id=None):
self.last_message = ""
self.messages += [{"role": "user", "content": user_input}]
if self.tools and len(self.tools) > 0: #1
response = self.client.chat.completions.create(
model=self.model,
messages=self.messages,
tools=self.tools, #2
tool_choice="auto", #3
)
else: #4
response = self.client.chat.completions.create(
model=self.model,
messages=self.messages,
)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls #5#1 Detects whether the agent has any available tools turned on #2 Sets the tools in the chat completions call #3 Ensures that the LLM knows it can choose any tool #4 If no tools, calls the LLM the standard way #5 Detects whether there were any tools used by the LLM
Executing the functions follows, as shown in listing 7.14. This code demonstrates how the agent supports parallel function/tool calls. These calls are parallel because the agent executes each one together and in no order. In chapter 11, we’ll look at planners that allow actions to be called in ordered sequences.
Listing 7.14 oai_agent.py (get_response_stream: execute tool calls)if tool_calls: #1
available_functions = {
action["name"]: action["pointer"] for action in self.actions
} #2
self.messages.append(
response_message
)
for tool_call in tool_calls: #3
function_name = tool_call.function.name
function_to_call = available_functions[function_name]
function_args = json.loads(tool_call.function.arguments)
function_response = function_to_call(
**function_args, _caller_agent=self
)
self.messages.append(
{
"tool_call_id": tool_call.id,
"role": "tool",
"name": function_name,
"content": str(function_response),
}
)
second_response = self.client.chat.completions.create(
model=self.model,
messages=self.messages,
) #4
response_message = second_response.choices[0].message#1 Proceeds if tool calls are detected in the LLM response #2 Loads pointers to the actual function implementations for code execution #3 Loops through all the calls the LLM wants to call; there can be several. #4 Performs a second LLM call with the results of the tool calls
To demo this, start up Nexus in the debugger by pressing F5. Then, select the two test actions—recommend and get_current_weather—and the terse persona/profile Olly. Figure 7.9 shows the result of entering a query and the agent responding by using both tools in its response.
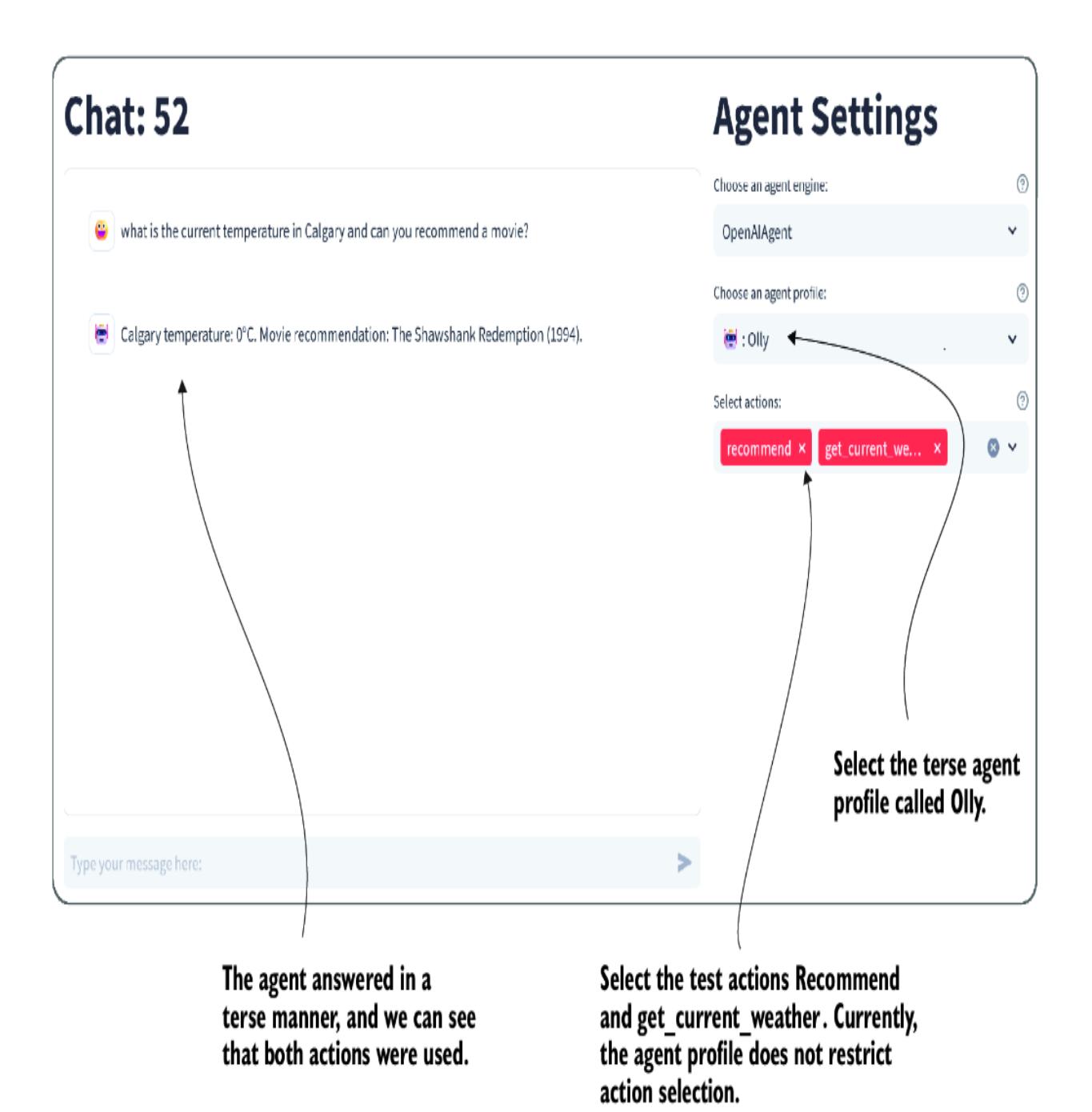

If you need to review how these agent actions work in more detail, refer to chapter 5. The underlying code is more complex and out of the scope of review here. However, you can review the Nexus code to gain a better understanding of how everything connects.
Now, you can continue exercising the various agent options within Nexus. Try selecting different profiles/personas with other functions, for example. In the next chapter, we unveil how agents can consume external memory and knowledge using patterns such as Retrieval Augmented Generation (RAG).
7.6 Exercises
Use the following exercises to improve your knowledge of the material:
Exercise 1—Explore Streamlit Basics (Easy)
Objective —Gain familiarity with Streamlit by creating a simple web application that displays text input by the user.
Tasks:
- Follow the Streamlit documentation to set up a basic application.
- Add a text input and a button. When the button is clicked, display the text entered by the user on the screen.
- Exercise 2—Create a Basic Agent Profile
Objective —Understand the process of creating and applying agent profiles in Nexus.
Tasks:
- Create a new agent profile with a unique persona. This persona should have a specific theme or characteristic (e.g., a historian).
- Define a basic set of responses that align with this persona.
- Test the persona by interacting with it through the Nexus interface.
- Exercise 3—Develop a Custom Action
Objective —Learn to extend the functionality of Nexus by developing a custom action.
Tasks:
- Develop a new action (e.g., fetch_current_news) that integrates with a mock API to retrieve the latest news headlines.
- Implement this action as both a native (code) function and a semantic (prompt-based) function.
- Test the action in the Nexus environment to ensure it works as expected.
- Exercise 4 —Integrate a Third-Party API
Objective —Enhance the capabilities of a Nexus agent by integrating a real third-party API.
Tasks:
- Choose a public API (e.g., weather or news API), and create a new action that fetches data from this API.
- Incorporate error handling and ensure that the agent can gracefully handle API failures or unexpected responses.
- Test the integration thoroughly within Nexus.
Summary
Nexus is an open source agent development platform used in conjunction with this book. It’s designed to develop, test, and host AI agents and is built on Streamlit for creating interactive dashboards and chat interfaces.
Streamlit, a Python web application framework, enables the rapid development of user-friendly dashboards and chat applications. This framework facilitates the exploration and interaction with various agent features in a streamlined manner.
Nexus supports creating and customizing agent profiles and personas, allowing users to define their agents’ personalities and behaviors. These profiles dictate how agents interact with and respond to user inputs.
The Nexus platform allows for developing and integrating semantic (prompt-based) and native (code-based) actions and tools within agents. This enables the creation of highly functional and responsive agents.
As an open source platform, Nexus is designed to be extensible, encouraging contributions and the addition of new features, tools, and agent capabilities by the community.
Nexus is flexible, supporting various deployment options, including a web interface, API, and a Discord bot in future iterations, accommodating a wide range of development and testing needs.
8 Understanding agent memory and knowledge
This chapter covers
- Retrieval in knowledge/memory in AI functions
- Building retrieval augmented generation workflows with LangChain
- Retrieval augmented generation for agentic knowledge systems in Nexus
- Retrieval patterns for memory in agents
- Improving augmented retrieval systems with memory and knowledge compression
Now that we’ve explored agent actions using external tools, such as plugins in the form of native or semantic functions, we can look at the role of memory and knowledge using retrieval in agents and chat interfaces. We’ll describe memory and knowledge and how they relate to prompt engineering strategies, and then, to understand memory knowledge, we’ll investigate document indexing, construct retrieval systems with LangChain, use memory with LangChain, and build semantic memory using Nexus.
8.1 Understanding retrieval in AI applications
Retrieval in agent and chat applications is a mechanism for obtaining knowledge to keep in storage that is typically external and long-lived. Unstructured knowledge includes conversation or task histories, facts, preferences, or other items necessary for contextualizing a prompt. Structured knowledge, typically stored in databases or files, is accessed through native functions or plugins.
Memory and knowledge, as shown in figure 8.1, are elements used to add further context and relevant information to a prompt. Prompts can be
augmented with everything from information about a document to previous tasks or conversations and other reference information.
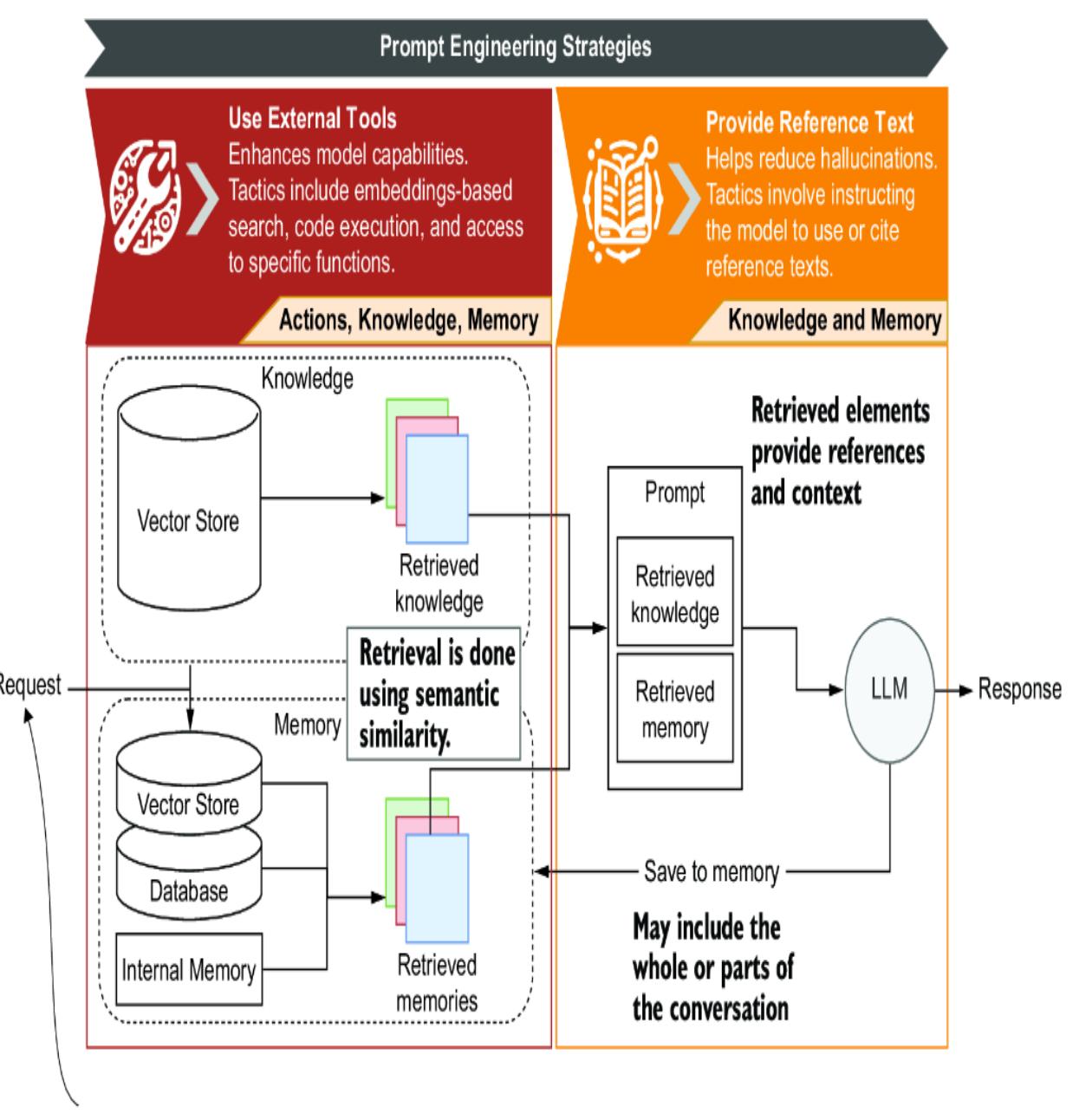
Figure 8.1 Memory, retrieval, and augmentation of the prompt using the following prompt engineering strategies: Use External Tools and Provide Reference Text.
The prompt engineering strategies shown in figure 8.1 can be applied to memory and knowledge. Knowledge isn’t considered memory but rather an augmentation of the prompt from existing documents. Both knowledge and memory use retrieval as the basis for how unstructured information can be queried.
The retrieval mechanism, called retrieval augmented generation (RAG), has become a standard for providing relevant context to a prompt. The exact mechanism that powers RAG also powers memory/knowledge, and it’s essential to understand how it works. In the next section, we’ll examine what RAG is.
8.2 The basics of retrieval augmented generation (RAG)
RAG has become a popular mechanism for supporting document chat or question-and-answer chat. The system typically works by a user supplying a relevant document, such as a PDF, and then using RAG and a large language model (LLM) to query the document.
Figure 8.2 shows how RAG can allow a document to be queried using an LLM. Before any document can be queried, it must first be loaded, transformed into context chunks, embedded into vectors, and stored in a vector database.
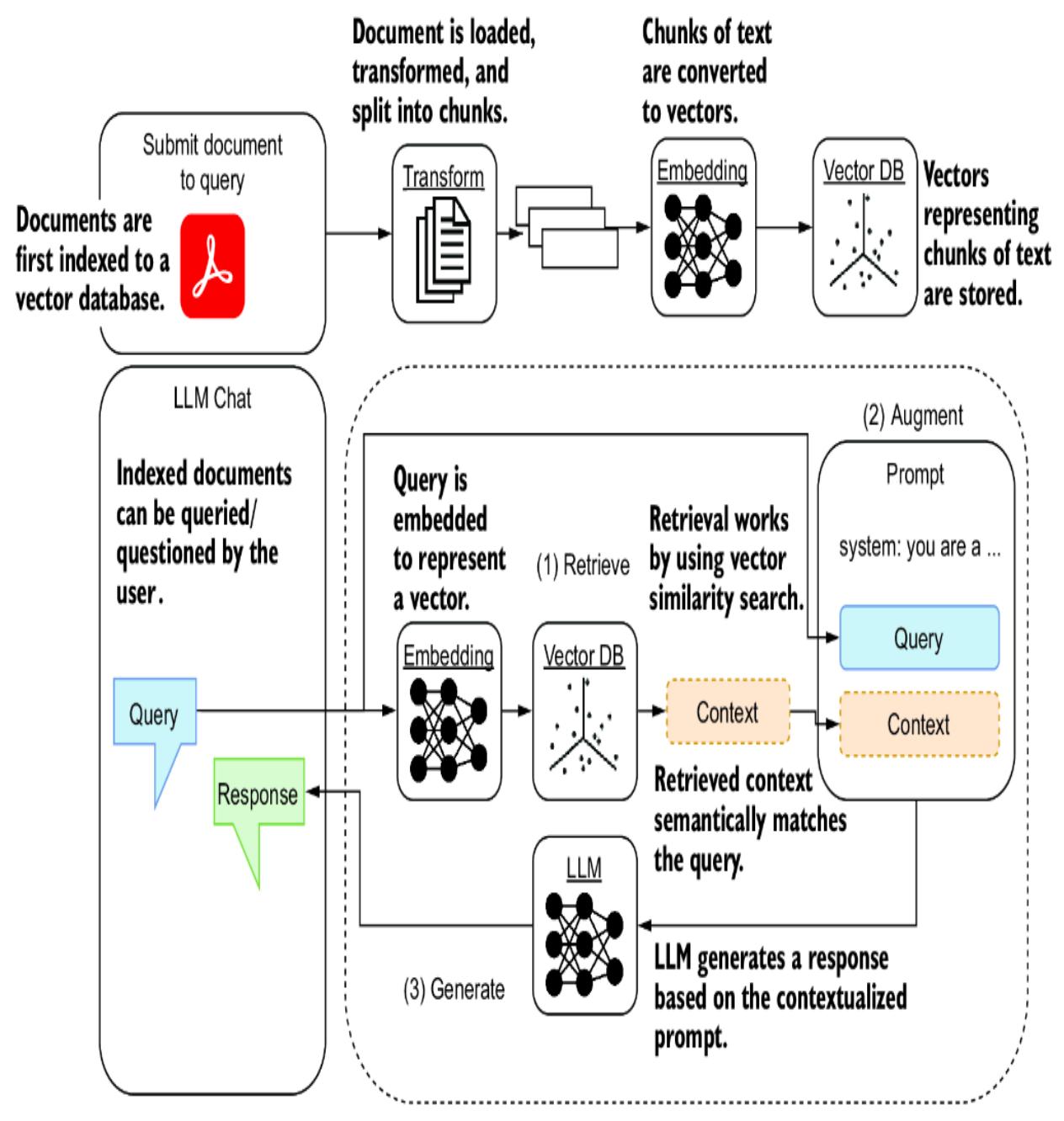
Figure 8.2 The two phases of RAG: first, documents must be loaded, transformed, embedded, and stored, and, second, they can be queried using augmented generation.
A user can query previously indexed documents by submitting a query. That query is then embedded into a vector representation to search for similar chunks in the vector database. Content similar to the query is then used as context and populated into the prompt as augmentation. The
prompt is pushed to an LLM, which can use the context information to help answer the query.
Unstructured memory/knowledge concepts rely on some format of textsimilarity search following the retrieval pattern shown in figure 8.2. Figure 8.3 shows how memory uses the same embedding and vector database components. Rather than preload documents, conversations or parts of a conversation are embedded and saved to a vector database.
Figure 8.3 Memory retrieval for augmented generation uses the same embedding patterns to index items to a vector database.
The retrieval pattern and document indexing are nuanced and require careful consideration to be employed successfully. This requires
understanding how data is stored and retrieved, which we’ll start to unfold in the next section.
8.3 Delving into semantic search and document indexing
Document indexing transforms a document’s information to be more easily recovered. How the index will be queried or searched also plays a factor, whether searching for a particular set of words or wanting to match phrase for phrase.
A semantic search is a search for content that matches the searched phrase by words and meaning. The ability to search by meaning, semantically, is potent and worth investigating in some detail. In the next section, we look at how vector similarity search can lay the framework for semantic search.
8.3.1 Applying vector similarity search
Let’s look now at how a document can be transformed into a semantic vector, or a representation of text that can then be used to perform distance or similarity matching. There are numerous ways to convert text into a semantic vector, so we’ll look at a simple one.
Open the chapter_08 folder in a new Visual Studio Code (VS Code) workspace. Create a new environment and pip install the requirements.txt file for all the chapter dependencies. If you need help setting up a new Python environment, consult appendix B.
Now open the document_vector_similarity.py file in VS Code, and review the top section in listing 8.1. This example uses Term Frequency– Inverse Document Frequency (TF–IDF). This numerical statistic reflects how important a word is to a document in a collection or set of documents by increasing proportionally to the number of times a word appears in the document and offset by the frequency of the word in the document set. TF– IDF is a classic measure of understanding one document’s importance within a set of documents.
Listing 8.1 document_vector_similarity (transform to vector)
import plotly.graph_objects as go from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity documents = [ #1 “The sky is blue and beautiful.”, “Love this blue and beautiful sky!”, “The quick brown fox jumps over the lazy dog.”, “A king’s breakfast has sausages, ham, bacon, eggs, toast, and beans”, “I love green eggs, ham, sausages and bacon!”, “The brown fox is quick and the blue dog is lazy!”, “The sky is very blue and the sky is very beautiful today”, “The dog is lazy but the brown fox is quick!” ] vectorizer = TfidfVectorizer() #2 X = vectorizer.fit_transform(documents) #3 #1 Samples of documents #2 Vectorization using TF–IDF
#3 Vectorize the documents.
Let’s break down TF–IDF into its two components using the sample sentence, “The sky is blue and beautiful,” and focusing on the word blue.
TERM FREQUENCY (TF)
Term Frequency measures how frequently a term occurs in a document. Because we’re considering only a single document (our sample sentence), the simplest form of the TF for blue can be calculated as the number of times blue appears in the document divided by the total number of words in the document. Let’s calculate it:
Number of times blue appears in the document: 1
Total number of words in the document: 6
TF = 1 ÷ 6TF = .16
INVERSE DOCUMENT FREQUENCY (IDF)
Inverse Document Frequency measures how important a term is within the entire corpus. It’s calculated by dividing the total number of documents by the number of documents containing the term and then taking the logarithm of that quotient:
IDF = log(Total number of documents ÷ Number of documents containing the word)
In this example, the corpus is a small collection of eight documents, and blue appears in four of these documents.
IDF = log(8 ÷ 4)
TF–IDF CALCULATION
Finally, the TF–IDF score for blue in our sample sentence is calculated by multiplying the TF and the IDF scores:
TF–IDF = TF × IDF
Let’s compute the actual values for TF–IDF for the word blue using the example provided; first, the term frequency (how often the word occurs in the document) is computed as follows:
TF = 1 ÷ 6
Assuming the base of the logarithm is 10 (commonly used), the inverse document frequency is computed as follows:
IDF = log10 (8 ÷ 4)
Now let’s calculate the exact TF–IDF value for the word blue in the sentence, “The sky is blue and beautiful”:
The Term Frequency (TF) is approximately 0.1670.
The Inverse Document Frequency (IDF) is approximately 0.301.
Thus, the TF–IDF (TF × IDF) score for blue is approximately 0.050.
This TF–IDF score indicates the relative importance of the word blue in the given document (the sample sentence) within the context of the specified corpus (eight documents, with blue appearing in four of them). Higher TF–IDF scores imply greater importance.
We use TF–IDF here because it’s simple to apply and understand. Now that we have the elements represented as vectors, we can measure document similarity using cosine similarity. Cosine similarity is a measure used to calculate the cosine of the angle between two nonzero vectors in a multidimensional space, indicating how similar they are, irrespective of their size.
Figure 8.4 shows how cosine distance compares the vector representations of two pieces or documents of text. Cosine similarity returns a value from –1 (not similar) to 1 (identical). Cosine distance is a normalized value ranging from 0 to 2, derived by taking 1 minus the cosine similarity. A cosine distance of 0 means identical items, and 2 indicates complete opposites.

Figure 8.4 How cosine similarity is measured
Listing 8.2 shows how the cosine similarities are computed using the cosine_similarity function from scikit-learn. Similarities are calculated for each document against all other documents in the set. The computed matrix of similarities for documents is stored in the cosine_similarities variable. Then, in the input loop, the user can select the document to view its similarities to the other documents.
Listing 8.2 document_vector_similarity (cosine similarity)
cosine_similarities = cosine_similarity(X) #1
while True: #2
selected_document_index = input(f"Enter a document number
↪ (0-{len(documents)-1}) or 'exit' to quit: ").strip()
if selected_document_index.lower() == 'exit':
break
if not selected_document_index.isdigit() or
↪ not 0 <= int(selected_document_index) < len(documents):
print("Invalid input. Please enter a valid document number.")
continue
selected_document_index = int(selected_document_index) #3
selected_document_similarities = cosine_similarities[selected_document_index]
#4
# code to plot document similarities omitted
#1 Computes the document similarities for all vector pairs
#2 The main input loop
#3 Gets the selected document index to compare with#4 Extracts the computed similarities against all documentsFigure 8.5 shows the output of running the sample in VS Code (F5 for debugging mode). After you select a document, you’ll see the similarities between the various documents in the set. A document will have a cosine similarity of 1 with itself. Note that you won’t see a negative similarity because of the TF–IDF vectorization. We’ll look later at other, more sophisticated means of measuring semantic similarity.
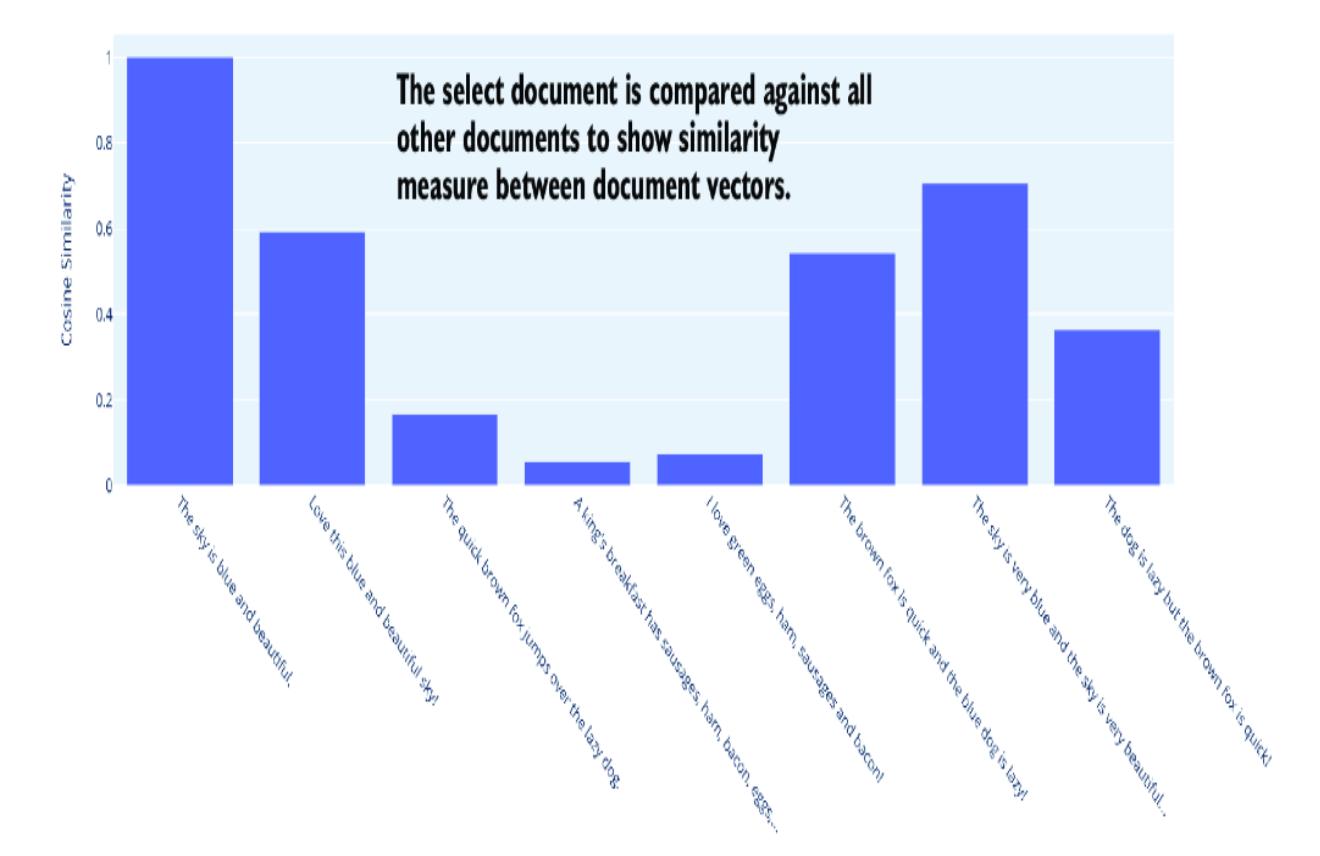
Figure 8.5 The cosine similarity between selected documents and the document set
The method of vectorization will dictate the measure of semantic similarity between documents. Before we move on to better methods of vectorizing documents, we’ll examine storing vectors to perform vector similarity searches.
8.3.2 Vector databases and similarity search
After vectorizing documents, they can be stored in a vector database for later similarity searches. To demonstrate how this works, we can efficiently replicate a simple vector database in Python code.
Open document_vector_database.py in VS Code, as shown in listing 8.3. This code demonstrates creating a vector database in memory and then allowing users to enter text to search the database and return results. The results returned show the document text and the similarity score.
Listing 8.3 document_vector_database.py
# code above omitted
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(documents)
vector_database = X.toarray() #1
def cosine_similarity_search(query,
database,
vectorizer,
top_n=5): #2
query_vec = vectorizer.transform([query]).toarray()
similarities = cosine_similarity(query_vec, database)[0]
top_indices = np.argsort(-similarities)[:top_n] # Top n indices
return [(idx, similarities[idx]) for idx in top_indices]
while True: #3
query = input("Enter a search query (or 'exit' to stop): ")
if query.lower() == 'exit':
break
top_n = int(input("How many top matches do you want to see? "))
search_results = cosine_similarity_search(query,
vector_database,
vectorizer,
top_n)
print("Top Matched Documents:")
for idx, score in search_results:
print(f"- {documents[idx]} (Score: {score:.4f})") #4
print("\n")
###Output
Enter a search query (or 'exit' to stop): blue
How many top matches do you want to see? 3
Top Matched Documents:
- The sky is blue and beautiful. (Score: 0.4080)
- Love this blue and beautiful sky! (Score: 0.3439)
- The brown fox is quick and the blue dog is lazy! (Score: 0.2560)#1 Stores the document vectors into an array #2 The function to perform similarity matching on query returns, matches, and similarity scores #3 The main input loop #4 Loops through results and outputs text and similarity score
Run this exercise to see the output (F5 in VS Code). Enter any text you like, and see the results of documents being returned. This search form works well for matching words and phrases with similar words and phrases. This form of search misses the word context and meaning from the document. In the next section, we’ll look at a way of transforming documents into vectors that better preserves their semantic meaning.
8.3.3 Demystifying document embeddings
TF–IDF is a simple form that tries to capture semantic meaning in documents. However, it’s unreliable because it only counts word frequency and doesn’t understand the relationships between words. A better and more modern method uses document embedding, a form of document vectorizing that better preserves the semantic meaning of the document.
Embedding networks are constructed by training neural networks on large datasets to map words, sentences, or documents to high-dimensional vectors, capturing semantic and syntactic relationships based on context and relationships in the data. You typically use a pretrained model trained on massive datasets to embed documents and perform embeddings. Models are available from many sources, including Hugging Face and, of course, OpenAI.
In our next scenario, we’ll use an OpenAI embedding model. These models are typically perfect for capturing the semantic context of embedded documents. Listing 8.4 shows the relevant code that uses OpenAI to embed the documents into vectors that are then reduced to three dimensions and rendered into a plot.
Listing 8.4 document_visualizing_embeddings.py (relevant sections)
load_dotenv() #1
api_key = os.getenv('OPENAI_API_KEY')
if not api_key:
raise ValueError("No API key found. Please check your .env file.")
client = OpenAI(api_key=api_key) #1
def get_embedding(text, model="text-embedding-ada-002"): #2
text = text.replace("\n", " ")
return client.embeddings.create(input=[text],
model=model).data[0].embedding #2
# Sample documents (omitted)
embeddings = [get_embedding(doc) for doc in documents] #3
print(embeddings_array.shape)
embeddings_array = np.array(embeddings) #4
pca = PCA(n_components=3) #5
reduced_embeddings = pca.fit_transform(embeddings_array)
#1 Join all the items on the string ', '.
#2 Uses the OpenAI client to create the embedding#3 Generates embeddings for each document of size 1536 dimensions
#4 Converts embeddings to a NumPy array for PCA#5 Applies PCA to reduce dimensions to 3 for plottingWhen a document is embedded using an OpenAI model, it transforms the text into a vector with dimensions of 1536. We can’t visualize this number of dimensions, so we use a dimensionality reduction technique via principal component analysis (PCA) to convert the vector of size 1536 to 3 dimensions.
Figure 8.6 shows the output generated from running the file in VS Code. By reducing the embeddings to 3D, we can plot the output to show how semantically similar documents are now grouped.
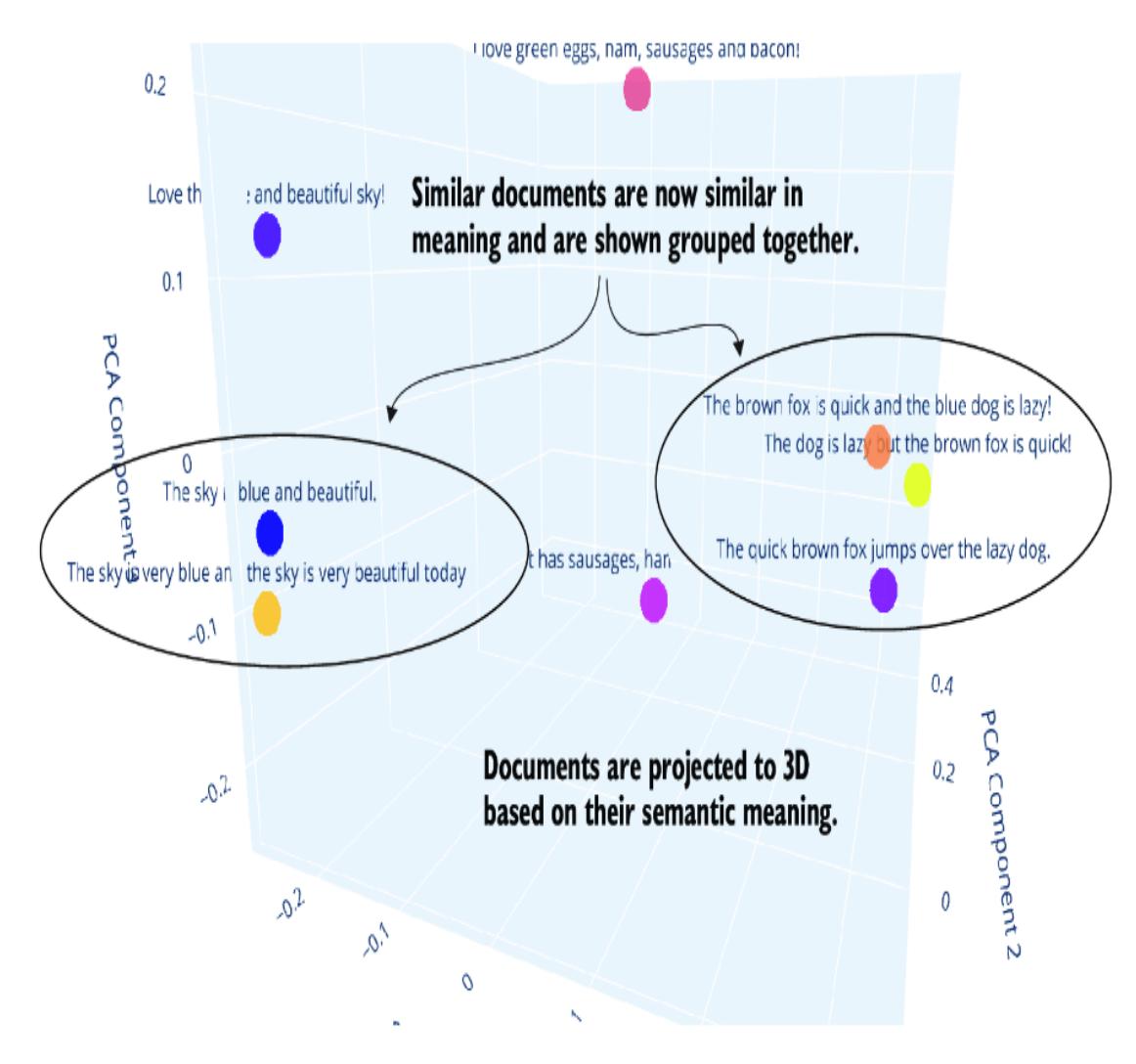
Figure 8.6 Embeddings in 3D, showing how similar semantic documents are grouped
The choice of which embedding model or service you use is up to you. The OpenAI embedding models are considered the best for general semantic similarity. This has made these models the standard for most memory and retrieval applications. With our understanding of how text can be vectorized with embeddings and stored in a vector database, we can move on to a more realistic example in the next section.
8.3.4 Querying document embeddings from Chroma
We can combine all the pieces and look at a complete example using a local vector database called Chroma DB. Many vector database options exist, but Chroma DB is an excellent local vector store for development or small-scale projects. There are also plenty of more robust options that you can consider later.
Listing 8.5 shows the new and relevant code sections from the document_query_ chromadb.py file. Note that the results are scored by distance and not by similarity. Cosine distance is determined by this equation:
Cosine Distance(A,B) = 1 – Cosine Similarity(A,B)
This means that cosine distance will range from 0 for most similar to 2 for semantically opposite in meaning.
Listing 8.5 document_query_chromadb.py (relevant code sections)
embeddings = [get_embedding(doc) for doc in documents] #1
ids = [f"id{i}" for i in range(len(documents))] #1
chroma_client = chromadb.Client() #2
collection = chroma_client.create_collection(
name="documents") #2
collection.add( #3
embeddings=embeddings,
documents=documents,
ids=ids
)
def query_chromadb(query, top_n=2): #4
query_embedding = get_embedding(query)
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_n
)
return [(id, score, text) for id, score, text in
zip(results['ids'][0],
results['distances'][0],
results['documents'][0])]
while True: #5
query = input("Enter a search query (or 'exit' to stop): ")
if query.lower() == 'exit':
break
top_n = int(input("How many top matches do you want to see? "))
search_results = query_chromadb(query, top_n)
print("Top Matched Documents:")
for id, score, text in search_results:
print(f"""
ID:{id} TEXT: {text} SCORE: {round(score, 2)}
""") #5
print("\n")
###Output
Enter a search query (or 'exit' to stop): dogs are lazy
How many top matches do you want to see? 3
Top Matched Documents:
ID:id7 TEXT: The dog is lazy but the brown fox is quick! SCORE: 0.24
ID:id5 TEXT: The brown fox is quick and the blue dog is lazy! SCORE: 0.28
ID:id2 TEXT: The quick brown fox jumps over the lazy dog. SCORE: 0.29
#1 Generates embeddings for each document and assigns an ID
#2 Creates a Chroma DB client and a collection
#3 Adds document embeddings to the collection
#4 Queries the datastore and returns the top n relevant documents#5 The input loop for user input and output of relevant documents/scores
As the earlier scenario demonstrated, you can now query the documents using semantic meaning rather than just key terms or phrases. These scenarios should now provide the background to see how the retrieval
pattern works at a low level. In the next section, we’ll see how the retrieval pattern can be employed using LangChain.
8.4 Constructing RAG with LangChain
LangChain began as an open source project specializing in abstracting the retrieval pattern across multiple data sources and vector stores. It has since morphed into much more, but foundationally, it still provides excellent options for implementing retrieval.
Figure 8.7 shows a diagram from LangChain that identifies the process of storing documents for retrieval. These same steps may be replicated in whole or in part to implement memory retrieval. The critical difference between document and memory retrieval is the source and how content is transformed.
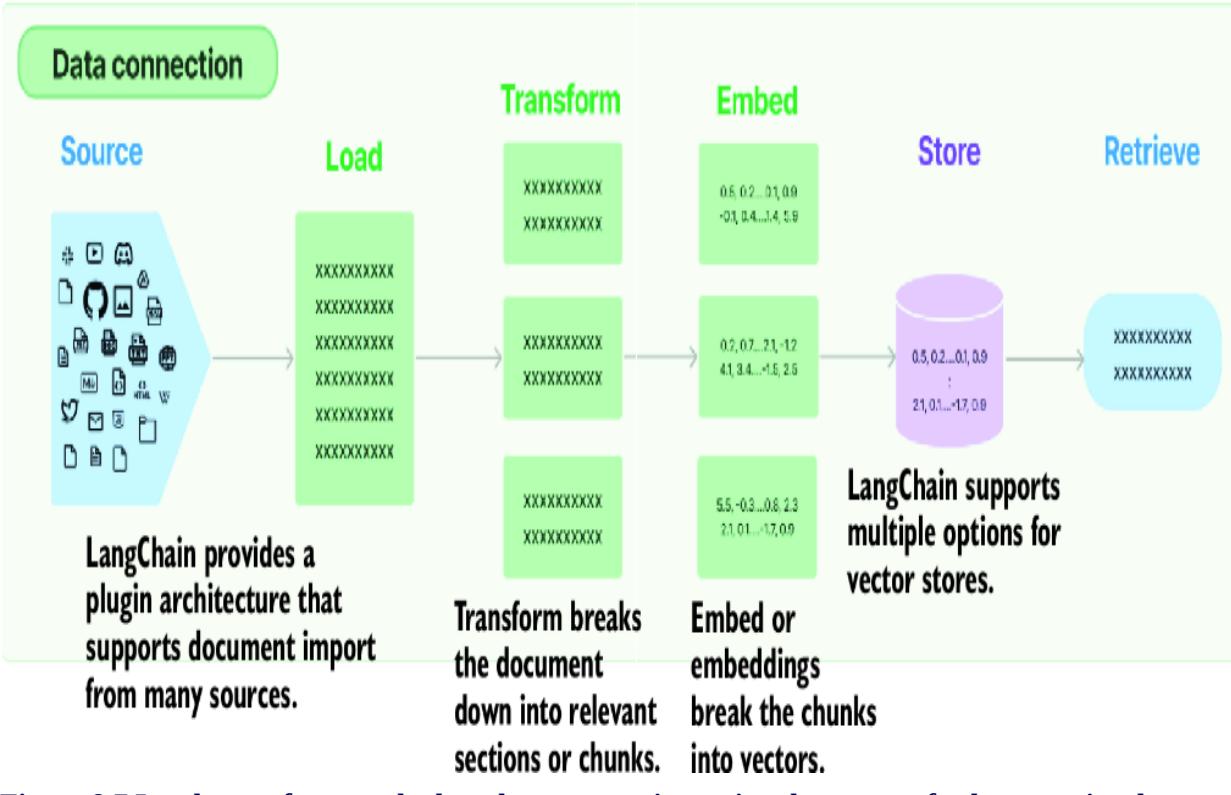
Figure 8.7 Load, transform, embed, and store steps in storing documents for later retrieval
We’ll examine how to implement each of these steps using LangChain and understand the nuances and details accompanying this implementation. In
the next section, we’ll start by splitting and loading documents with LangChain.
8.4.1 Splitting and loading documents with LangChain
Retrieval mechanisms augment the context of a given prompt with specific information relevant to the request. For example, you may request detailed information about a local document. With earlier language models, submitting the whole document as part of the prompt wasn’t an option due to token limitations.
Today, we could submit a whole document for many commercial LLMs, such as GPT-4 Turbo, as part of a prompt request. However, the results may not be better and would likely cost more because of the increased number of tokens. Therefore, a better option is to split the document and use the relevant parts to request context—precisely what RAG and memory do.
Splitting a document is essential in breaking down content into semantically and specifically relevant sections. Figure 8.8 shows how to break down an HTML document containing the Mother Goose nursery rhymes. Often, splitting a document into contextual semantic chunks requires careful consideration.
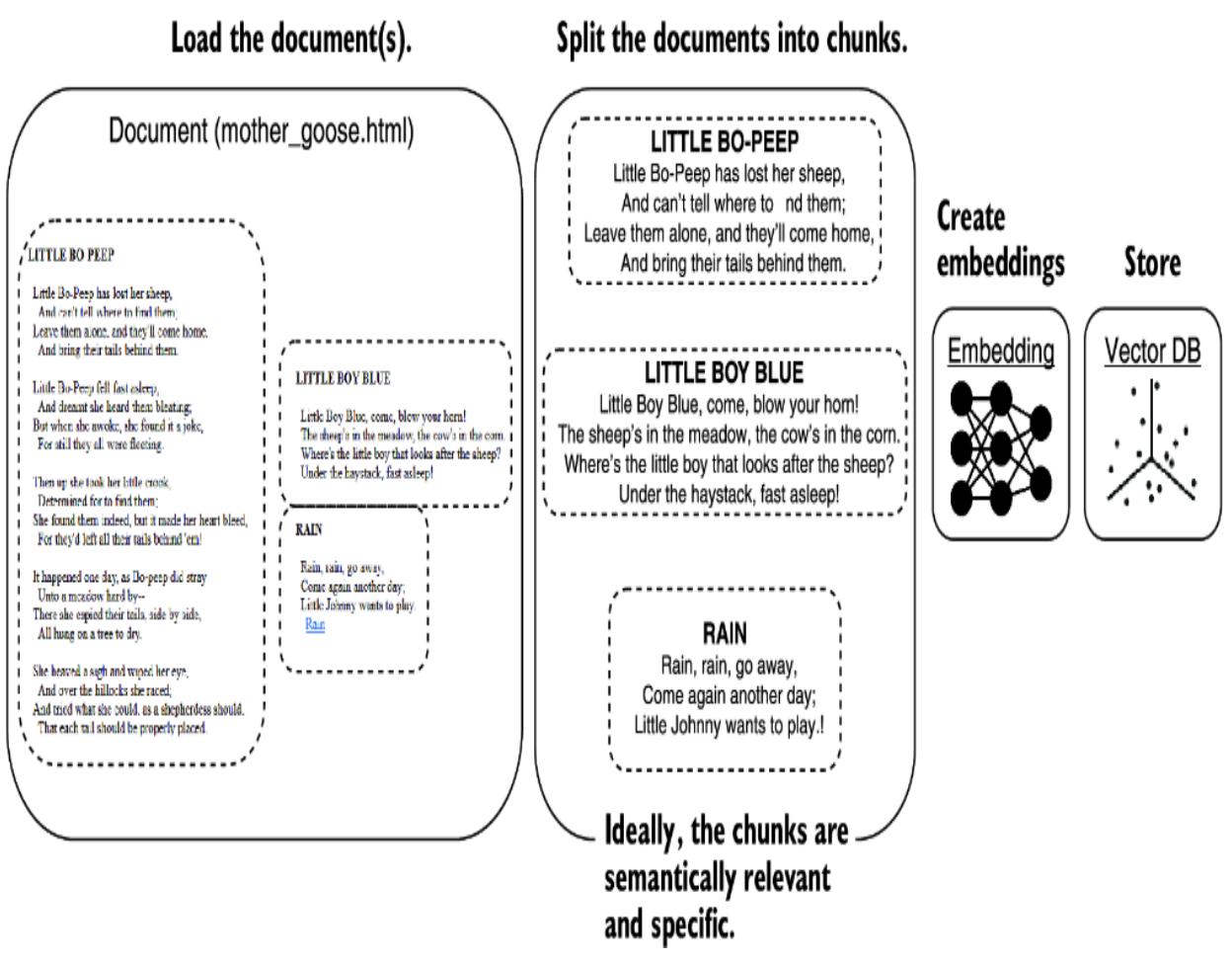
Figure 8.8 How the document would ideally be split into chunks for better semantic and contextual meaning
Ideally, when we split documents into chunks, they are broken down by relevance and semantic meaning. While an LLM or agent could help us with this, we’ll look at current toolkit options within LangChain for splitting documents. Later in this chapter, we’ll look at a semantic function that can assist us in semantically dividing content for embeddings.
For the next exercise, open langchain_load_splitting.py in VS Code, as shown in listing 8.6. This code shows where we left off from listing 8.5, in the previous section. Instead of using the sample documents, we’re loading the Mother Goose nursery rhymes this time.
Listing 8.6 langchain_load_splitting.py (sections and output)
From langchain_community.document_loaders
↪ import UnstructuredHTMLLoader #1
from langchain.text_splitter import RecursiveCharacterTextSplitter
#previous code
loader = UnstructuredHTMLLoader(
"sample_documents/mother_goose.xhtml") #2
data = loader.load #3
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=25, #4
length_function=len,
add_start_index=True,
)
documents = text_splitter.split_documents(data)
documents = [doc.page_content
↪ for doc in documents] [100:350] #5
embeddings = [get_embedding(doc) for doc in documents] #6
ids = [f"id{i}" for i in range(len(documents))]
###Output
Enter a search query (or 'exit' to stop): who kissed the girls and made
them cry?
How many top matches do you want to see? 3
Top Matched Documents:
ID:id233 TEXT: And chid her daughter,
And kissed my sister instead of me. SCORE: 0.4…
#1 New LangChain imports
#2 Loads the document as HTML
#3 Loads the document#4 Splits the document into blocks of text 100 characters long with a 25-character overlap #5 Embeds only 250 chunks, which is cheaper and faster #6 Returns the embedding for each document
Note in listing 8.6 that the HTML document gets split into 100-character chunks with a 25-character overlap. The overlap allows the document’s parts not to cut off specific thoughts. We selected the splitter for this exercise because it was easy to use, set up, and understand.
Go ahead and run the langchain_load_splitting.py file in VS Code (F5). Enter a query, and see what results you get. The output in listing 8.6 shows good results given a specific example. Remember that we only embedded 250 document chunks to reduce costs and keep the exercise short. Of course, you can always try to embed the entire document or use a minor input document example.
Perhaps the most critical element to building proper retrieval is the process of document splitting. You can use numerous methods to split a document, including multiple concurrent methods. More than one method passes and splits the document for numerous embedding views of the same document. In the next section, we’ll examine a more general technique for splitting documents, using tokens and tokenization.
8.4.2 Splitting documents by token with LangChain
Tokenization is the process of breaking text into word tokens. Where a word token represents a succinct element in the text, a token could be a word like hold or even a symbol like the left curly brace ({), depending on what’s relevant.
Splitting documents using tokenization provides a better base for how the text will be interpreted by language models and for semantic similarity. Tokenization also allows the removal of irrelevant characters, such as whitespace, making the similarity matching of documents more relevant and generally providing better results.
For the next code exercise, open the langchain_token_splitting.py file in VS Code, as shown in listing 8.7. Now we split the document using tokenization, which breaks the document into sections of unequal size. The unequal size results from the large sections of whitespace of the original document.
Listing 8.7 langchain_token_splitting.py (relevant new code)
loader = UnstructuredHTMLLoader("sample_documents/mother_goose.xhtml")
data = loader.load()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=50, chunk_overlap=10 #1
)
documents = text_splitter.split_documents(data)
documents = [doc for doc in documents][8:94] #2
db = Chroma.from_documents(documents, OpenAIEmbeddings())
def query_documents(query, top_n=2):
docs = db.similarity_search(query, top_n) #3
return docs
###Output
Created a chunk of size 68,
which is longer than the specified 50
Created a chunk of size 67,
which is longer than the specified 50 #4
Enter a search query (or 'exit' to stop):
who kissed the girls and made them cry?
How many top matches do you want to see? 3
Top Matched Documents:
Document 1: GEORGY PORGY
Georgy Porgy, pudding and pie,
Kissed the girls and made them cry.#1 Updates to 50 tokens and overlap of 10 tokens #2 Selects just the documents that contain rhymes #3 Uses the database’s similarity search #4 Breaks into irregular size chunks because of the whitespace
Run the langchain_token_splitting.py code in VS Code (F5). You can use the query we used last time or your own. Notice how the results are significantly better than the previous exercise. However, the results are still suspect because the query uses several similar words in the same order.
A better test would be to try a semantically similar phrase but one that uses different words and check the results. With the code still running, enter a new phrase to query: Why are the girls crying? Listing 8.8 shows the results of executing that query. If you run this example yourself and scroll down over the output, you’ll see Georgy Porgy appear in either the second or third returned document.
Listing 8.8 Query: Who made the girls cry? Enter a search query (or ‘exit’ to stop): Who made the girls cry? How many top matches do you want to see? 3 Top Matched Documents: Document 1: WILLY, WILLY Willy, Willy Wilkin…
This exercise shows how various retrieval methods can be employed to return documents semantically. With this base established, we can see how RAG can be applied to knowledge and memory systems. The following section will discuss RAG as it applies to knowledge of agents and agentic systems.
8.5 Applying RAG to building agent knowledge
Knowledge in agents encompasses employing RAG to search semantically across unstructured documents. These documents could be anything from PDFs to Microsoft Word documents and all text, including code. Agentic knowledge also includes using unstructured documents for Q&A, reference lookup, information augmentation, and other future patterns.
Nexus, the agent platform developed in tandem with this book and introduced in the previous chapter, employs complete knowledge and memory systems for agents. In this section, we’ll uncover how the knowledge system works.
To install Nexus for just this chapter, see listing 8.9. Open a terminal within the chapter_08 folder, and execute the commands in the listing to download, install, and run Nexus in normal or development mode. If you want to refer to the code, you should install the project in development and configure the debugger to run the Streamlit app from VS Code. Refer to chapter 7 if you need a refresher on any of these steps.
Listing 8.9 Installing Nexus
pip install -e Nexus
to install and run pip install git+https://github.com/cxbxmxcx/Nexus.git nexus run # install in development mode git clone https://github.com/cxbxmxcx/Nexus.git # Install the cloned repository in editable mode
Regardless of which method you decide to run the app in after you log in, navigate to the Knowledge Store Manager page, as shown in figure 8.9. Create a new Knowledge Store, and then upload the
sample_documents/back_to_the_future.txt movie script.
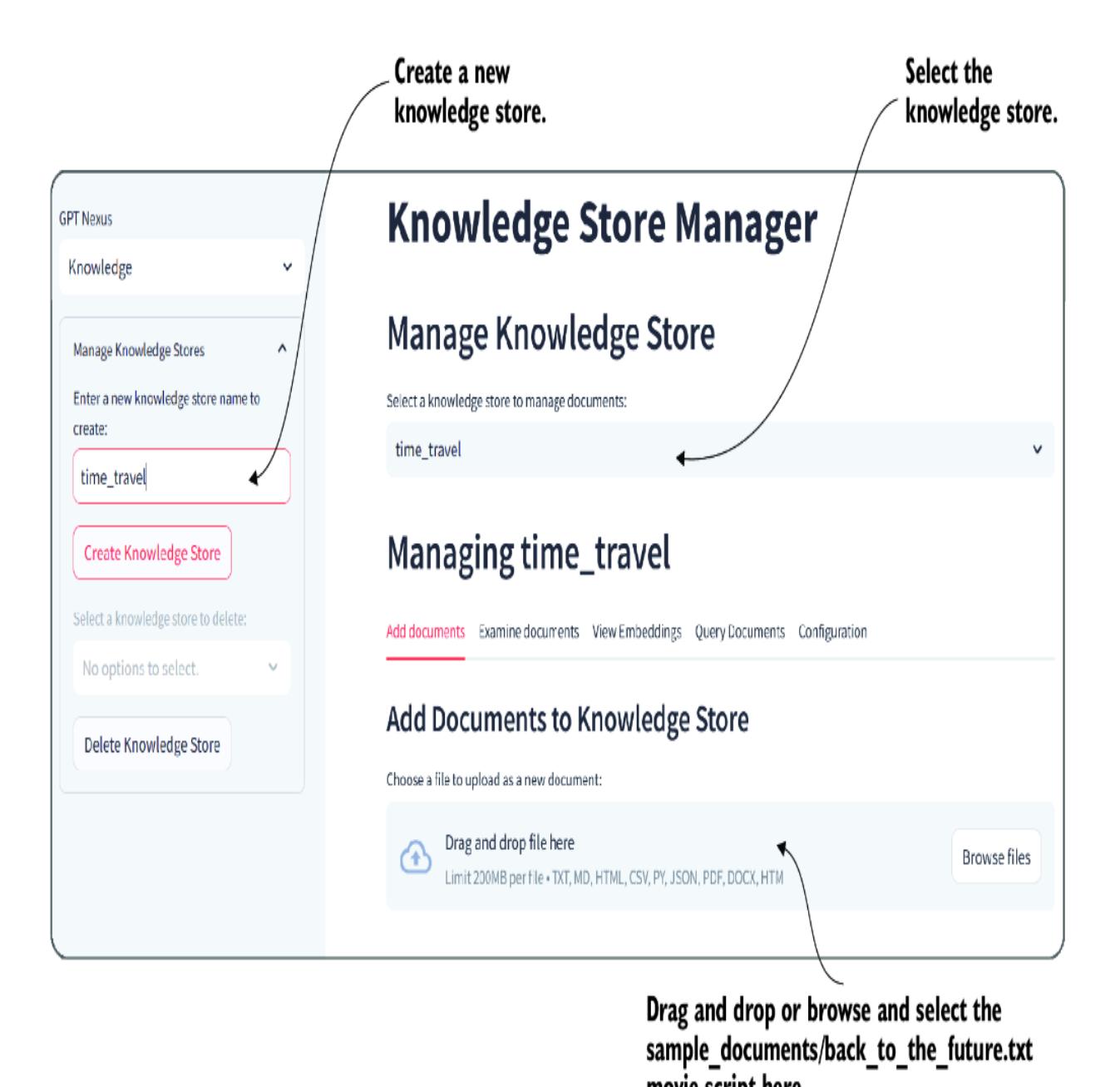
Figure 8.9 Adding a new knowledge store and populating it with a document
The script is a large document, and it may take a while to load, chunk, and embed the parts into the Chroma DB vector database. Wait for the indexing to complete, and then you can inspect the embeddings and run a query, as shown in figure 8.10.
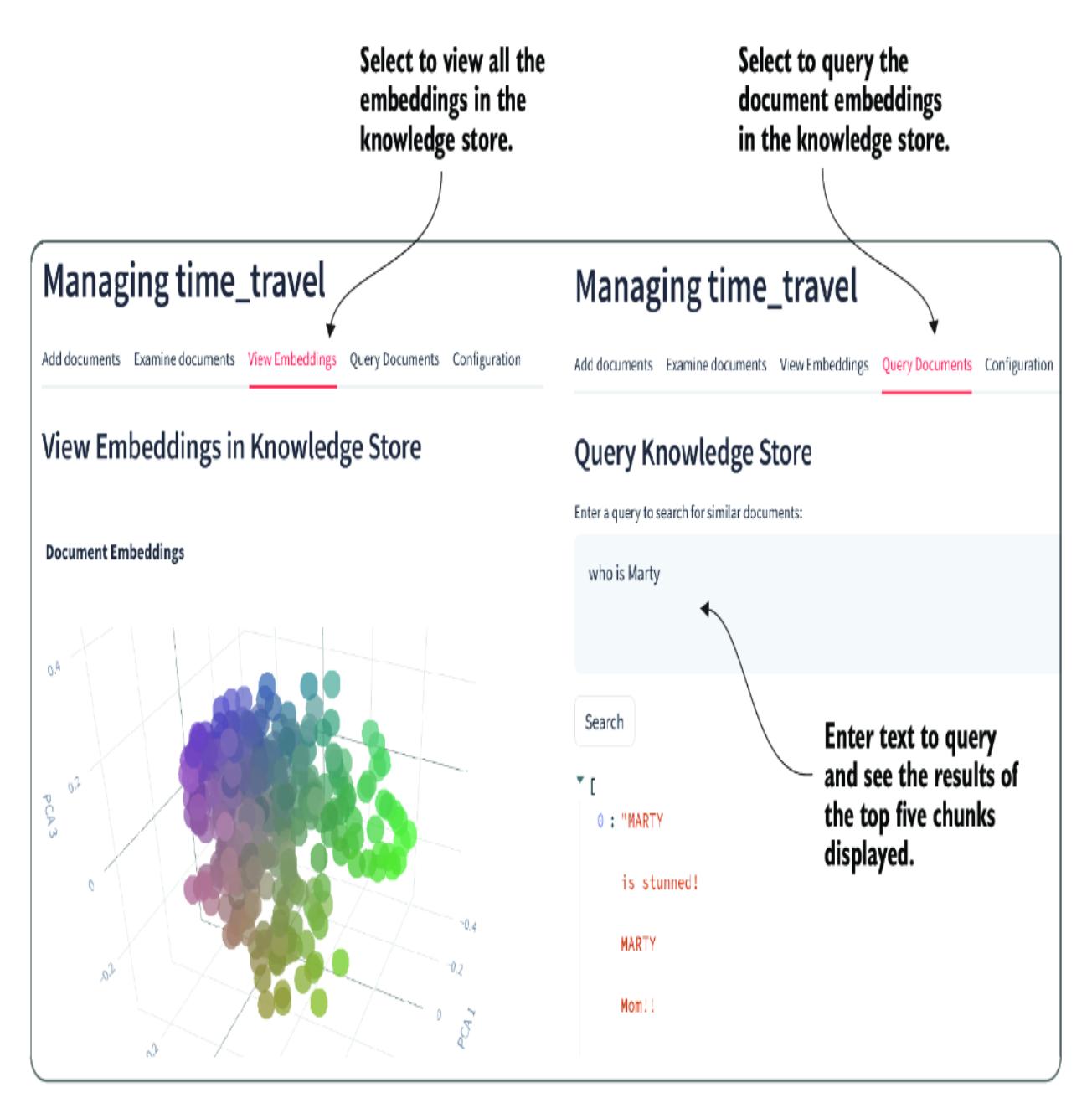

Figure 8.10 The embeddings and document query views
Now, we can connect the knowledge store to a supported agent and ask questions. Use the top-left selector to choose the chat page within the Nexus interface. Then, select an agent and the time_travel knowledge store, as shown in figure 8.11. You will also need to select an agent engine that supports knowledge. Each of the multiple agent engines requires the proper configuration to be accessible.
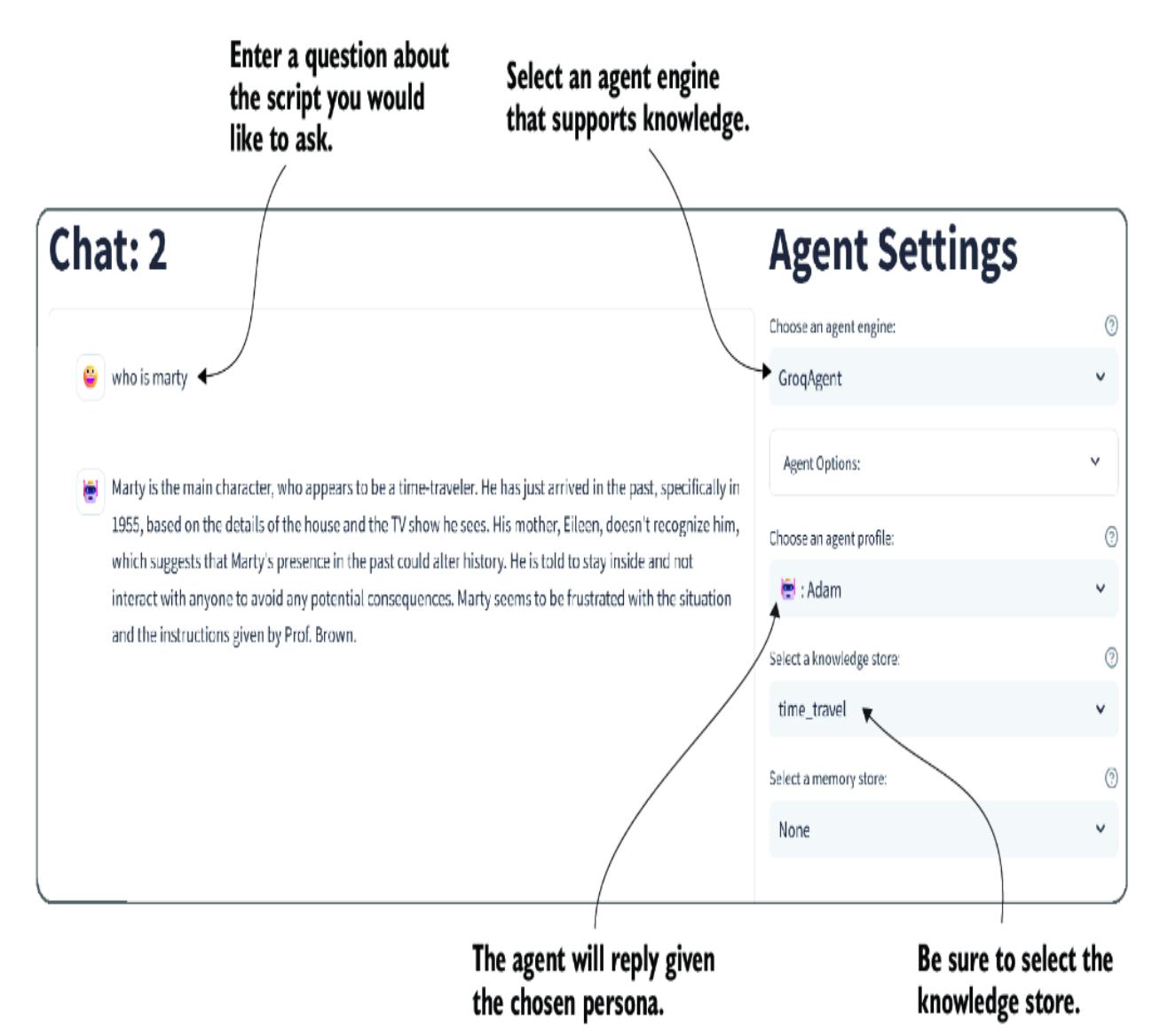
Figure 8.11 Enabling the knowledge store for agent use
Currently, as of this chapter, Nexus supports access to only a single knowledge store at a time. In a future version, agents may be able to select multiple knowledge stores at a time. This may include more advanced options, from semantic knowledge to employing other forms of RAG.
You can also configure the RAG settings within the Configuration tab of the Knowledge Store Manager page, as shown in figure 8.12. As of now, you can select from the type of splitter (Chunking Option field) to chunk the document, along with the Chunk Size field and Overlap field.

Figure 8.12 Managing the knowledge store splitting and chunking options
The loading, splitting, chunking, and embedding options provided are the only basic options supported by LangChain for now. In future versions of Nexus, more options and patterns will be offered. The code to support other options can be added directly to Nexus.
We won’t cover the code that performs the RAG as it’s very similar to what we already covered. Feel free to review the Nexus code, particularly the KnowledgeManager class in the knowledge_manager.py file.
While the retrieval patterns for knowledge and memory are quite similar for augmentation, the two patterns differ when it comes to populating the stores. In the next section, we’ll explore what makes memory in agents unique.
8.6 Implementing memory in agentic systems
Memory in agents and AI applications is often described in the same terms as cognitive memory functions. Cognitive memory describes the type of memory we use to remember what we did 30 seconds ago or how tall we were 30 years ago. Computer memory is also an essential element of agent memory, but one we won’t consider in this section.
Figure 8.13 shows how memory is broken down into sensory, short-term, and long-term memory. This memory can be applied to AI agents, and this list describes how each form of memory maps to agent functions:
- Sensory memory in AI —Functions such as RAG but with images/audio/haptic data forms. Briefly holds input data (e.g., text and images) for immediate processing but not long-term storage.
- Short-term/working memory in AI —Acts as an active memory buffer of conversation history. We’re holding a limited amount of recent input and context for immediate analysis and response generation. Within Nexus, short- and long-term conversational memory is also held in the context of the thread.
- Long-term memory in AI —Longer-term memory storage relevant to the agent’s or user’s life. Semantic memory provides a robust capacity to store and retrieve relevant global or local facts and concepts.
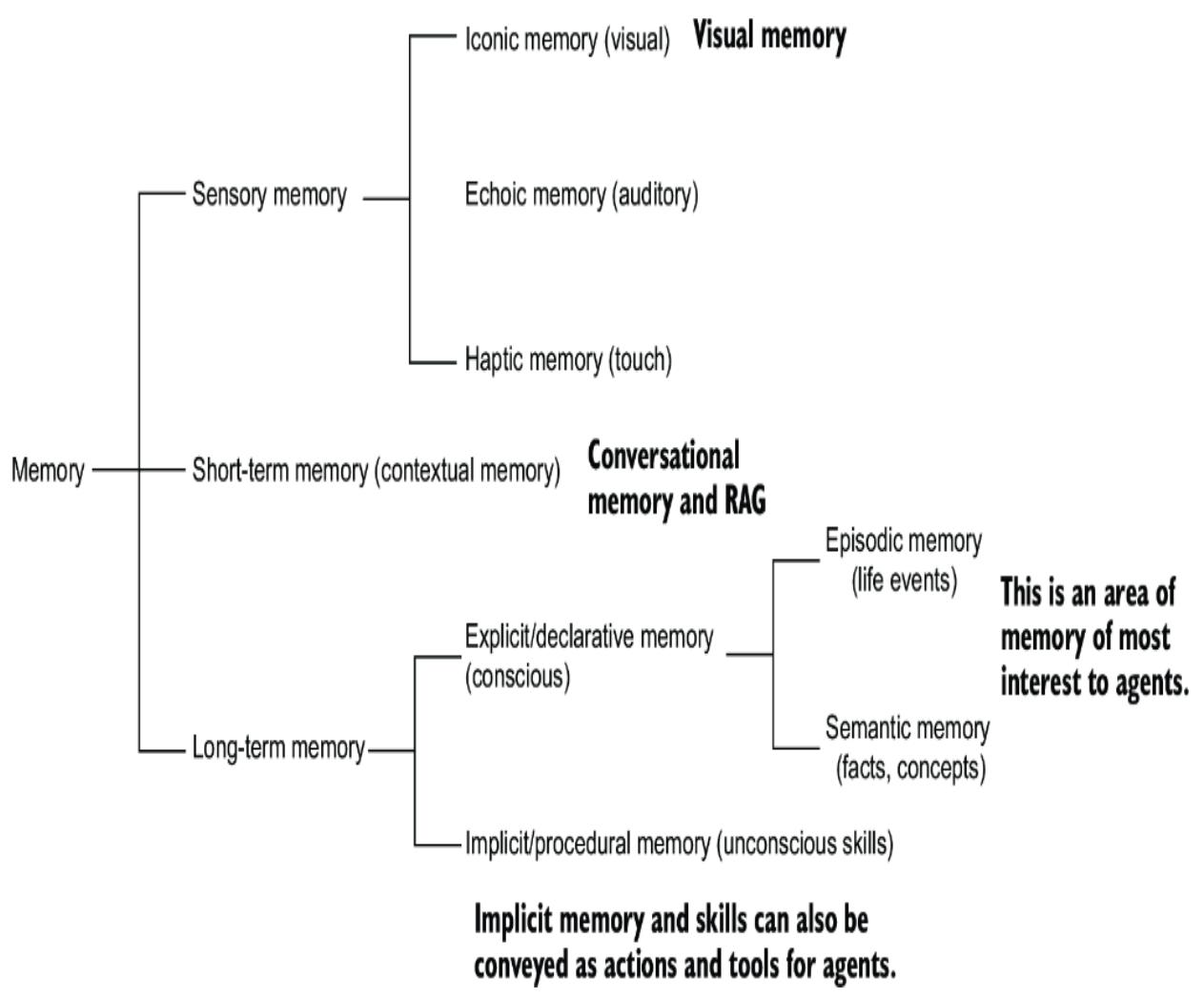
Figure 8.13 How memory is broken down into various forms
While memory uses the exact same retrieval and augmentation mechanisms as knowledge, it typically differs significantly when updating or appending memories. Figure 8.14 highlights the process of capturing and using memories to augment prompts. Because memories are often different from the size of complete documents, we can avoid using any splitting or chunking mechanisms.
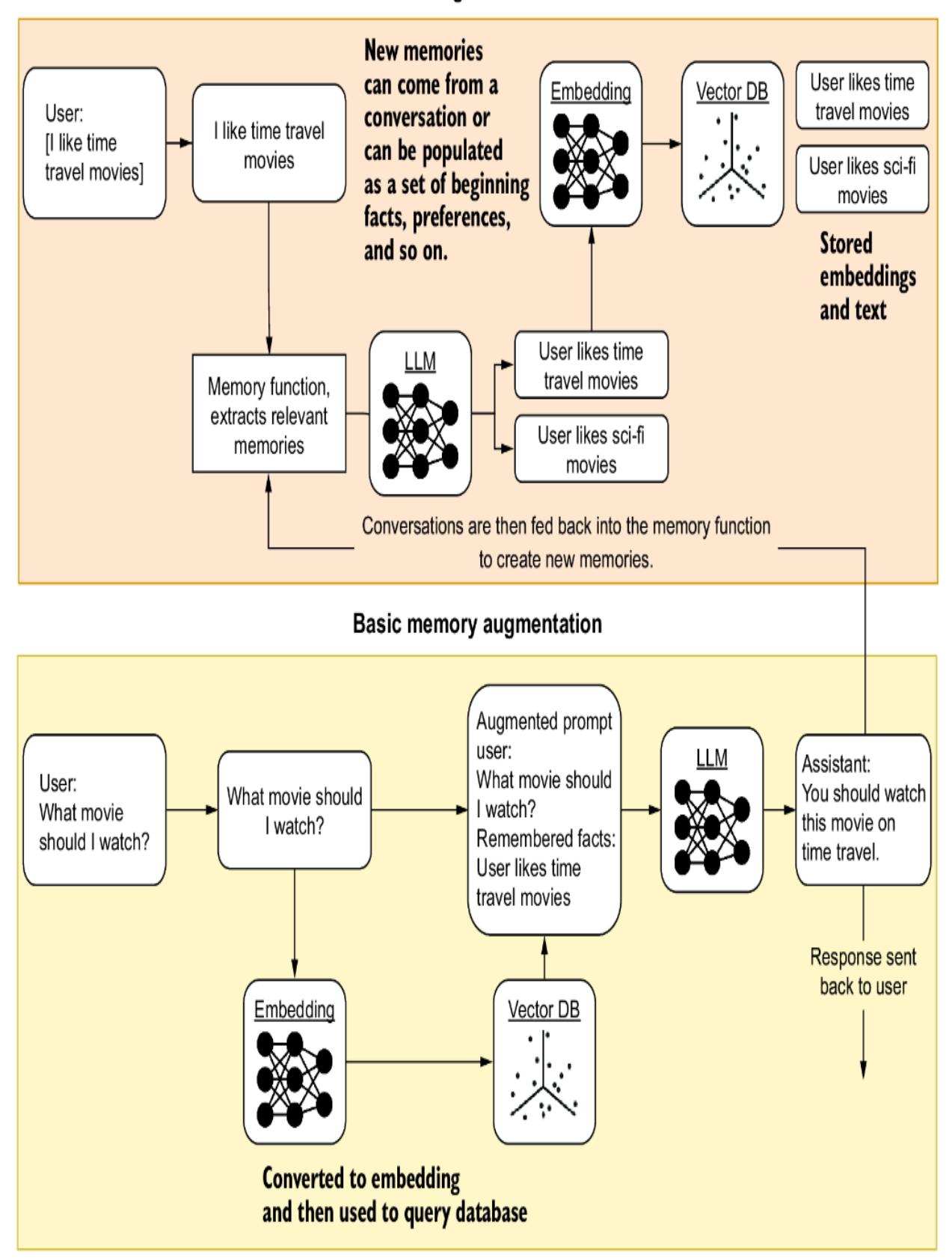
Figure 8.14 Basic memory retrieval and augmentation workflow
Nexus provides a mechanism like the knowledge store, allowing users to create memory stores that can be configured for various uses and applications. It also supports some of the more advanced memory forms highlighted in figure 8.13. The following section will examine how basic memory stores work in Nexus.
8.6.1 Consuming memory stores in Nexus
Memory stores operate and are constructed like knowledge stores in Nexus. They both heavily rely on the retrieval pattern. What differs is the extra steps memory systems take to build new memories.
Go ahead and start Nexus, and refer to listing 8.9 if you need to install it. After logging in, select the Memory page, and create a new memory store, as shown in figure 8.15. Select an agent engine, and then add a few personal facts and preferences about yourself.
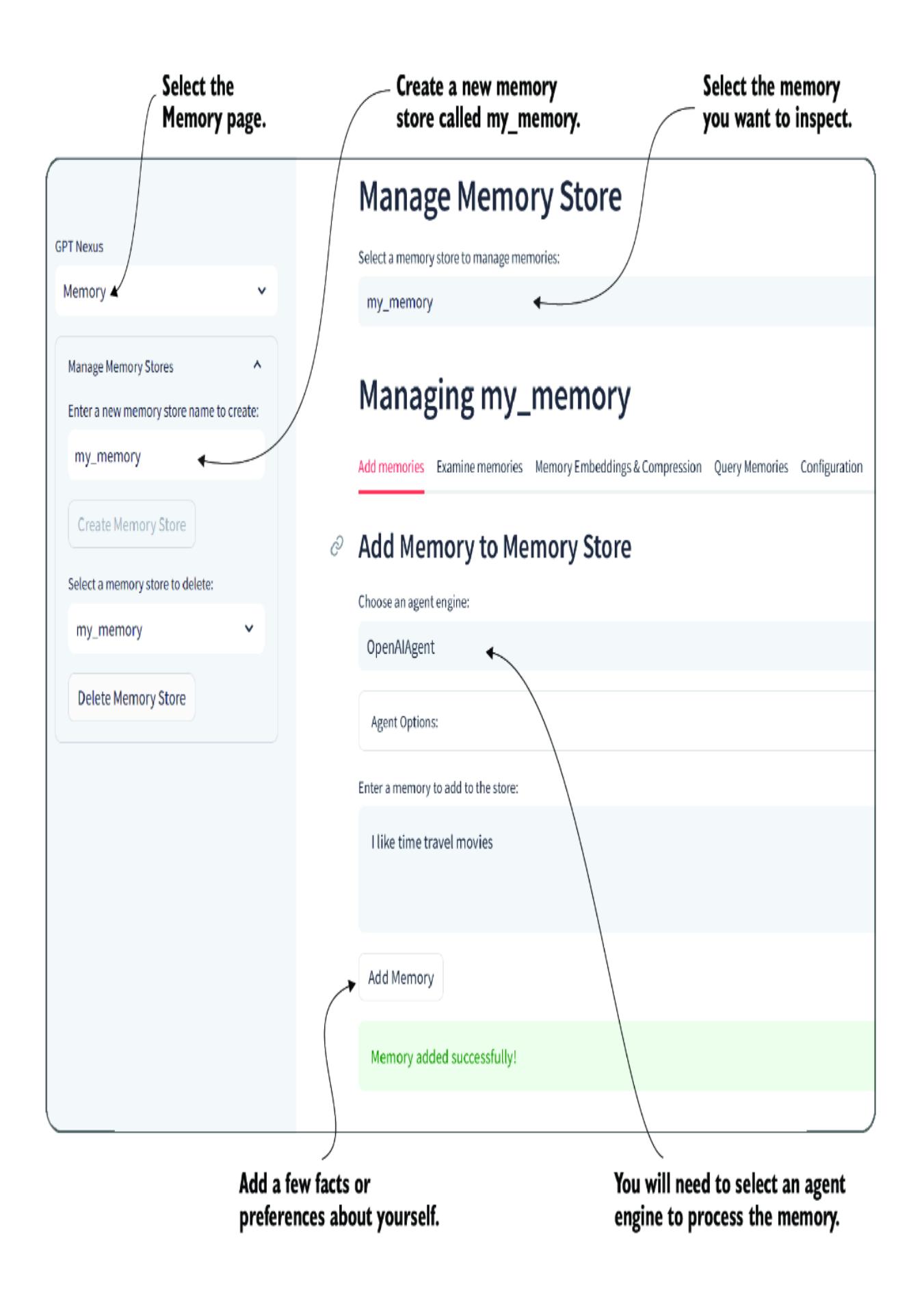
Figure 8.15 Adding memories to a newly created memory store
The reason we need an agent (LLM) was shown in figure 8.14 earlier. When information is fed into a memory store, it’s generally processed through an LLM using a memory function, whose purpose is to process the statements/conversations into semantically relevant information related to the type of memory.
Listing 8.10 shows the conversational memory function used to extract information from a conversation into memories. Yes, this is just the header portion of the prompt sent to the LLM, instructing it how to extract information from a conversation.
Listing 8.10 Conversational memory function
Summarize the conversation and create a set of statements that summarize the conversation. Return a JSON object with the following keys: ‘summary’. Each key should have a list of statements that are relevant to that category. Return only the JSON object and nothing else.
After you generate a few relevant memories about yourself, return to the Chat area in Nexus, enable the my_memory memory store, and see how well the agent knows you. Figure 8.16 shows a sample conversation using a different agent engine.

Figure 8.16 Conversing with a different agent on the same memory store
This is an example of a basic memory pattern that extracts facts/preferences from conversations and stores them in a vector database as memories. Numerous other implementations of memory follow those displayed earlier in figure 8.13. We’ll implement those in the next section.
8.6.2 Semantic memory and applications to semantic, episodic, and procedural memory
Psychologists categorize memory into multiple forms, depending on what information is remembered. Semantic, episodic, and procedural memory all represent different types of information. Episodic memories are about events, procedural memories are about the process or steps, and semantic
represents the meaning and could include feelings or emotions. Other forms of memory (geospatial is another), aren’t described here but could be.
Because these memories rely on an additional level of categorization, they also rely on another level of semantic categorization. Some platforms, such as Semantic Kernel (SK), refer to this as semantic memory. This can be confusing because semantic categorization is also applied to extract episodic and procedural memories.
Figure 8.17 shows the semantic memory categorization process, also sometimes called semantic memory. The difference between semantic memory and regular memory is the additional step of processing the input semantically and extracting relevant questions that can be used to query the memory-relevant vector database.
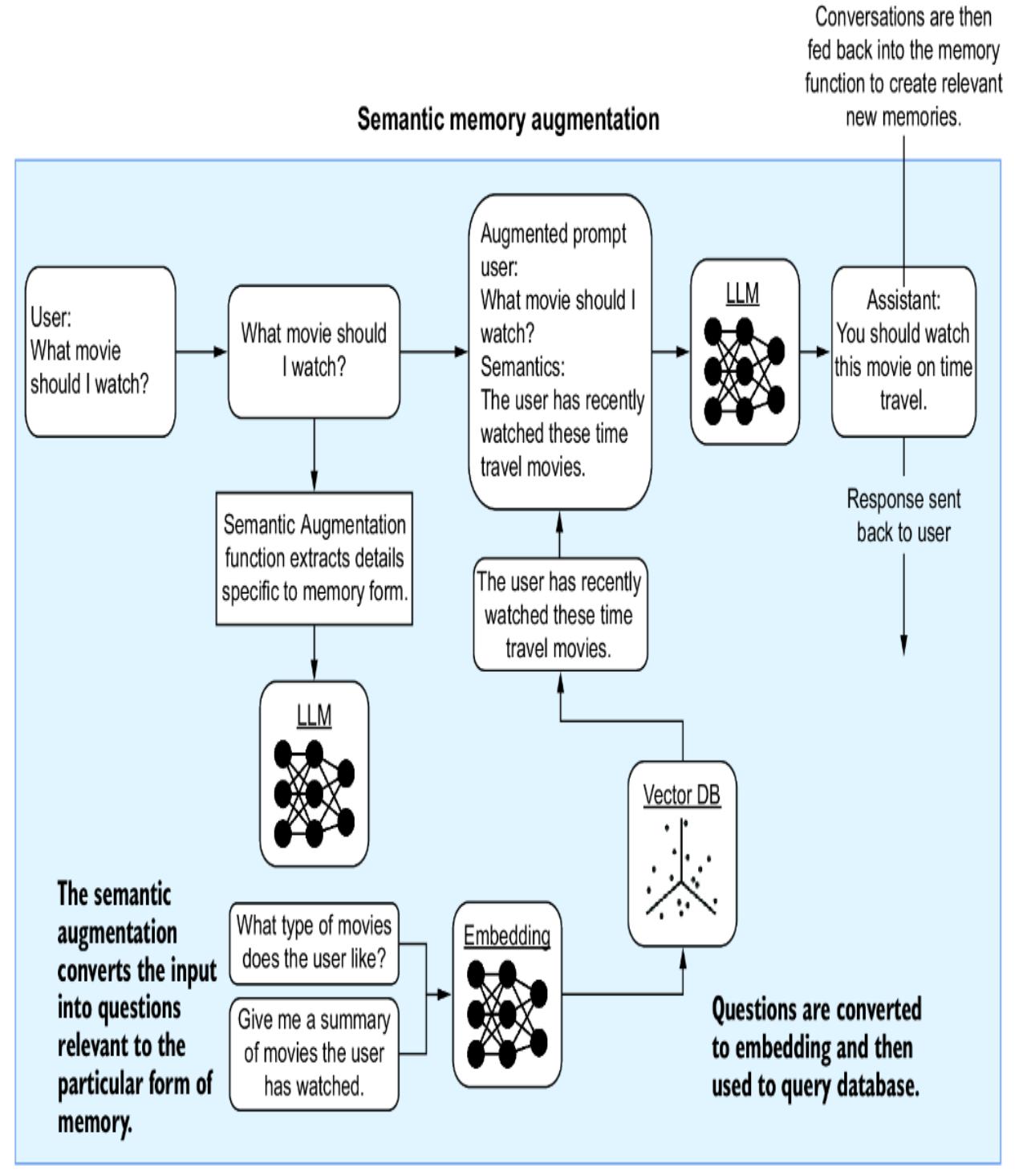
Figure 8.17 How semantic memory augmentation works
The benefit of using semantic augmentation is the increased ability to extract more relevant memories. We can see this in operation by jumping back into Nexus and creating a new semantic memory store.
Figure 8.18 shows how to configure a new memory store using semantic memory. As of yet, you can’t configure the specific function prompts for memory, augmentation, and summarization. However, it can be useful to read through each of the function prompts to gain a sense of how they work.

Figure 8.18 Configuration for changing the memory store type to semantic
Now, if you go back and add facts and preferences, they will convert to the semantics of the relevant memory type. Figure 8.19 shows an example of memories being populated for the same set of statements into two different forms of memory. Generally, the statements entered into memory would be more specific to the form of memory.
| ID Hash | Memory |
|---|---|
| 9W8VW9oh5b | The interlocutor has a preference for movies that involve time travel. |
| Bfl_FnsdpU | The person has a preference for movies that involve time loops. |
| D27dzx-YxU | The interlocutor enjoys time travel movies. |
| Ef H19Jc D | The interlocutor enjoys watching time loop movies. |
| OSRsYrThXQ | It can be inferred that the individual finds time loop movies entertaining. |
| ID Hash | Memory | |
|---|---|---|
| 0 | 0AQPgbOy-F | This conversation focuses on time loop movies. |
| D27dzx-YxU | The interlocutor enjoys time travel movies. | |
| 2 | Z4MOsfNjZl | The interlocutor exhibits a preference for cinema that involves time travel. |
| 3 O-XfTP4mS | The person enjoys watching time loop movies. | |
| 4 | sFU16iMoz8 | It is indicated that time travel movies are a topic of interest for the interlocutor. |
| 5 | uKQc6z9yS7 | The interlocutor appreciates the concept of moving through different time periods in movies. |
| 6 | uogR5kBGW9 | The person has a preference for a specific genre of movies, namely time loop movies. |
Figure 8.19 Comparing memories for the same information given two different memory types
Memory and knowledge can significantly assist an agent with various application types. Indeed, a single memory/knowledge store could feed one or multiple agents, allowing for further specialized interpretations of both types of stores. We’ll finish out the chapter by discussing memory/knowledge compression next.
8.7 Understanding memory and knowledge compression
Much like our own memory, memory stores can become cluttered with redundant information and numerous unrelated details over time. Internally, our minds deal with memory clutter by compressing or summarizing memories. Our minds remember more significant details over less important ones, and memories accessed more frequently.
We can apply similar principles of memory compression to agent memory and other retrieval systems to extract significant details. The principle of compression is similar to semantic augmentation but adds another layer to the preclusters groups of related memories that can collectively be summarized.
Figure 8.20 shows the process of memory/knowledge compression. Memories or knowledge are first clustered using an algorithm such as kmeans. Then, the groups of memories are passed through a compression function, which summarizes and collects the items into more succinct representations.
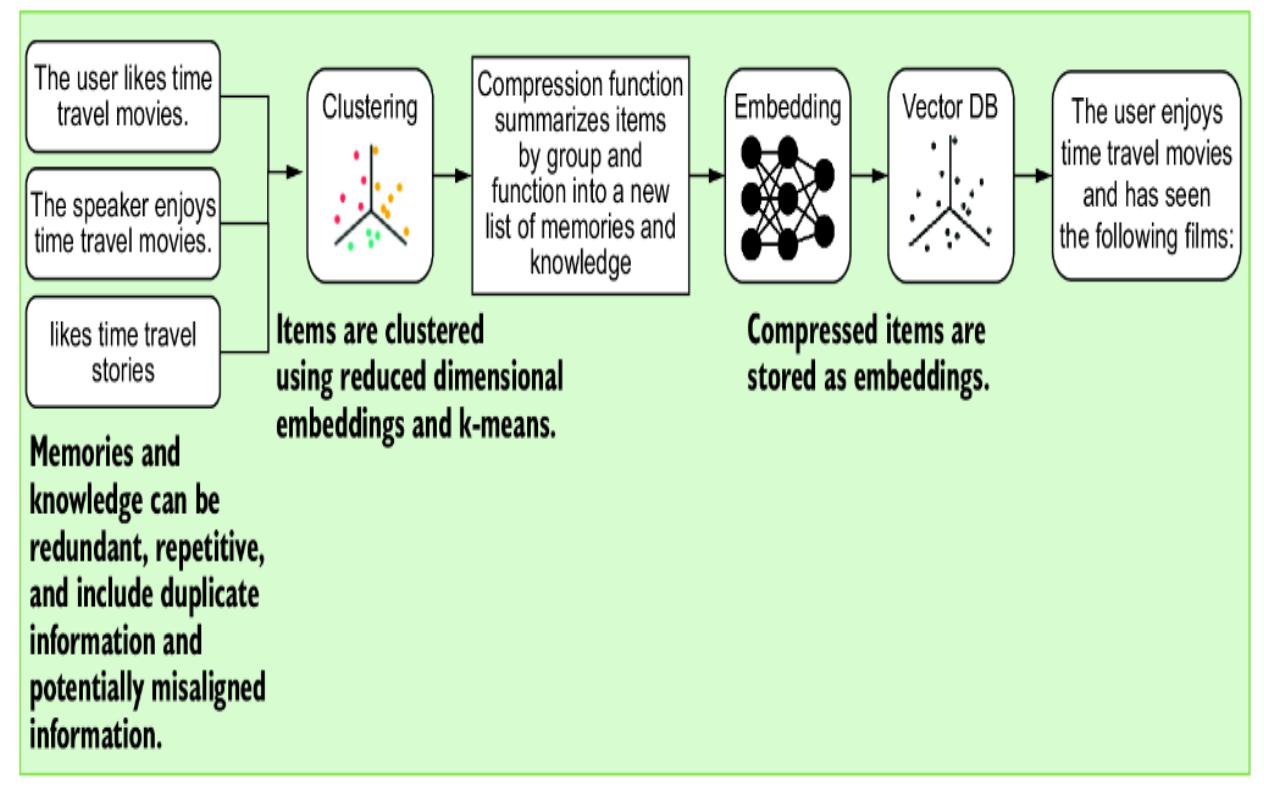
Figure 8.20 The process of memory and knowledge compression
Nexus provides for both knowledge and memory store compression using k-means optimal clustering. Figure 8.21 shows the compression interface for memory. Within the compression interface, you’ll see the items displayed in 3D and clustered. The size (number of items) of the clusters is shown in the left table.
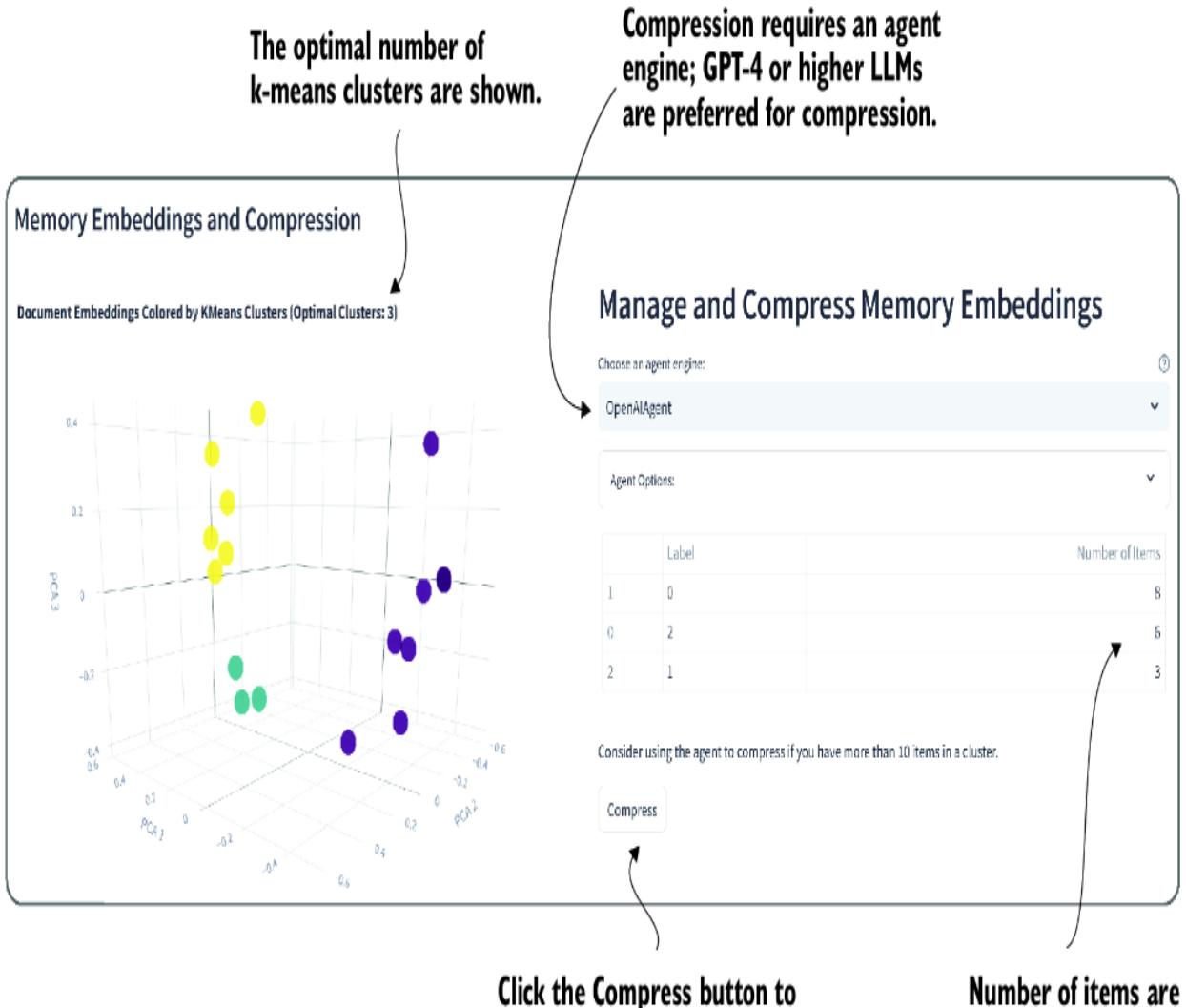
Figure 8.21 The interface for compressing memories
Compressing memories and even knowledge is generally recommended if the number of items in a cluster is large or unbalanced. Each use case for compression may vary depending on the use and application of memories. Generally, though, if an inspection of the items in a store contains repetitive or duplicate information, it’s a good time for compression. The following is a summary of use cases for applications that would benefit from compression.
THE CASE FOR KNOWLEDGE COMPRESSION
Knowledge retrieval and augmentation have also been shown to benefit significantly from compression. Results will vary by use case, but generally, the more verbose the source of knowledge, the more it will benefit from compression. Documents that feature literary prose, such as stories and novels, will benefit more than, say, a base of code. However, if the code is likewise very repetitive, compression could also be shown to be beneficial.
THE CASE FOR HOW OFTEN YOU APPLY COMPRESSION
Memory will often benefit from the periodic compression application, whereas knowledge stores typically only help on the first load. How frequently you apply compression will greatly depend on the memory use, frequency, and quantity.
THE CASE FOR APPLYING COMPRESSION MORE THAN ONCE
Multiple passes of compression at the same time has been shown to improve retrieval performance. Other patterns have also suggested using memory or knowledge at various levels of compression. For example, a knowledge store is compressed two times, resulting in three different levels of knowledge.
THE CASE FOR BLENDING KNOWLEDGE AND MEMORY COMPRESSION
If a system is specialized to a particular source of knowledge and that system also employs memories, there may be further optimization to consolidate stores. Another approach is to populate memory with the starting knowledge of a document directly.
THE CASE FOR MULTIPLE MEMORY OR KNOWLEDGE STORES
In more advanced systems, we’ll look at agents employing multiple memory and knowledge stores relevant to their workflow. For example, an agent could employ individual memory stores as part of its conversations with individual users, perhaps including the ability to share different groups of memory with different groups of individuals. Memory and knowledge retrieval are cornerstones of agentic systems, and we can now summarize what we covered and review some learning exercises in the next section.
8.8 Exercises
Use the following exercises to improve your knowledge of the material:
Exercise 1 —Load and Split a Different Document (Intermediate)
Objective —Understand the effect of document splitting on retrieval efficiency by using LangChain.
Tasks:
- Select a different document (e.g., a news article, a scientific paper, or a short story).
- Use LangChain to load and split the document into chunks.
- Analyze how the document is split into chunks and how it affects the retrieval process.
- Exercise 2 —Experiment with Semantic Search (Intermediate)
Objective —Compare the effectiveness of various vectorization techniques by performing semantic searches.
Tasks:
Choose a set of documents for semantic search.
Use a vectorization method such as Word2Vec or BERT embeddings instead of TF–IDF.
Perform the semantic search, and compare the results with those obtained using TF–IDF to understand the differences and effectiveness.
Exercise 3 —Implement a Custom RAG Workflow (Advanced)
Objective —Apply theoretical knowledge of RAG in a practical context using LangChain.
Tasks:
- Choose a specific application (e.g., customer service inquiries or academic research queries).
- Design and implement a custom RAG workflow using LangChain.
- Tailor the workflow to suit the chosen application, and test its effectiveness.
- Exercise 4 —Build a Knowledge Store and Experiment with Splitting Patterns (Intermediate)
Objective —Understand how different splitting patterns and compression affect knowledge retrieval.
Tasks:
- Build a knowledge store, and populate it with a couple of documents.
- Experiment with different forms of splitting/chunking patterns, and analyze their effect on retrieval.
- Compress the knowledge store, and observe the effects on query performance.
- Exercise 5 —Build and Test Various Memory Stores (Advanced)
Objective —Understand the uniqueness and use cases of different memory store types.
Tasks:
Build various forms of memory stores (conversational, semantic, episodic, and procedural).
- Interact with an agent using each type of memory store, and observe the differences.
- Compress the memory store, and analyze the effect on memory retrieval.
Summary
Memory in AI applications differentiates between unstructured and structured memory, highlighting their use in contextualizing prompts for more relevant interactions.
Retrieval augmented generation (RAG) is a mechanism for enhancing prompts with context from external documents, using vector embeddings and similarity search to retrieve relevant content.
Semantic search with document indexing converts documents into semantic vectors using TF–IDF and cosine similarity, enhancing the capability to perform semantic searches across indexed documents.
Vector databases and similarity search stores document vectors in a vector database, facilitating efficient similarity searches and improving retrieval accuracy.
Document embeddings capture semantic meanings, using models such as OpenAI’s models to generate embeddings that preserve a document’s context and facilitate semantic similarity searches.
LangChain provides several tools for performing RAG, and it abstracts the retrieval process, allowing for easy implementation of RAG and memory systems across various data sources and vector stores.
Short-term and long-term memory in LangChain implements conversational memory within LangChain, distinguishing between short-term buffering patterns and long-term storage solutions.
Storing document vectors in databases for efficient similarity searches is crucial for implementing scalable retrieval systems in AI applications.
Agent knowledge directly relates to the general RAG pattern of performing question and answer on documents or other textual information.
Agent memory is a pattern related to RAG that captures the agentic interactions with users, itself, and other systems.
Nexus is a platform that implements agentic knowledge and memory systems, including setting up knowledge stores for document retrieval and memory stores for various forms of memory.
Semantic memory augmentation (semantic memory) differentiates between various types of memories (semantic, episodic, procedural). It implements them through semantic augmentation, enhancing agents’ ability to recall and use information relevantly specific to the nature of the memories.
Memory and knowledge compression are techniques for condensing information stored in memory and knowledge systems, improving retrieval efficiency and relevancy through clustering and summarization.
9 Mastering agent prompts with prompt flow
This chapter covers
- Understanding systematic prompt engineering and setting up your first prompt flow
- Crafting an effective profile/persona prompt
- Evaluating profiles: Rubrics and grounding
- Grounding evaluation of a large language model profile
- Comparing prompts: Getting the perfect profile
In this chapter, we delve into the Test Changes Systematically prompt engineering strategy. If you recall, we covered the grand strategies of the OpenAI prompt engineering framework in chapter 2. These strategies are instrumental in helping us build better prompts and, consequently, better agent profiles and personas. Understanding this role is key to our prompt engineering journey.
Test Changes Systematically is such a core facet of prompt engineering that Microsoft developed a tool around this strategy called prompt flow, described later in this chapter. Before getting to prompt flow, we need to understand why we need systemic prompt engineering.
9.1 Why we need systematic prompt engineering
Prompt engineering, by its nature, is an iterative process. When building a prompt, you’ll often iterate and evaluate. To see this concept in action, consider the simple application of prompt engineering to a ChatGPT question.
You can follow along by opening your browser to ChatGPT (https://chat.openai.com/), entering the following (text) prompt into ChatGPT, and clicking the Send Message button (an example of this conversation is shown in figure 9.1, on the left side):
can you recommend something
| Applying prompt engineering | |||
|---|---|---|---|
| Can you please recommend a time travel movie that is set in a medieval period. | |||
| Certainly! A movie that fits the description of involving time travel and being set in a medieval period is “Timeline” (2003). This film is based on the novel by Michael Crichton and follows a group of archeology students who are transported back to the 14th century France through a time travel device. They find themselves in the middle of a war between English and French forces, and they must navigate this dangerous and unfamiliar world while trying to find a way back to their own time. The movie blends elements of science fiction with historical drama, offering an exciting and unique take on the time travel genre set against a medieval backdrop. |
|||
Figure 9.1 The differences in applying prompt engineering and iterating
We can see that the response from ChatGPT is asking for more information. Go ahead and open a new conversation with ChatGPT, and enter the following prompt, as shown in figure 9.1, on the right side:
Can you please recommend a time travel movie set in the medieval period.
The results in figure 9.1 show a clear difference between leaving out details and being more specific in your request. We just applied the tactic of politely Writing Clear Instructions, and ChatGPT provided us with a
good recommendation. But also notice how ChatGPT itself guides the user into better prompting. The refreshed screen shown in figure 9.2 shows the OpenAI prompt engineering strategies.
Figure 9.2 OpenAI prompt engineering strategies, broken down by agent component
We just applied simple iteration to improve our prompt. We can extend this example by using a system prompt/message. Figure 9.3 demonstrates the use and role of the system prompt in iterative communication. In chapter 2, we used the system message/prompt in various examples.
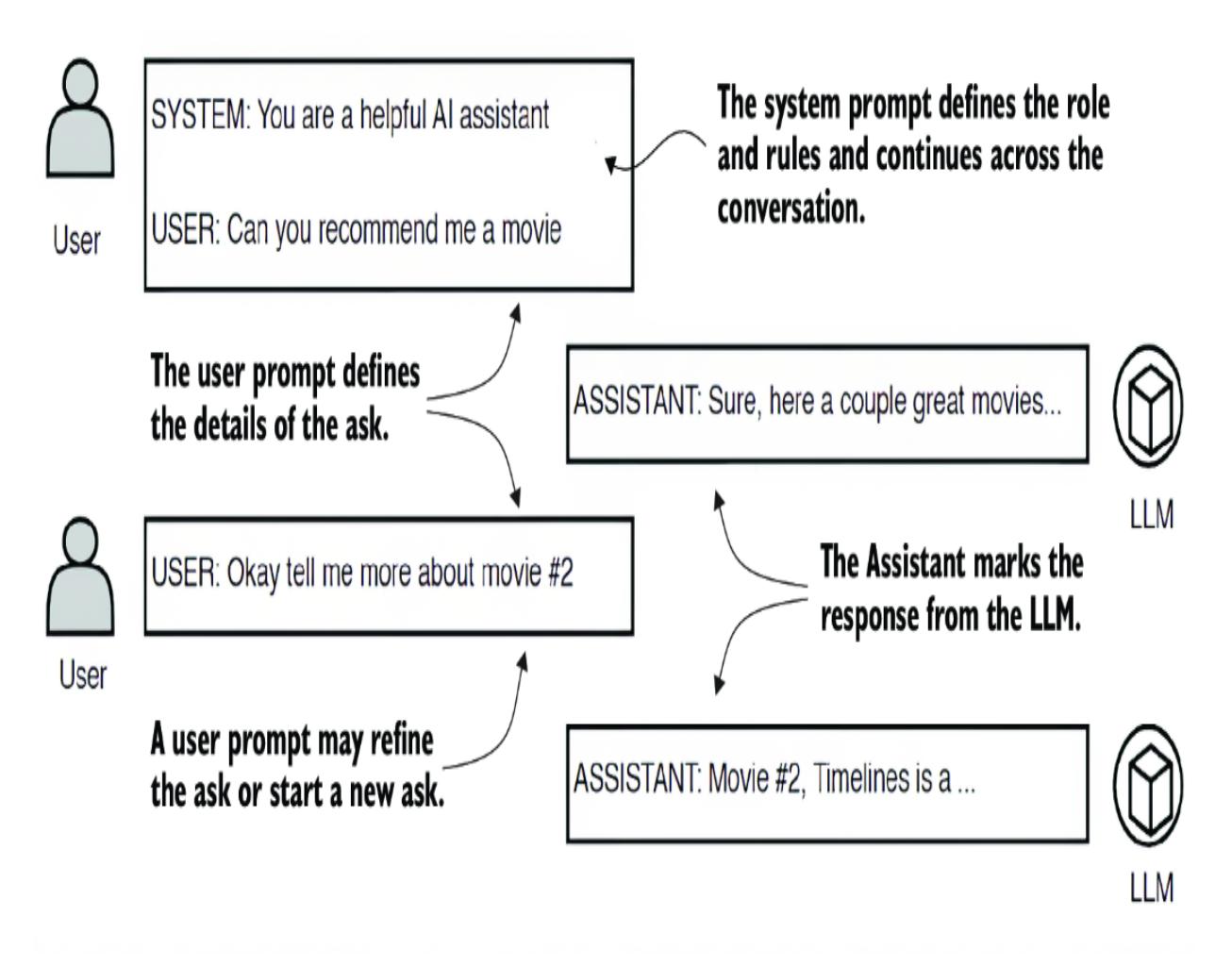
Figure 9.3 The messages to and from an LLM conversation and the iteration of messages
You can also try this in ChatGPT. This time, enter the following prompt and include the word system in lowercase, followed by a new line (enter a new line in the message window without sending the message by pressing Shift-Enter):
system
You are an expert on time travel movies.
ChatGPT will respond with some pleasant comments, as shown in figure 9.4. Because of this, it’s happy to accept its new role and asks for any follow-up questions. Now enter the following generic prompt as we did previously:
can you recommend something
Figure 9.4 The effect of adding a system prompt to our previous conversation
We’ve just seen the iteration of refining a prompt, the prompt engineering, to extract a better response. This was accomplished over three different conversations using the ChatGPT UI. While not the most efficient way, it works.
However, we haven’t defined the iterative flow for evaluating the prompt and determining when a prompt is effective. Figure 9.5 shows a systemic method of prompt engineering using a system of iteration and evaluation.
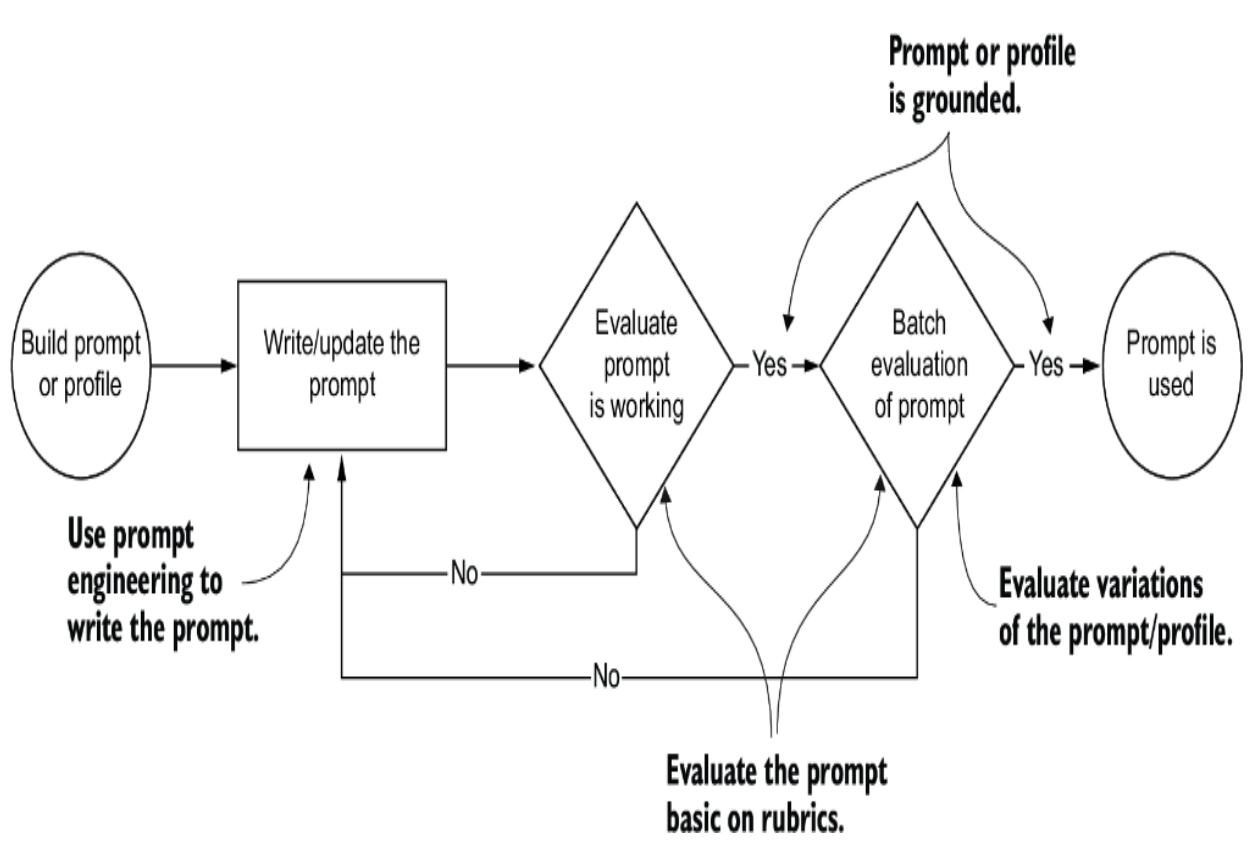
Figure 9.5 The systemic method of prompt engineering
The system of iterating and evaluating prompts covers the broad Test Changes Systemically strategy. Evaluating the performance and effectiveness of prompts is still new, but we’ll use techniques from education, such as rubrics and grounding, which we’ll explore in a later section of this chapter. However, as spelled out in the next section, we need to understand the difference between a persona and an agent profile before we do so.
9.2 Understanding agent profiles and personas
An agent profile is an encapsulation of component prompts or messages that describe an agent. It includes the agent’s persona, special instructions, and other strategies that can guide the user or other agent consumers.
Figure 9.6 shows the main elements of an agent profile. These elements map to prompt engineering strategies described in this book. Not all agents will use all the elements of a full agent profile.
Figure 9.6 The component parts of an agent profile
At a basic level, an agent profile is a set of prompts describing the agent. It may include other external elements related to actions/tools, knowledge, memory, reasoning, evaluation, planning, and feedback. The combination of these elements comprises an entire agent prompt profile.
Prompts are the heart of an agent’s function. A prompt or set of prompts drives each of the agent components in the profile. For actions/tools, these prompts are well defined, but as we’ve seen, prompts for memory and knowledge can vary significantly by use case.
The definition of an AI agent profile is more than just a system prompt. Prompt flow can allow us to construct the prompts and code comprising the agent profile but also include the ability to evaluate its effectiveness. In the next section, we’ll open up prompt flow and start using it.
9.3 Setting up your first prompt flow
Prompt flow is a tool developed by Microsoft within its Azure Machine Learning Studio platform. The tool was later released as an open source project on GitHub, where it has attracted more attention and use. While initially intended as an application platform, it has since shown its strength in developing and evaluating prompts/ profiles.
Because prompt flow was initially developed to run on Azure as a service, it features a robust core architecture. The tool supports multi-threaded batch processing, which makes it ideal for evaluating prompts at scale. The following section will examine the basics of starting with prompt flow.
9.3.1 Getting started
There are a few prerequisites to undertake before working through the exercises in this book. The relevant prerequisites for this section and chapter are shown in the following list; make sure to complete them before attempting the exercises:
- Visual Studio Code (VS Code) —Refer to appendix A for installation instructions, including additional extensions.
- Prompt flow, VS Code extension —Refer to appendix A for details on installing extensions.
- Python virtual environment —Refer to appendix A for details on setting up a virtual environment.
- Install prompt flow packages —Within your virtual environment, do a quick pip install, as shown here:
pip install promptflow promptflow-tools- LLM (GPT-4 or above) —You’ll need access to GPT-4 or above through OpenAI or Azure OpenAI Studio. Refer to appendix B if you need assistance accessing these resources.
- Book’s source code —Clone the book’s source code to a local folder; refer to appendix A if you need help cloning the repository.
Open up VS Code to the book’s source code folder, chapter 3. Ensure that you have a virtual environment connected and have installed the prompt flow packages and extension.
First, you’ll want to create a connection to your LLM resource within the prompt flow extension. Open the prompt flow extension within VS Code, and then click to open the connections. Then, click the plus sign beside the LLM resource to create a new connection, as shown in figure 9.7.
| X | File | Edit Selection View Go Run Terminal Help | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PROMPT FLOW | VS Code | |||||||||||
| V QUICK ACCESS Quickly reach the referenced resources. | ||||||||||||
| \(+\) Create new flow | ||||||||||||
| P | Install dependencies | |||||||||||
| recommender_with_LLM_evaluation_variant_1_202311252026 | (omitted) | |||||||||||
| recommender_with_LLM_evaluation_variant_0_202311252025 | ||||||||||||
| P. | \(\vee\) Run against run Run against run | |||||||||||
| Click to open the prompt flow extension. | ||||||||||||
| V CONNECTIONS Lists all your connections. Right-click to manage. | ||||||||||||
| ∕ | Azure content safety | |||||||||||
| Azure OpenAl | ||||||||||||
| Cognitive search | Click the plus to create a new connection. | |||||||||||
| \(\left\langle \right\rangle\) | Custom | |||||||||||
| > OpenAl | ||||||||||||
| > Qdrant | ||||||||||||
| \(\vee\) Serp Weaviate |
||||||||||||
Figure 9.7 Creating a new prompt flow LLM connection
This will open a YAML file where you’ll need to populate the connection name and other information relevant to your connection. Follow the
directions, and don’t enter API keys into the document, as shown in figure 9.8.

Figure 9.8 Setting the connection information for your LLM resource
When the connection information is entered, click the Create Connection link at the bottom of the document. This will open a terminal prompt below the document, asking you to enter your key. Depending on your terminal configuration, you may be unable to paste (Ctrl-V, Cmd-V). Alternatively, you can paste the key by hovering the mouse cursor over the terminal and right-clicking on Windows.
We’ll now test the connection by first opening the simple flow in the chapter_09/promptflow/simpleflow folder. Then, open the flow.dag.yaml file in VS Code. This is a YAML file, but the prompt flow extension provides a visual editor that is accessible by clicking the Visual Editor link at the top of the file, as shown in figure 9.9.
Figure 9.9 Opening the prompt flow visual editor
After the visual editor window is opened, you’ll see a graph representing the flow and the flow blocks. Double-click the recommender block, and set the connection name, API type, and model or deployment name, as shown in figure 9.10.
| Select the | connection name. | API type | Model or deployment name |
Double-click to open LLM block. |
|
|---|---|---|---|---|---|
| \(\overrightarrow{\mathbf{Q}}\) recommender \(\overleftarrow{\mathbb{O}}\) connection: OpenAl Advanced parameters > Function calling > |
\(\vee\) api: chat | \(+\) LLM \(\vee\) model: |
\(+\) Prompt \(+\) Python \(+\) More gpt-4-1106-preview \(\vee\) temperature: 1 stop: |
▷ 卅 會 个 ↓ ◎ max_tokens: 256 |
inputs |
| Prompt: recommend.jinja2 [9] Inputs \(\vee\) |
of recommender ⊛ 2 Completed |
||||
| Name | Type | Value | |||
| user_input * | string | ${inputs.user_input} | |||
| Seeing issues with the interface? Try: Regenerate with advanced options | echo ⊗ |
||||
| Activate config > | 2 Completed | ||||
| Outputs & Logs [1 success ] open in new tab |
Inputs Output |
outputs |
Figure 9.10 Setting the LLM connection details
A prompt flow is composed of a set of blocks starting with an Inputs block and terminating in an Outputs block. Within this simple flow, the recommender block represents the LLM connection and the prompt used to converse with the model. The echo block for this simple example echoes the input.
When creating a connection to an LLM, either in prompt flow or through an API, here are the crucial parameters we always need to consider (prompt flow documentation: https://microsoft.github.io/promptflow):
Connection —This is the connection name, but it also represents the service you’re connecting to. Prompt flow supports multiple services, including locally deployed LLMs.
API —This is the API type. The options are chat for a chat completion API, such as GPT-4, or completion for the older completion models, such as the OpenAI Davinci.
Model —This may be the model or deployment name, depending on your service connection. For OpenAI, this will be the model’s name, and for Azure OpenAI, it will represent the deployment name.
Temperature —This represents the stochasticity or variability of the model response. A value of 1 represents a high variability of responses, while 0 indicates a desire for no variability. This is a critical parameter to understand and, as we’ll see, will vary by use case.
Stop —This optional setting tells the call to the LLM to stop creating tokens. It’s more appropriate for older and open source models.
Max tokens —This limits the number of tokens used in a conversation. Knowledge of how many tokens you use is crucial to evaluating how your LLM interactions will work when scaled. Counting tokens may not be a concern if you’re exploring and conducting research. However, in production systems, tokens represent the load on the LLM, and connections using numerous tokens may not scale well.
Advanced parameters —You can set a few more options to tune your interaction with the LLM, but we’ll cover that topic in later sections of the book.
After configuring the LLM block, scroll up to the Inputs block section, and review the primary input shown in the user_input field, as shown in figure 9.11. Leave it as the default, and then click the Play button at the top of the window.
Figure 9.11 Setting the inputs and starting the flow
All the blocks in the flow will run, and the results will be shown in the terminal window. What you should find interesting is that the output shows recommendations for time travel movies. This is because the recommender block already has a simple profile set, and we’ll see how that works in the next section.
9.3.2 Creating profiles with Jinja2 templates
The flow responds with time travel movie recommendations because of the prompt or profile it uses. By default, prompt flow uses Jinja2 templates to define the content of the prompt or what we’ll call a profile. For the purposes of this book and our exploration of AI agents, we’ll refer to these templates as the profile of a flow or agent.
While prompt flow doesn’t explicitly refer to itself as an assistant or agent engine, it certainly meets the criteria of producing a proxy and general types of agents. As you’ll see, prompt flow even supports deployments of flows into containers and as services.
Open VS Code to chapter_09/promptflow/simpleflow/flow.dag.yaml, and open the file in the visual editor. Then, locate the Prompt field, and click the recommended .jinja2 link, as shown in figure 9.12.
| Click the link to open the Jinja2 template. |
Defines the start of the system and user portion of the prompt/profile |
||
|---|---|---|---|
| o 2 recommender [ 0 connection: CpenAl v api: Advanced parameters > Function calling Prompt: recommend.jinja2 [94 |
\(\vee\) model: \(qpt-4-1106\) -preview \(\vee\) temperature: 1 chat |
chapter_2 > prompt_flow > simple_flow > \(\pi\) recommend.jinja2 D 拼 自 个 ↓ ◎ Go back to YAML Go back to visual editor {# Prompt is a jinja2 template that generates prompt for LLM #} max_tokens: 256 stop: system: You are an expert on time travel movies. user: |
|
| Inputs \(\vee\) Type Name |
Value | {{user_input}} ÿ |
|
| user_input* string Seeing issues with the interface? Try: Regenerate with advanced options |
${inputs.user_input} | ||
| Activate config | |||
| Outputs & Logs Inputs [1 success ] open in new tab |
Output | ||
| This is where the user input | The role of the profile |
Figure 9.12 Opening the prompt Jinja2 template and examining the parts of the profile/prompt
Jinja is a templating engine, and Jinja2 is a particular version of that engine. Templates are an excellent way of defining the layout and parts of any form of text document. They have been extensively used to produce HTML, JSON, CSS, and other document forms. In addition, they support the ability to apply code directly into the template. While there is no standard way to construct prompts or agent profiles, our preference in this book is to use templating engines such as Jinja.
At this point, change the role within the system prompt of the recommended.jinja2 template. Then, run all blocks of the flow by opening the flow in the visual editor and clicking the Play button. The next section will look at other ways of running prompt flow for testing or actual deployment.
9.3.3 Deploying a prompt flow API
Because prompt flow was also designed to be deployed as a service, it supports a couple of ways to deploy as an app or API quickly. Prompt flow can be deployed as a local web application and API running from the terminal or as a Docker container.
Return to the flow.dag.yaml file in the visual editor from VS Code. At the top of the window beside the Play button are several options we’ll want to investigate further. Click the Build button as shown in figure 9.13, and then select to deploy as a local app. A new YAML file will be created to configure the app. Leave the defaults, and click the Start Local App link.
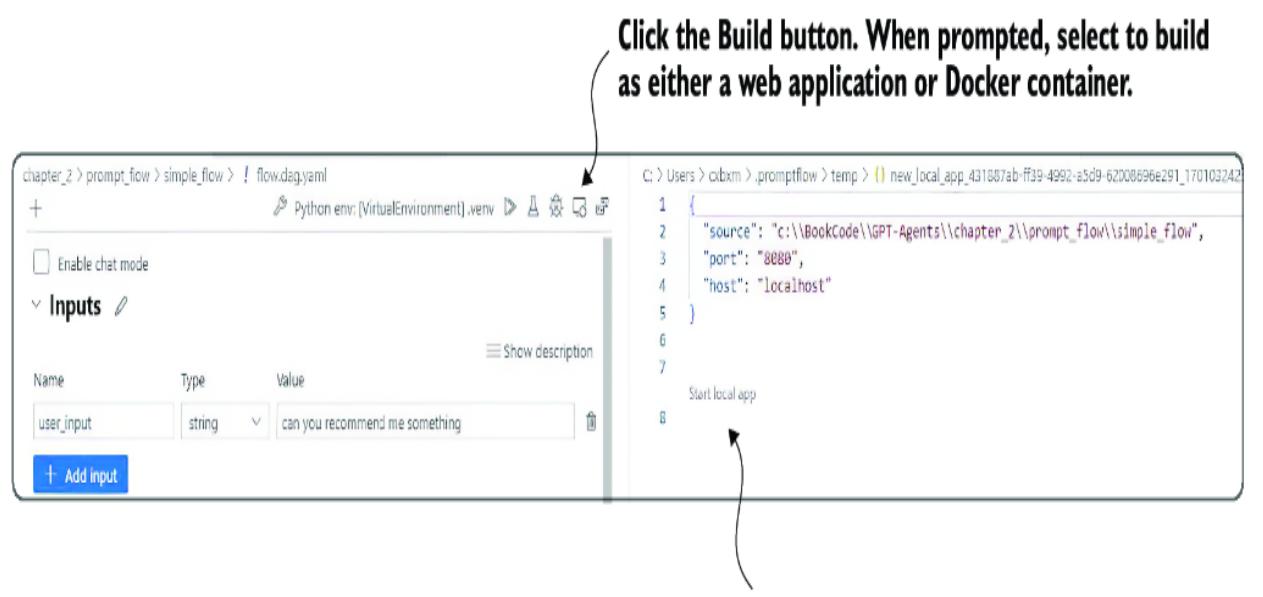

Figure 9.13 Building and starting the flow as a local app
This will launch the flow as a local web application, and you’ll see a browser tab open, as shown in figure 9.14. Enter some text into the user_input field, which is marked as required with a red asterisk. Click Enter and wait a few seconds for the reply.
| D localhost:8080 C 0 |
☆ | ଡ଼ ย |
|
|---|---|---|---|
| \(+\) New chat | simple_flow(1.0.0) ① | థ్ర | |
| can you recommend me some : | User a few seconds ago | J. | |
| can you recommend me something | |||
| Chatbot a few seconds ago Certainly! Time travel is a rich genre with many great films to choose from, each offering a different perspective on the concept. Here’s a list that includes a mix of classic and modern, serious and comedic, as well as action-packed and thought-provoking time travel movies: 1. “Back to the Future” (1985) - Directed by Robert Zemeckis, it’s a quintessential time travel movie where teenager Marty McFly (Michael J. Fox) accidentally travels back in time and has to make sure his parents fall in love to secure his own existence. |
ŧ | ||
| user_input * | \(\triangleright\) | ||
| Keeps a history of submissions | Enter text to be used by the recommender. |
Figure 9.14 Running the flow as a local web application
You should see a reply like the one shown earlier in figure 9.12, where the flow or agent replies with a list of time travel movies. This is great—we’ve just developed our first agent profile and the equivalent of a proxy agent. However, we need to determine how successful or valuable the
recommendations are. In the next section, we explore how to evaluate prompts and profiles.
9.4 Evaluating profiles: Rubrics and grounding
A key element of any prompt or agent profile is how well it performs its given task. As we see in our recommendation example, prompting an agent profile to give a list of recommendations is relatively easy, but knowing whether those recommendations are helpful requires us to evaluate the response.
Fortunately, prompt flow has been designed to evaluate prompts/profiles at scale. The robust infrastructure allows for the evaluation of LLM interactions to be parallelized and managed as workers, allowing hundreds of profile evaluations and variations to happen quickly.
In the next section, we look at how prompt flow can be configured to run prompt/ profile variations against each other. We’ll need to understand this before evaluating profiles’ performance.
Prompt flow provides a mechanism to allow for multiple variations within an LLM prompt/profile. This tool is excellent for comparing subtle or significant differences between profile variations. When used in performing bulk evaluations, it can be invaluable for quickly assessing the performance of a profile.
Open the recommender_with_variations/flow.dag.yaml file in VS Code and the flow visual editor, as shown in figure 9.15. This time, we’re making the profile more generalized and allowing for customization at the input level. This allows us to expand our recommendations to anything and not just time travel movies.
| \(+\) LLM \(+\) Prompt \(+\) Python \(+\) More | chapter_2 > prompt_flow > recommender_with_variations > : flow.dag.yaml ♪ Python env: [VirtualEnvironment] .venv ▷ △ 没 □ eP |
||
|---|---|---|---|
| Enable chat mode \(\vee\) Inputs \(\varnothing\) |
Added additional inputs into the recommender \(\equiv\) Show description |
inputs | |
| Name | Type | Value | |
| subject | string | Ê time travel ٧ |
|
| genre | string | Û V fantasy |
|
| format | string | Û ٧ movies |
intercommender ⊛ |
| custom | string | Ê Please don’t include any romantic comedies or the romance genre. ٧ |
2 Completed |
| \(+\) Add input | The recommenderLLM has two variations. Click | ||
| Outputs > |
the adjust icons to see and edit the variations. | ||
| \(\overset{\leftrightarrow}{\mathfrak{G}}\) recommender \(\Box \ \mathscr{D}\) connection: OpenAl |
\(\vee\) api: chat | 2 variants Current: variant → 出自 个 ↓ ◎ Editing is currently disabled as there are multiple variants available. Please expand the variants to enable editing. model: gpt-4-1106-preview v temperature: 1 stop: max_tokens: 256 |
\(\bullet\) echo ⊛ 2 Completed |
| Advanced parameters > Function calling > Prompt: recommend.jinja2 Inputs \(\vee\) |
Inputs are passed directly to the recommender LLM block. |
outputs | |
| Name | Type | Value | |
| subject* | string | S(inputs.subject) | |
| genre ’ | string | S(inputs.genre) | |
| format ® | string | S(inputs.format) | |
| custom * | string | S(inputs.custom) | |
| Seeing issues with the interface? Try: Regenerate with advanced options | |||
| Activate config \(\rightarrow\) | |||
| Outputs & Logs 1 [2 success ] open in new tab |
Inputs Output |
Figure 9.15 The recommender, with variations in flow and expanded inputs
The new inputs Subject, Genre, Format, and Custom allow us to define a profile that can easily be adjusted to any recommendation. This also means that we must prime the inputs based on the recommendation use case. There are multiple ways to prime these inputs; two examples of priming inputs are shown in figure 9.16. The figure shows two options, options A and B, for priming inputs. Option A represents the classic UI; perhaps there are objects for the user to select the subject or genre, for example. Option B places a proxy/chat agent to interact with the user better to understand the desired subject, genre, and so on.
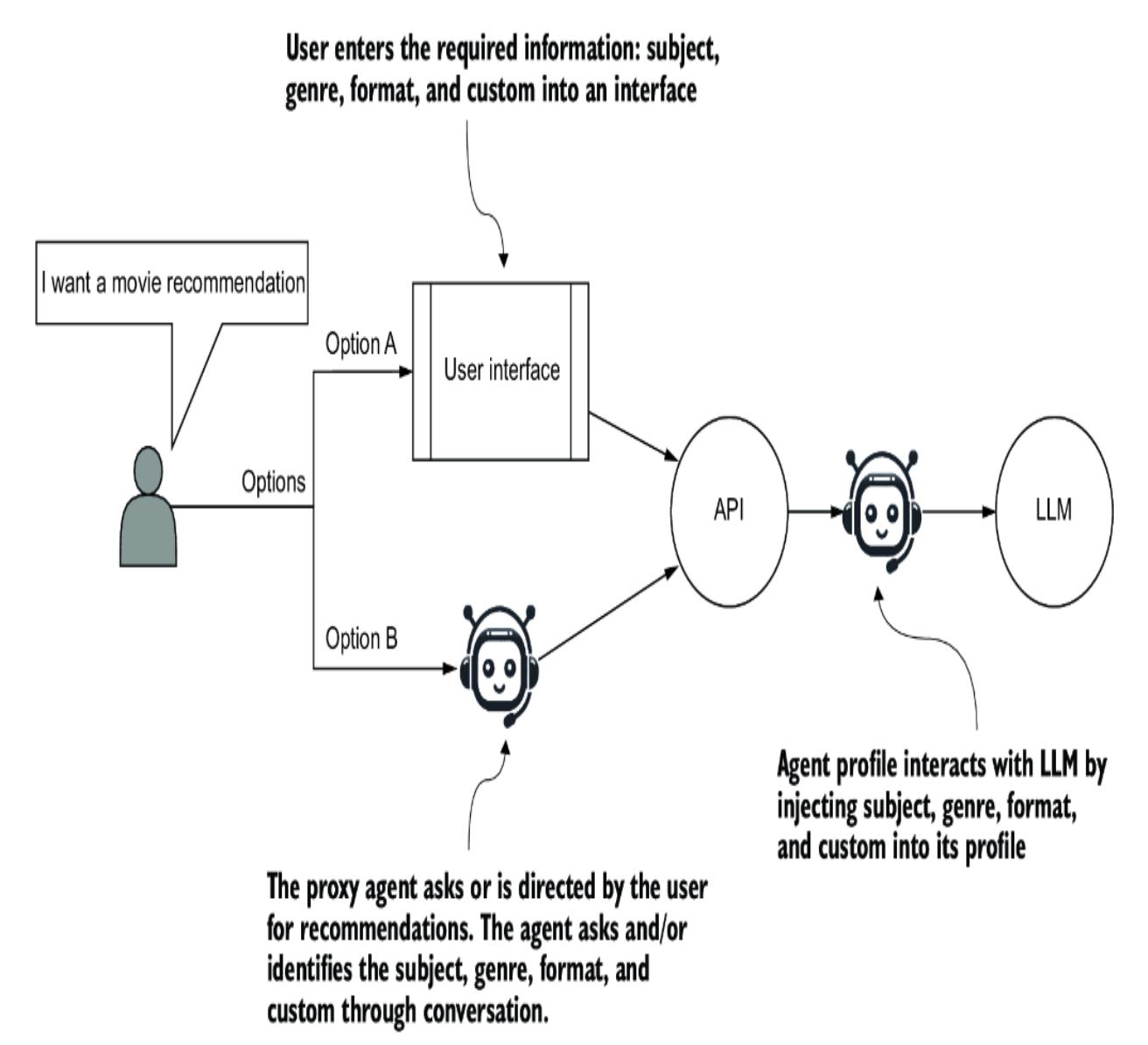

Even considering the power of LLMs, you may still want or need to use option A. The benefit of option A is that you can constrain and validate the inputs much like you do with any modern UI. Alternatively, the downside of option A is that the constrained behavior may limit and restrict future use cases.
Option B represents a more fluid and natural way without a traditional UI. It’s far more powerful and extensible than option A but also introduces more unknowns for evaluation. However, if the proxy agent that option B uses is written well, it can assist a lot in gathering better information from the user.
The option you choose will dictate how you need to evaluate your profiles. If you’re okay with a constrained UI, then it’s likely that the inputs will also be constrained to a set of discrete values. For now, we’ll assume option B for input priming, meaning the input values will be defined by their name.
To get back to VS Code and the visual view of the recommender with variants flow, click the icon shown earlier in figure 9.15 to open the variants and allow editing. Then, click the recommend.jinja2 and recommender_variant_1.jinja2 links to open the files side by side, as shown in figure 9.17.

Figure 9.17 Side-by-side comparison of variant profile templates for the recommender
Figure 9.17 demonstrates the difference between the variant profiles. One profile injects the inputs into the user prompt, and the other injects them into the system prompt. However, it’s essential to understand that variations can encompass more than profile design, as identified in table 9.1.
Table 9.1 LLM variation options in prompt flow
| Option | Evaluation option examples | Notes |
|---|---|---|
| Jinja2 prompt template |
Compare system prompt variations, user prompt variations, or mixed prompt variations. |
Some endless combinations and techniques can be applied here. Prompt engineering is evolving all the time. |
| LLM | Compare GPT-9.5 to GPT-4. Compare GPT-4 to GPT-4 Turbo. Compare open source models to commercial models. |
This is a useful way to evaluate and ground model performance against a prompt. It can also help you tune your profile to work with open source and/or cheaper models. |
| Temperature | Compare a 0 temperature (no randomness) to a 1 (maximum randomness). |
Changes to the temperature can significantly change the responses of some prompts, which may improve or degrade performance. |
| Max tokens | Compare limited tokens to larger token sizes. |
This can allow you to reduce and maximize token usage. |
| Advanced parameters |
Compare differences to options such as top_p, presence_penalty, frequency_penalty, and logit_bias. |
We’ll cover the use of these advanced parameters in later chapters. |
| Function calls | Compare alternative function calls. | Function calls will be addressed later in this chapter. |
For this simple example, we’re just going to use prompt variations by varying the input to reflect in either the system or user prompt. Refer to figure 9.17 for what this looks like. We can then quickly run both variations by clicking the Play (Run All) button at the top and choosing both, as shown in figure 9.18.

Figure 9.18 Running both prompt variations at the same time
In the terminal window, you’ll see the results of both runs. The results will likely look similar, so now we must move on to how we evaluate the difference between variations in the next section.
9.5 Understanding rubrics and grounding
Evaluation of prompt/profile performance isn’t something we can typically do using a measure of accuracy or correct percentage. Measuring the performance of a profile depends on the use case and desired outcome. If that is as simple as determining if the response was right or wrong, all the better. However, in most cases, evaluation won’t be that simple.
In education, the rubric concept defines a structured set of criteria and standards a student must establish to receive a particular grade. A rubric can also be used to define a guide for the performance of a profile or prompt. We can follow these steps to define a rubric we can use to evaluate the performance of a profile or prompt:
- Identify the purpose and objectives. Determine the goals you want the profile or agent to accomplish. For example, do you want to evaluate the quality of recommendations for a given audience or overall quality for a given subject, format, or other input?
- Define criteria. Develop a set of criteria or dimensions that you’ll use to evaluate the profile. These criteria should align with your objectives and provide clear guidelines for assessment. Each criterion should be specific and measurable. For example, you may want to measure a recommendation by how well it fits with the genre and then by subject and format.
- Create a scale. Establish a rating scale that describes the levels of performance for each criterion. Standard scales include numerical scales (e.g., 1–5) or descriptive scales (e.g., Excellent, Good, Fair, Poor).
- Provide descriptions. For each level on the scale, provide clear and concise descriptions that indicate what constitutes a strong performance and what represents a weaker performance for each criterion.
- Apply the rubric. When assessing a prompt or profile, use the rubric to evaluate the prompt’s performance based on the established criteria. Assign scores or ratings for each criterion, considering the descriptions for each level.
- Calculate the total score. Depending on your rubric, you may calculate a total score by summing up the scores for each criterion or using a weighted average if some criteria are more important than others.
- Ensure evaluation consistency. If multiple evaluators are assessing the profile, it’s crucial to ensure consistency in grading.
- Review, revise, and iterate. Periodically review and revise the rubric to ensure it aligns with your assessment goals and objectives. Adjust as needed to improve its effectiveness.
Grounding is a concept that can be applied to profile and prompt evaluation—it defines how well a response is aligned with a given rubric’s specific criteria and standards. You can also think of grounding as the baseline expectation of a prompt or profile output.
This list summarizes some other important considerations when using grounding with profile evaluation:
- Grounding refers to aligning responses with the criteria, objectives, and context defined by the rubric and prompt.
- Grounding involves assessing whether the response directly addresses the rubric criteria, stays on topic, and adheres to any provided instructions.
- Evaluators and evaluations gauge the accuracy, relevance, and adherence to standards when assessing grounding.
- Grounding ensures that the response output is firmly rooted in the specified context, making the assessment process more objective and meaningful.
A well-grounded response aligns with all the rubric criteria within the given context and objectives. Poorly grounded responses will fail or miss the entire criteria, context, and objectives.
As the concepts of rubrics and grounding may still be abstract, let’s look at applying them to our current recommender example. Following is a list that follows the process for defining a rubric as applied to our recommender example:
- Identify the purpose and objectives. The purpose of our profile/prompt is to recommend three top items given a subject, format, genre, and custom input.
- Define criteria. For simplicity, we’ll evaluate how a particular recommendation aligns with the given input criteria, subject, format, and genre. For example, if a profile recommends a book when asked for a movie format, we expect a low score in the format criteria.
- Create a scale. Again, keeping things simple, we’ll use a scale of 1–5 (1 is poor, and 5 is excellent).
- Provide descriptions. See the general descriptions for the rating scale shown in table 9.2.
- Apply the rubric. With the rubric assigned at this stage, it’s an excellent exercise to evaluate the rubric against recommendations manually.
- Calculate the total score. For our rubric, we’ll average the score for all criteria to provide a total score.
- Ensure evaluation consistency. The technique we’ll use for evaluation will provide very consistent results.
- Review, revise, and iterate. We’ll review, compare, and iterate on our profiles, rubrics, and the evaluations themselves.
Table 9.2 Rubric ratings
| Rating | Description |
|---|---|
| 1 | Poor alignment: this is the opposite of what is expected given the criteria. |
| 2 | Bad alignment: this isn’t a good fit for the given criteria. |
| 3 | Mediocre alignment: it may or may not fit well with the given criteria. |
| 4 | Good alignment: it may not align 100% with the criteria but is a good fit otherwise. |
| 5 | Excellent alignment: this is a good recommendation for the given criteria. |
This basic rubric can now be applied to evaluate the responses for our profile. You can do this manually, or as you’ll see in the next section, using a second LLM profile.
9.6 Grounding evaluation with an LLM profile
This section will employ another LLM prompt/profile for evaluation and grounding. This second LLM prompt will add another block after the recommendations are generated. It will process the generated recommendations and evaluate each one, given the previous rubric.
Before GPT-4 and other sophisticated LLMs came along, we would have never considered using another LLM prompt to evaluate or ground a profile. You often want to use a different model when using LLMs to ground a profile. However, if you’re comparing profiles against each other, using the same LLM for evaluation and grounding is appropriate.
Open the recommender_with_LLM_evaluation.dag.yaml file in the prompt flow visual editor, scroll down to the evaluate_recommendation block, and click the evaluate_recommendation.jinja2 link to open the
file, as shown in figure 9.19. Each section of the rubric is identified in the figure.
| # evaluate_recommendation.jinja2 U ● |
|---|
| chapter_2 > prompt_flow > recommender_with_LLM_evaluation > \(\leq\) evaluate_recommendation.jinja2 |
| Go back to YAML Go back to visual editor |
| system: 1 |
| Define the basic role of the profile. You are a discerning recommender of {{subject}} {{format}} of the {{genre}}. 2 |
| Your purpose is to evaluate the quality of given recommendations. 3 |
| Make sure that the recommendation aligns well with each of the criteria: 4 |
| Format - make sure the format aligns with {{format}} 5. Define the basic criteria for the rubric. |
| Suject - be sure the subject is the same as \(\{\) {subject}} \(\bullet\) 6 |
| Genre - make sure the genre is similar to \(\{\{\text{generic}\}\}\) 7 |
| 8 |
| 9 Please follow any special instructions and align your scores accordingly given here. {{custom}} |
| 10 |
| Rate each criteria, subject, format and genre on a scale from 1 to 5 using the following guide: 11 12 |
| Poor alignment: this is the opposite of what is expected given the criteria. 1 Define the rubric scale and Bad alignment: not a good fit for the given criteria. 13 2 |
| Mediocre alignment: it may or may not fit well with the given criteria 14 3. |
| a description for each item Good alignment: it may not align 100% with the criteria but is a good fit; otherwise 15 4 |
| on the scale. Excellent alignment: this is a good recommendation for the given criteria 16 |
| 17 |
| You will be shown a number of recommendations. 18 |
| Respond with only the item title and a rating from 1-5 (5 being the best) for each criterias alignment (Subject, Format and Genre). 19 |
| Below is an example of the requested output: 20 |
| Title: Time Bandits 21 |
| Subject: 8 22 |
| Format: 10 23 Reiterate the criteria and scale, and |
| 24 Genre: 8 |
| show an example of expected output. 25 |
| 26 user: |
| {{recommendations}} 27 |
| 28 |
Figure 9.19 The evaluation prompt, with each of the parts of the rubric outlined
We have a rubric that is not only well defined but also in the form of a prompt that can be used to evaluate recommendations. This allows us to evaluate the effectiveness of recommendations for a given profile automatically. Of course, you can also use the rubric to score and evaluate the recommendations manually for a better baseline.
Note Using LLMs to evaluate prompts and profiles provides a strong baseline for comparing the performance of a profile. It can also do this
without human bias in a controlled and repeatable manner. This provides an excellent mechanism to establish baseline groundings for any profile or prompt.
Returning to the recommender_with_LLM_evaluation flow visual editor, we can run the flow by clicking the Play button and observing the output. You can run a single recommendation or run both variations when prompted. The output of a single evaluation using the default inputs is shown in the following listing.
Listing 9.1 LLM rubric evaluation output{
"recommendations": "Title: The Butterfly Effect
Subject: 5
Format: 5
Genre: 4
Title: Primer
Subject: 5
Format: 5
Genre: 4
Title: Time Bandits
Subject: 5
Format: 5
Genre: 5"
}We now have a rubric for grounding our recommender, and the evaluation is run automatically using a second LLM prompt. In the next section, we look at how to perform multiple evaluations simultaneously and then at a total score for everything.
9.7 Comparing profiles: Getting the perfect profile
With our understanding of rubrics and grounding, we can now move on to evaluating and iterating the perfect profile. Before we do that, though, we need to clean up the output from the LLM evaluation block. This will require us to parse the recommendations into something more Pythonic, which we’ll tackle in the next section.
9.7.1 Parsing the LLM evaluation output
As the raw output from the evaluation block is text, we now want to parse that into something more usable. Of course, writing parsing functions is simple, but there are better ways to cast responses automagically. We covered better methods for returning responses in chapter 5, on agent actions.
Open
chapter_09_flow_with_parsing.dag.yaml in VS Code, and look at the flow in the visual editor. Locate the parsing_results block, and click the link to open the Python file in the editor, as shown in figure 9.20.
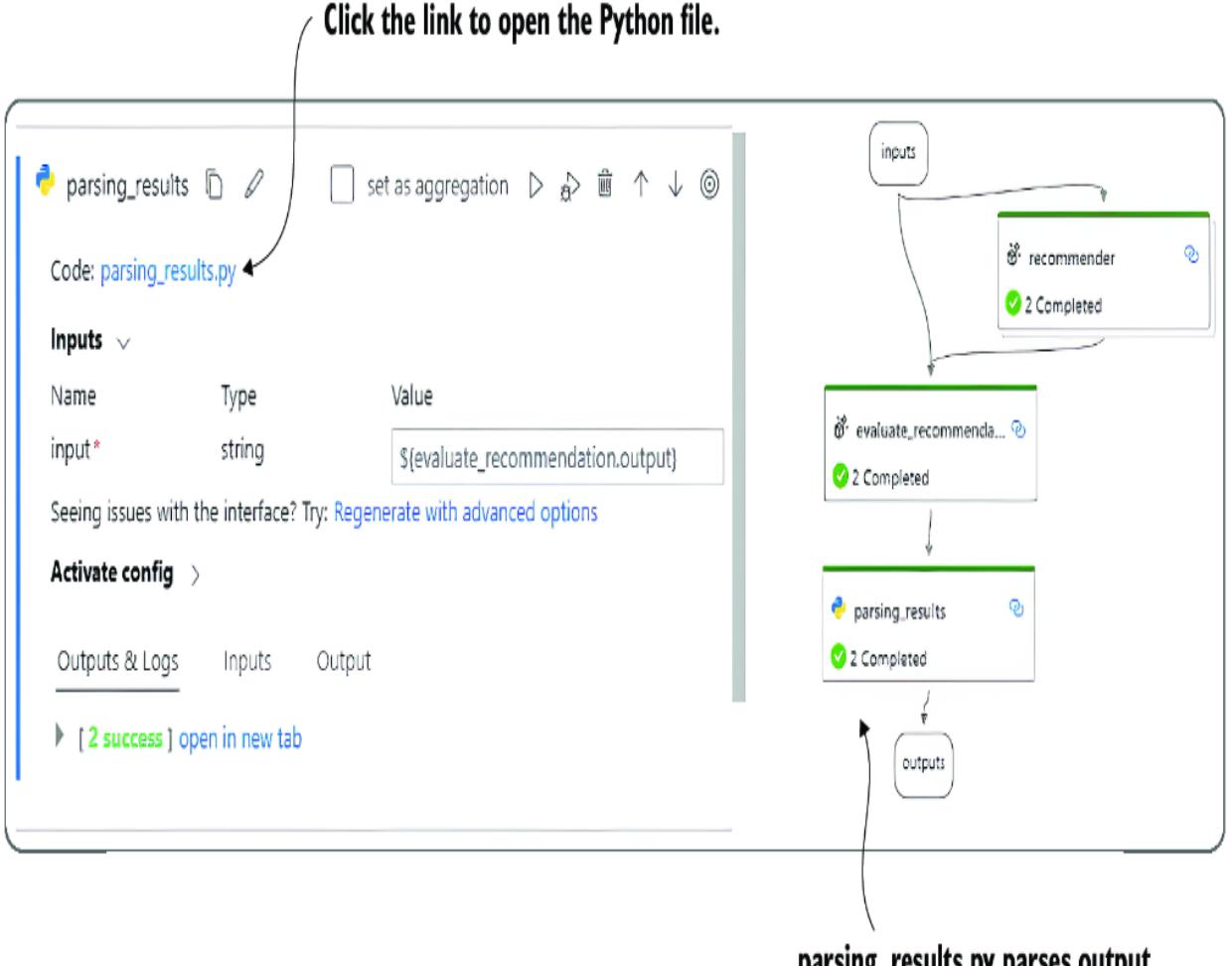
Figure 9.20 Opening the parsing_results.py file in VS Code
The code for the parsing_results.py file is shown in listing 9.2.
Listing 9.2 parsing_results.py
from promptflow import tool
@tool #1
def parse(input: str) -> str:
# Splitting the recommendations into individual movie blocks
rblocks = input.strip().split("\n\n") #2
# Function to parse individual recommendation block into dictionary
def parse_block(block):
lines = block.split('\n')
rdict = {}
for line in lines:
kvs = line.split(': ')
key, value = kvs[0], kvs[1]
rdict[key.lower()] = value #3
return rdict
parsed = [parse_block(block) for block in rblocks] #4
return parsed#1 Special decorator to denote the tool block #2 Splits the input and double new lines #3 Creates a dictionary entry and sets the value #4 Loops through each block and parses into key/value dictionary
We’re converting the recommendations output from listing 9.1, which is just a string, into a dictionary. So this code will convert this string into the JSON block shown next:
Before parsing:
"Title: The Butterfly Effect
Subject: 5
Format: 5
Genre: 4
Title: Primer
Subject: 5
Format: 5
Genre: 4
Title: Time Bandits
Subject: 5
Format: 5
Genre: 5"After parsing:
{
"title": " The Butterfly Effect
"subject": "5",
"format": "5",
"genre": "4"
},
{
"title": " Primer",
"subject": "5",
"format": "5",
"genre": "4"
},
{
"title": " Time Bandits",
"subject": "5",
"format": "5",
"genre": "5"
}The output of this parsing_results block now gets passed to the output and is wrapped in a list of recommendations. We can see what all this looks like by running the flow.
Open flow.dag.yaml for the flow in the visual editor, and click the Play (Run All) button. Be sure to select to use both recommender variants. You’ll see both variations run and output to the terminal.
At this point, we have a full working recommendation and LLM evaluation flow that outputs a score for each criterion on each output. However, to do comprehensive evaluations of a particular profile, we want to generate multiple recommendations with various criteria. We’ll see how to do batch processing of flows in the next section.
9.7.2 Running batch processing in prompt flow
In our generic recommendation profile, we want to evaluate how various input criteria can affect the generated recommendations. Fortunately, prompt flow can batch-process any variations we want to test. The limit is only the time and money we want to spend.
To perform batch processing, we must first create a JSON Lines (JSONL) or JSON list document of our input criteria. If you recall, our input criteria looked like the following in JSON format:
{
"subject": "time travel",
"format": "books",
"genre": "fantasy",
"custom": "don't include any R rated content"
}We want to create a list of JSON objects like that just shown, preferably in a random manner. Of course, the simple way to do this is to prompt ChatGPT to create a JSONL document using the following prompt:
I am developing a recommendation agent. The agent will recommend anything given the following criteria:
- subject - examples: time travel, cooking, vacation
- format examples: books, movies, games
- genre: documentary, action, romance
- custom: don’t include any R rated content
Can you please generate a random list of these criteria and output it in the format of a JSON Lines file, JSONL. Please include 10 items in the list.
Try this out by going to ChatGPT and entering the preceding prompt. A previously generated file can be found in the flow folder, called _recommend.jsonl. The contents of this file have been shown here for reference:
{
"subject": "time travel",
"format": "books",
"genre": "fantasy",
"custom": "don't include any R rated content"
}
{
"subject": "space exploration",
"format": "podcasts",
"genre": "sci-fi",
"custom": "include family-friendly content only"
}
{
"subject": "mystery",
"format": "podcasts",
"genre": "fantasy",
"custom": "don't include any R rated content"
}
{
"subject": "space exploration",
"format": "podcasts",
"genre": "action",
"custom": "include family-friendly content only"
}
{
"subject": "vacation",
"format": "books",
"genre": "thriller",
"custom": "don't include any R rated content"
}
{
"subject": "mystery",
"format": "books",
"genre": "sci-fi",
"custom": "don't include any R rated content"
}
{
"subject": "mystery",
"format": "books",
"genre": "romance",
"custom": "don't include any R rated content"
}
{
"subject": "vacation",
"format": "movies",
"genre": "fantasy",
"custom": "don't include any R rated content"
}
{
"subject": "cooking",
"format": "TV shows",
"genre": "thriller",
"custom": "include family-friendly content only"
}
{
"subject": "mystery",
"format": "movies",
"genre": "romance",
"custom": "include family-friendly content only"
}With this bulk file, we can run both variants using the various input criteria in the bulk JSONL file. Open the flow.dag.yaml file in the visual editor, click Batch (the beaker icon) to start the bulk-data loading process, and select the file as shown in figure 9.21. For some operating systems, this may appear as Local Data File.
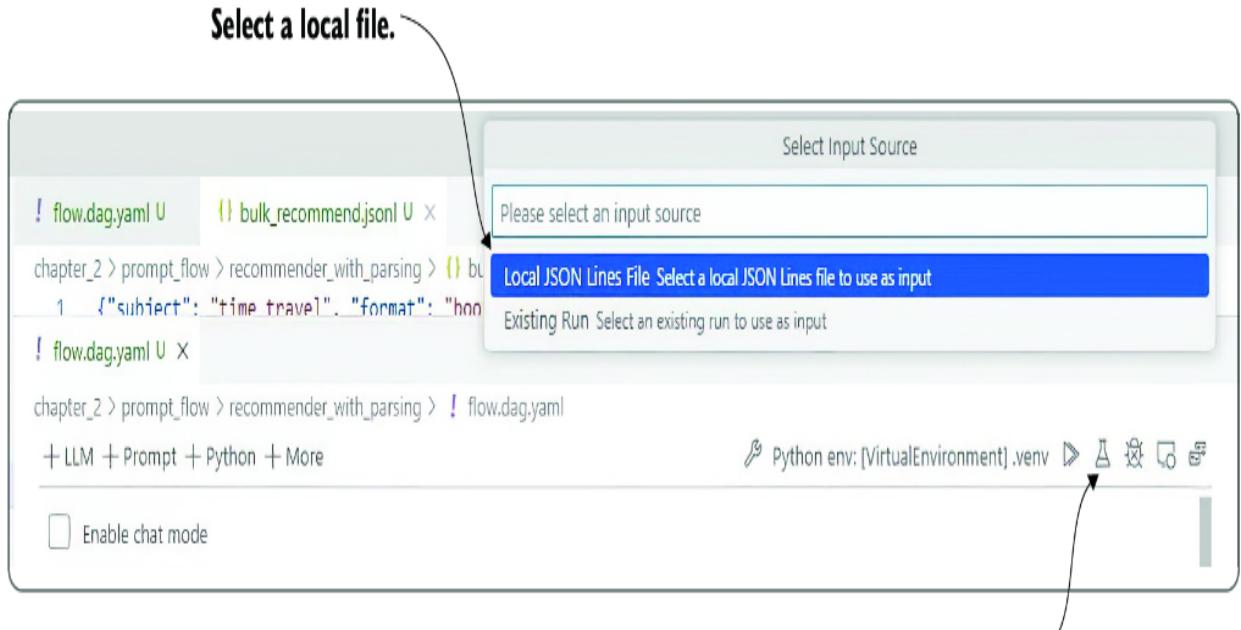
Figure 9.21 Loading the bulk JSONL file to run the flow on multiple input variations
After the bulk file is selected, a new YAML document will open with a Run link added at the bottom of the file, as shown in figure 9.22. Click the link to do the batch run of inputs.
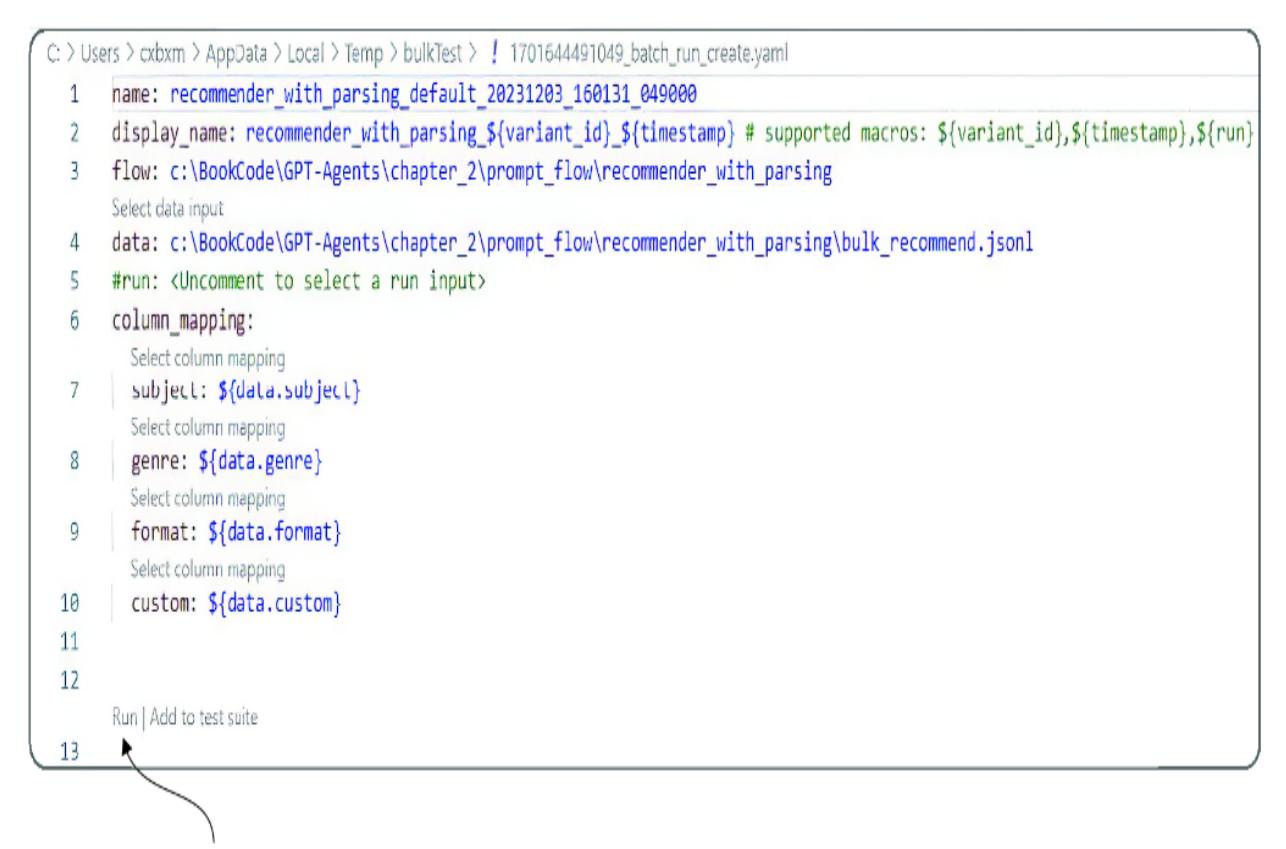
Figure 9.22 Running the batch run of inputs
At this point, a few things will happen. The flow visual editor will appear, and beside that a log file will open, showing the progress of the run. In the terminal window, you’ll see the various worker processes spawning and running.
Be patient. The batch run, even for 10 items, may take a few minutes or seconds, depending on various factors such as hardware, previous calls, and so on. Wait for the run to complete, and you’ll see a summary of results in the terminal.
You can also view the run results by opening the prompt flow extension and selecting the last run, as shown in figure 9.23. Then, you dig into each run by clicking the table cells. A lot of information is exposed in this dialog, which can help you troubleshoot flows and profiles.
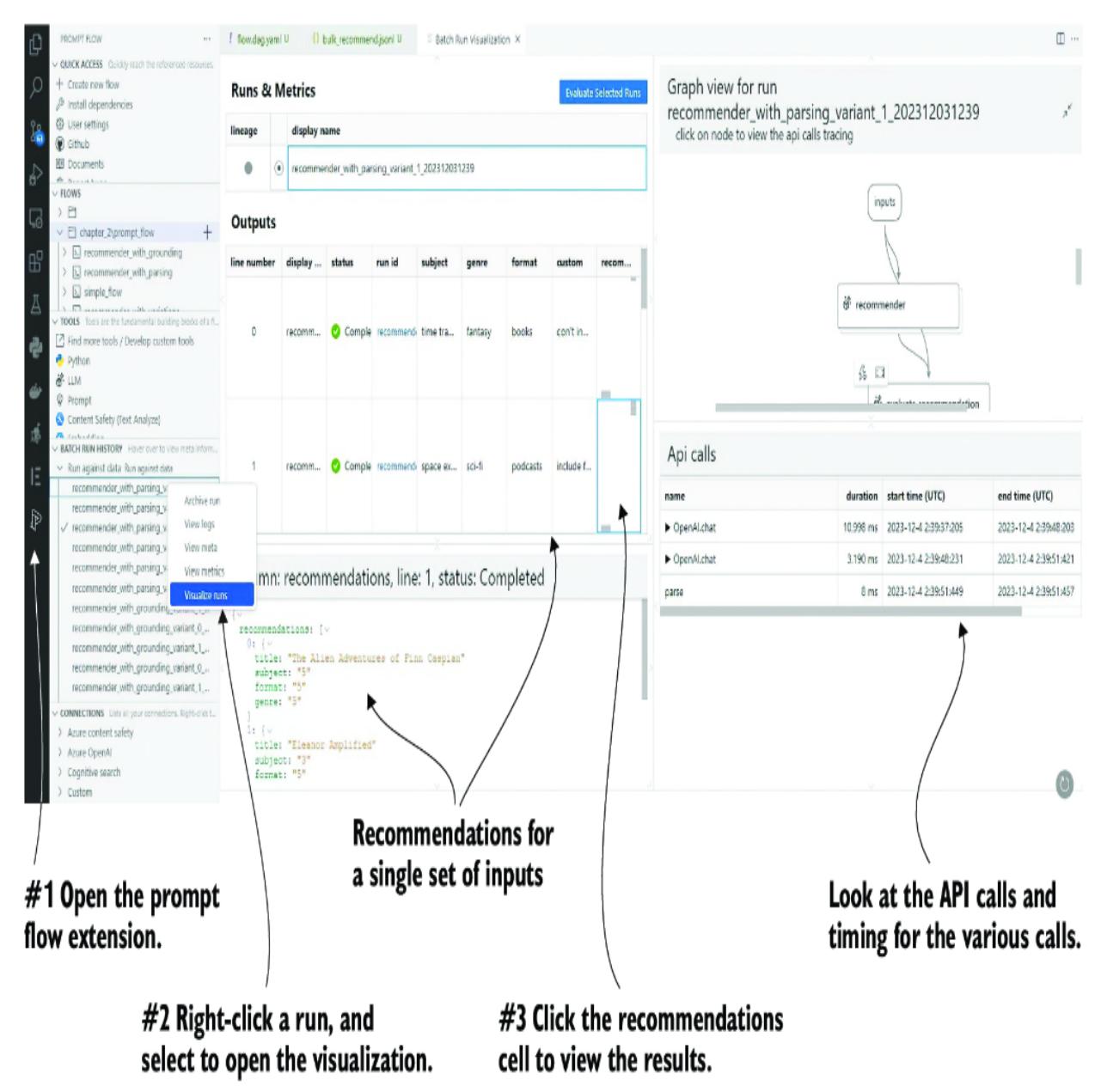
Figure 9.23 An opening run visualization and an examination of a batch run
A lot of information is captured during a batch run, and you can explore much of it through the visualizer. More information can be found by clicking the output folder link from the terminal window. This will open another session of VS Code with the output folder allowing you to review the run logs and other details.
Now that we’ve completed the batch run for each variant, we can apply grounding and evaluate the results of both prompts. The next section will use a new flow to perform the profile/prompt evaluation.
9.7.3 Creating an evaluation flow for grounding
Open chapter_3_flow_groundings.dag.yaml in the visual editor, as shown in figure 9.24. There are no LLM blocks in the evaluation flow—just Python code blocks that will run the scoring and then aggregate the scores.
| chapter_2 > prompt_flow > evaluate_groundings > flow.dag.yaml | |||
|---|---|---|---|
| \(+\) LLM \(+\) Prompt \(+\) Python \(+\) More | ♪ Python env: [VirtualEnvironment] .venv ▷ △ ※ Q ♂ | ||
| Enable chat mode | |||
| \(\rightarrow\) Inputs \(\mathcal{O}\) | inputs | ||
| > Outputs | |||
| ine_process D 2 | set as aggregation \(\triangleright\) \(\frac{1}{6}\) \(\triangleright\) \(\stackrel{\frown}{\mathbb{B}}\) \(\uparrow\) \(\downarrow\) \(\circledcirc\) | ||
| Code: line_process.py [9] | line_process block processes and | ||
| Inputs \(\vee\) | scores each recommendation. | ||
| Type Name |
Value | ||
| recommendations * string |
$(inputs.recommendations) | e line_process |
℗ |
| Seeing issues with the interface? Try: Regenerate with advanced options | Completed | ||
| Activate config > | |||
| Outputs & Logs Inputs Output |
|||
| 1 [1 success ] open in new tab | |||
| outputs | |||
| ø aggregate \(\Box\) |
\(\sqrt{}\) set as aggregation \(\sqrt{}\) \(\mathbb{D}\) \(\mathbb{D}\) \(\mathbb{T}\) \(\wedge\) \(\mathbb{D}\) \(\mathbb{D}\) | ||
| Code: aggregate.py [9] | aggregate block aggregates | ||
| Inputs \(\vee\) | the results of scoring. | ||
| Type Name |
Value | aggregate | ⊛ |
| processed_results * object |
${line_process.output} | Aggregation | |
| Seeing issues with the interface? Iry: Regenerate with advanced options | Completed | ||
| Activate config > | |||
| Outputs & Logs Inputs Output [1 success ] open in new tab |
Figure 9.24 Looking at the evaluate_groundings flow used to ground recommendation runs
We can now look at the code for the scoring and aggregate blocks, starting with the scoring code in listing 9.3. This scoring code averages the score for each criterion into an average score. The output of the function is a list of processed recommendations.
Listing 9.3 line_process.py
@tool
def line_process(recommendations: str): #1
inputs = recommendations
output = []
for data_dict in inputs: #2
total_score = 0
score_count = 0
for key, value in data_dict.items(): #2
if key != "title": #3
try:
total_score += float(value)
score_count += 1
data_dict[key] = float(value) #4
except:
pass
avg_score = total_score / score_count if score_count > 0 else 0
data_dict["avg_score"] = round(avg_score, 2) #5
output.append(data_dict)
return output#1 A set of three recommendations is input into the function. #2 Loops over each recommendation and criterion #3 Title isn’t a criterion, so ignore it. #4 Totals the score for all criteria and sets the float value to key #5 Adds the average score as a grounding score of the recommendation
From the grounded recommendations, we can move on to aggregating the scores with the aggregate block—the code for the aggregate block is shown in the following listing.
Listing 9.4 aggregate.py@tool
def aggregate(processed_results: List[str]):
items = [item for sublist in processed_results
↪ for item in sublist] #1
aggregated = {}
for item in items:
for key, value in item.items():
if key == 'title':
continue
if isinstance(value, (float, int)): #2
if key in aggregated:
aggregated[key] += value
else:
aggregated[key] = value
for key, value in aggregated.items(): #3
value = value / len(items)
log_metric(key=key, value=value) #4
aggregated[key] = value
return aggregated#1 The input is a list of lists; flatten to a list of items. #2 Checks to see if the value is numeric and accumulates scores for each criterion key #3 Loops over aggregated criterion scores #4 Logs the criterion as a metric
The result of the aggregations will be a summary score for each criterion and the average score. Since the evaluation/grounding flow is separate, it can be run over any recommendation run we perform. This will allow us to use the batch run results for any variation to compare results.
We can run the grounding flow by opening flow.dag.yaml in the visual editor and clicking Batch (beaker icon). Then, when prompted, we select an existing run and then select the run we want to evaluate, as shown in figure 9.25. This will open a YAML file with the Run link at the bottom, as we’ve seen before. Click the Run link to run the evaluation.
| Select Input Run | |||
|---|---|---|---|
| Please select a run to use as input | |||
| recommender_with_parsing_variant_1_20231203_130255_512000 (recommen (Run against data) | |||
| recommender_with_parsing_variant_0_20231203_130255_512000 (recommender_with_parsing_v | |||
Figure 9.25 Loading a previous run to be grounded and evaluated
After the run is completed, you’ll see a summary of the results in the terminal window. You can click the output link to open the folder in VS Code and analyze the results, but there is a better way to compare them.
Open the prompt flow extension, focus on the Batch Run History window, and scroll down to the Run against Run section, as shown in figure 9.26. Select the runs you want to compare—likely the ones near the top—so that the checkmark appears. Then, right-click the run, and select the Visualize Runs option. The Batch Run Visualization window opens, and you’ll see the metrics for each of the runs at the top.
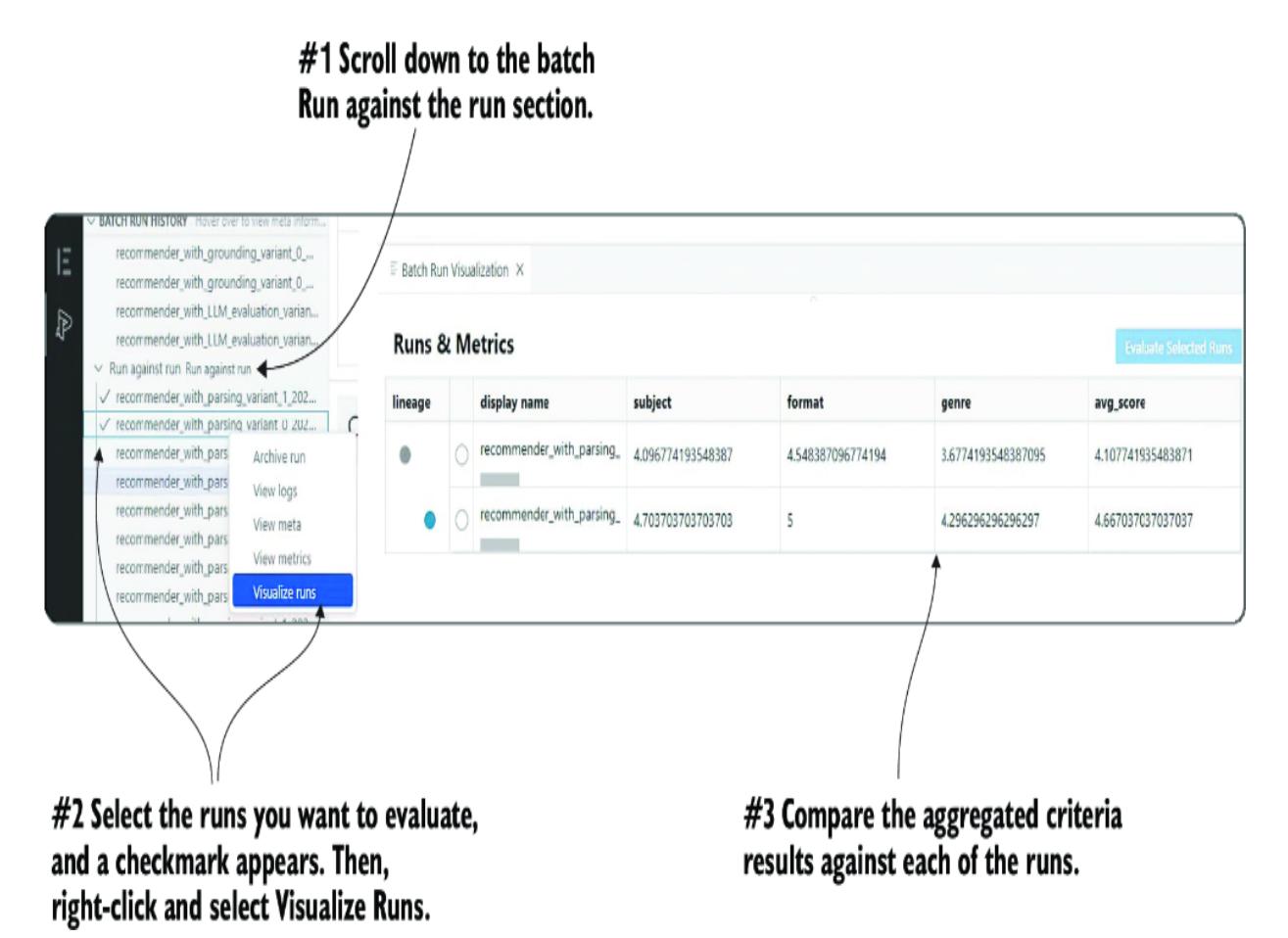
Figure 9.26 Visualizing the metrics for multiple runs and comparing them
We can now see a significant difference between profile/prompt variation 0, the user prompt, and variation 1, the system prompt. Refer to figure 9.15 if you need a refresher on what the prompts/profiles look like. At this point, it should be evident that injecting the input parameters into the system prompt provides better recommendations.
You can now go back and try other profiles or other variant options to see what effect this has on your recommendations. The possibilities are virtually endless, but hopefully you can see what an excellent tool prompt flow will be for building agent profiles and prompts.
9.7.4 Exercises
Use the following exercises to improve your knowledge of the material:
Exercise 1 —Create a New Prompt Variant for Recommender Flow (Intermediate)
Objective —Improve the recommendation results by creating and testing a new prompt variant in prompt flow.
Tasks:
- Create a new prompt variant for the recommender flow in prompt flow.
- Run the flow in batch mode.
- Evaluate the results to determine if they are better or worse compared to the original prompt.
- Exercise 2 —Add a Custom Field to the Rubric and Evaluate (Intermediate)
Objective —Enhance the evaluation criteria by incorporating a custom field into the rubric and updating the evaluation flow.
Tasks:
- Add the custom field as a new criterion to the rubric.
- Update the evaluation flow to score the new criterion.
- Evaluate the results, and analyze the effect of the new criterion on the evaluation.
- Exercise 3 —Develop a New Use Case and Evaluation Rubric (Advanced)
Objective —Expand the application of prompt engineering by developing a new use case and creating an evaluation rubric.
Tasks:
Develop a new use case aside from the recommendation.
Build the prompt for the new use case.
Create a rubric for evaluating the new prompt.
Update or alter the evaluation flow to aggregate and compare the results of the new use case with existing ones.
Exercise 4 —Evaluate Other LLMs Using LM Studio (Intermediate)
Objective —Assess the performance of different open source LLMs by hosting a local server with LM Studio.
Tasks:
- Use LM Studio to host a local server for evaluating LLMs.
- Evaluate other open source LLMs.
- Consult chapter 2 if assistance is needed for setting up the server and performing the evaluations.
- Exercise 5 —Build and Evaluate Prompts Using Prompt Flow (Intermediate)
Objective —Apply prompt engineering strategies to build and evaluate new prompts or profiles using prompt flow.
Tasks:
- Build new prompts or profiles for evaluation using prompt flow.
- Apply the Write Clear Instructions prompt engineering strategy from chapter 2.
- Evaluate the prompts and profiles using prompt flow.
- Refer to chapter 2 for tactics and implementation details if a refresher is needed.
Summary
An agent profile consists of several other component prompts that can drive functions such as actions/tools, knowledge, memory, evaluation, reasoning, feedback, and planning.
Prompt flow can be used to evaluate an agent’s component prompts.
Systemic prompt engineering is an iterative process evaluating a prompt and agent profile.
The Test Changes Systematically strategy describes iterating and evaluating prompts, and system prompt engineering implements this strategy.
Agent profiles and prompt engineering have many similarities. We define an agent profile as the combination of prompt engineering elements that guide and help an agent through its task.
Prompt flow is an open source tool from Microsoft that provides several features for developing and evaluating profiles and prompts.
An LLM connection in prompt flow supports additional parameters, including temperature, stop token, max tokens, and other advanced parameters.
LLM blocks support prompt and profile variants, which allow for evaluating changes to the prompt/profile or other connection parameters.
A rubric applied to an LLM prompt is the criteria and standards a prompt/profile must fulfill to be grounded. Grounding is the scoring and evaluation of a rubric.
Prompt flow supports running multiple variations as single runs or batch runs.
In prompt flow, an evaluation flow is run after a generative flow to score and aggregate the results. The Visualize Runs option can compare the aggregated criteria from scoring the rubric across multiple runs.
10 Agent reasoning and evaluation
This chapter covers
- Using various prompt engineering techniques to extend large language model functions
- Engaging large language models with prompt engineering techniques that engage reasoning
- Employing an evaluation prompt to narrow and identify the solution to an unknown problem
Now that we’ve examined the patterns of memory and retrieval that define the semantic memory component in agents, we can take a look at the last and most instrumental component in agents: planning. Planning encompasses many facets, from reasoning, understanding, and evaluation to feedback.
To explore how LLMs can be prompted to reason, understand, and plan, we’ll demonstrate how to engage reasoning through prompt engineering and then expand that to planning. The planning solution provided by the Semantic Kernel (SK) encompasses multiple planning forms. We’ll finish the chapter by incorporating adaptive feedback into a new planner.
Figure 10.1 demonstrates the high-level prompt engineering strategies we’ll cover in this chapter and how they relate to the various techniques we’ll cover. Each of the methods showcased in the figure will be explored in this chapter, from the basics of solution/direct prompting, shown in the top-left corner, to self-consistency and tree of thought (ToT) prompting, in the bottom right.
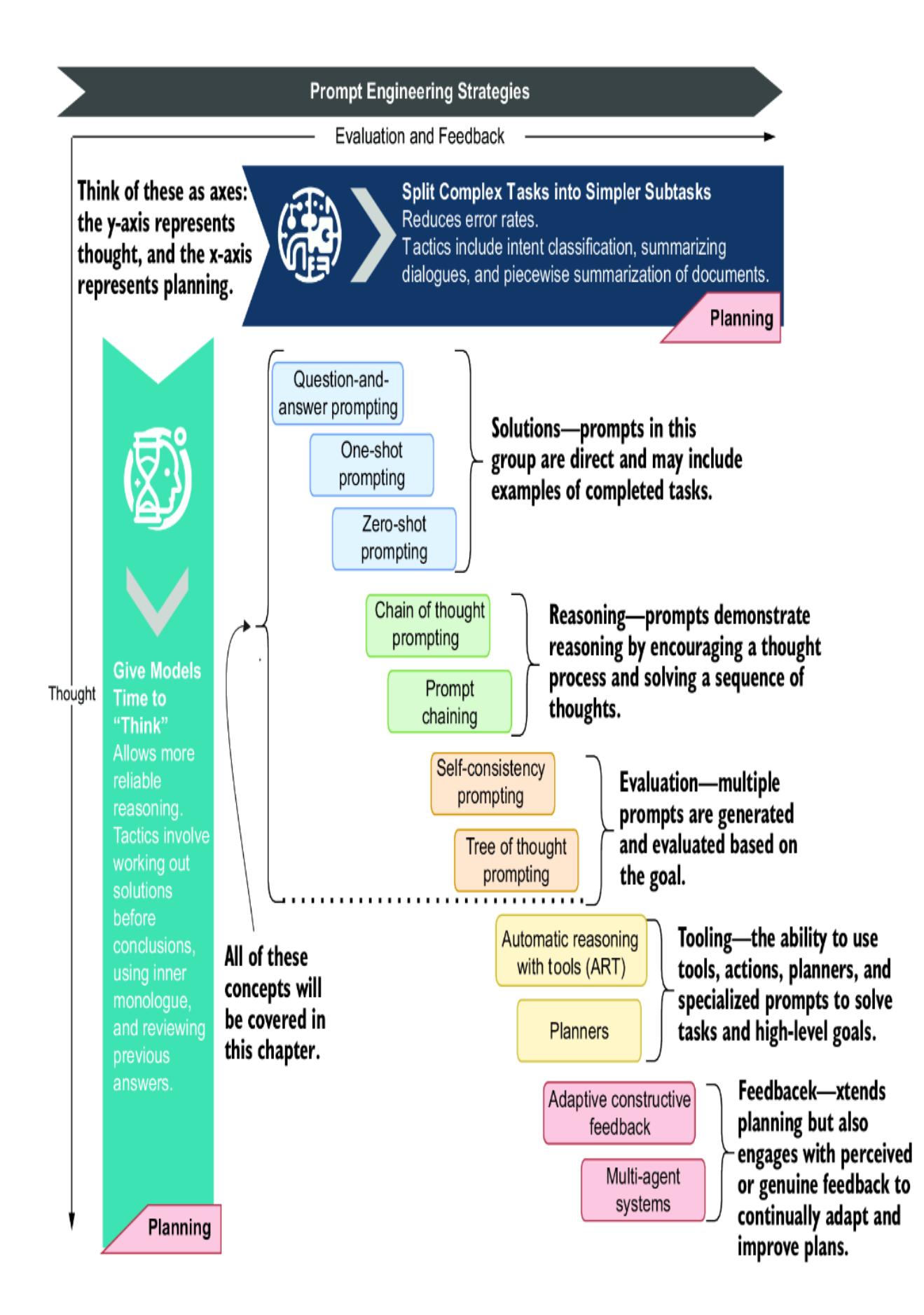
Figure 10.1 How the two planning prompt engineering strategies align with the various techniques
10.1 Understanding direct solution prompting
Direct solution prompting is generally the first form of prompt engineering that users employ when asking LLMs questions or solving a particular problem. Given any LLM use, these techniques may seem apparent, but they are worth reviewing to establish the foundation of thought and planning. In the next section, we’ll start from the beginning, asking questions and expecting answers.
10.1.1 Question-and-answer prompting
For the exercises in this chapter, we’ll employ prompt flow to build and evaluate the various techniques. (We already extensively covered this tool in chapter 9, so refer to that chapter if you need a review.) Prompt flow is an excellent tool for understanding how these techniques work and exploring the flow of the planning and reasoning process.
Open Visual Studio Code (VS Code) to the chapter 10 source folder. Create a new virtual environment for the folder, and install the requirements.txt file. If you need help setting up a chapter’s Python environment, refer to appendix B.
We’ll look at the first flow in the prompt_flow/question-answeringprompting folder. Open the flow.dag.yaml file in the visual editor, as shown in figure 10.2. On the right side, you’ll see the flow of components. At the top is the question_answer LLM prompt, followed by two Embedding components and a final LLM prompt to do the evaluation called evaluate.
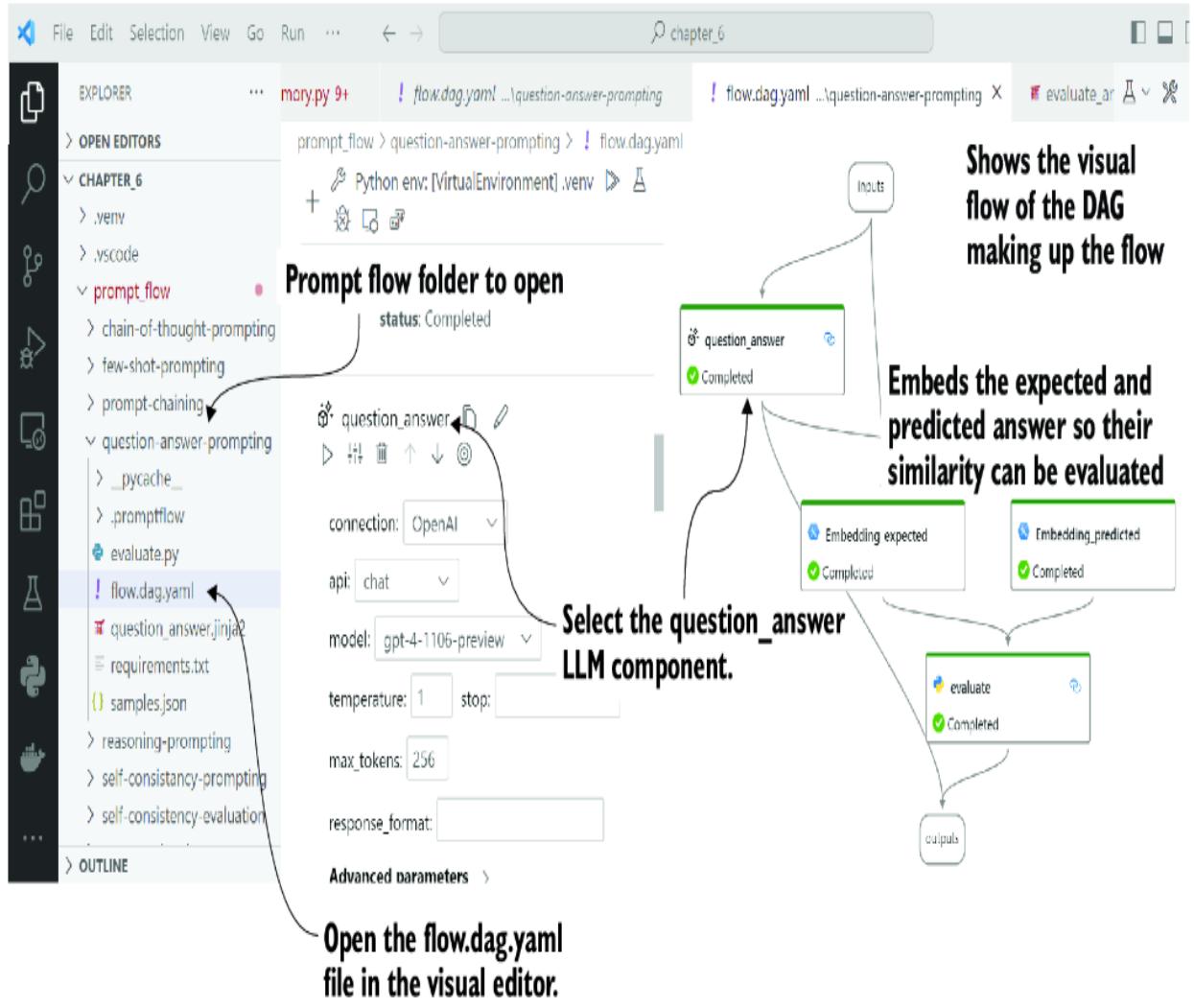
Figure 10.2 The flow.dag.yaml file, open in the visual editor, highlighting the various components of the flow
The breakdown in listing 10.1 shows the structure and components of the flow in more detail using a sort of YAML-shortened pseudocode. You can also see the input and outputs to the various components and a sample output from running the flow.
Listing 10.1 question-answer-prompting flow
Inputs:
context : the content to ask the question about
question : question asked specific to the content
expected : the expected answer
LLM: Question-Answer (the prompt used to ask the question)
inputs:
context and question
outputs:
the prediction/answer to the question
Embeddings: uses an LLM embedding model to create the embedding
representation of the text
Embedding_predicted: embeds the output of the Question-Answer LLM
Embedding_expected: embeds the output of the expected answer
Python: Evaluation (Python code to measure embedding similarity)
Inputs:
Embedding_predicted output
Embedding_expected output
Outputs:
the similarity score between predicted and expected
Outputs:
context: -> input.context
question: -> input.question
expected: -> input.expected
predicted: -> output.question_answer
evaluation_score: output.evaluation
### Example Output
{
"context": "Back to the Future (1985)…",
"evaluation_score": 0.9567478002354606,
"expected": "Marty traveled back in time 30 years.",
"predicted": "Marty traveled back in time 30 years from 1985 to 1955
in the movie \"Back to the Future.\"",
"question": "How far did Marty travel back in time in the movie
Back to the Future (1985)"
}Before running this flow, make sure your LLM block is configured correctly. This may require you to set up a connection to your chosen LLM. Again, refer to chapter 9 if you need a review on how to complete this. You’ll need to configure the LLM and Embedding blocks with your connection if you’re not using OpenAI.
After configuring your LLM connection, run the flow by clicking the Play button from the visual editor or using the Test (Shift-F5) link in the YAML editor window. If everything is connected and configured correctly, you should see output like that in listing 10.1.
Open the question_answer.jinja2 file in VS Code, as shown in listing 10.2. This listing shows the basic question-and-answer-style prompt. In this style of prompt, the system message describes the basic rules and provides the context to answer the question. In chapter 4, we explored the retrieval augmented generation (RAG) pattern, and this prompt follows a similar pattern.
Listing 10.2 question_answer.jinja2system:
Answer the users question based on the context below. Keep the answer
short and concise. Respond "Unsure about answer" if not sure about the
answer.
Context: {{context}} #1
user:
Question: {{question}} #2#1 Replace with the content LLM should answer the question about. #2 Replace with the question.
This exercise shows the simple method of using an LLM to ask questions about a piece of content. Then, the question response is evaluated using a similarity matching score. We can see from the output in listing 10.1 that the LLM does a good job of answering a question about the context. In the next section, we’ll explore a similar technique that uses direct prompting.
10.1.2 Implementing few-shot prompting
Few-shot prompting is like question-and-answer prompting, but the makeup of the prompt is more about providing a few examples than about facts or context. This allows the LLM to bend to patterns or content not previously seen. While this approach sounds like question and answer, the implementation is quite different, and the results can be powerful.
ZERO-SHOT, ONE-SHOT, AND FEW-SHOT LEARNING
One holy grail of machine learning and AI is the ability to train a model on as few items as possible. For example, in traditional vision models, millions of images are fed into the model to help identify the differences between a cat and a dog.
A one-shot model is a model that requires only a single image to train it. For example, a picture of a cat can be shown, and then the model can identify any cat image. A few-shot model requires only a few things to train the model. And, of course, zero-shot indicates the ability to identify something given no previous examples. LLMs are efficient learners and can do all three types of learning.
Open prompt_flow/few-shot-prompting/flow.dag.yaml in VS Code and the visual editor. Most of the flow looks like the one pictured earlier in figure 10.2, and the differences are highlighted in listing 10.3, which shows a YAML pseudocode representation. The main differences between this and the previous flow are the inputs and LLM prompt.
Listing 10.3 few-shot-prompting flow
Inputs:
statement : introduces the context and then asks for output
expected : the expected answer to the statement
LLM: few_shot (the prompt used to ask the question)
inputs:statement
outputs: the prediction/answer to the statement
Embeddings: uses an LLM embedding model to create the embedding
representation of the text
Embedding_predicted: embeds the output of the few_shot LLM
Embedding_expected: embeds the output of the expected answer
Python: Evaluation (Python code to measure embedding similarity)
Inputs:
Embedding_predicted output
Embedding_expected output
Outputs: the similarity score between predicted and expected
Outputs:
statement: -> input.statement
expected: -> input.expected
predicted: -> output.few_shot
evaluation_score: output.evaluation
### Example Output
{
"evaluation_score": 0.906647282920417, #1
"expected": "We ate sunner and watched the setting sun.",
"predicted": "After a long hike, we sat by the lake
and enjoyed a peaceful sunner as the sky turned
brilliant shades of orange and pink.", #2
"statement": "A sunner is a meal we eat in Cananda
at sunset, please use the word in a sentence" #3
}#1 Evaluation score represents the similarity between expected and predicted.
#2 Uses sunner in a sentence
#3 This is a false statement but the intent is to get the LLM to use the word as if it was real.Run the flow by pressing Shift-F5 or clicking the Play/Test button from the visual editor. You should see output like listing 10.3 where the LLM has used the word sunner (a made-up term) correctly in a sentence given the initial statement.
This exercise demonstrates the ability to use a prompt to alter the behavior of the LLM to be contrary to what it has learned. We’re changing what the LLM understands to be accurate. Furthermore, we then use that modified perspective to elicit the use of a made-up word.
Open the few_shot.jinja2 prompt in VS Code, shown in listing 10.4. This listing demonstrates setting up a simple persona, that of an eccentric dictionary maker, and then providing examples of words it has defined and used before. The base of the prompt allows for the LLM to extend the examples and produce similar results using other words.
Listing 10.4 few_shot.jinja2
system: You are an eccentric word dictionary maker. You will be asked to construct a sentence using the word. The following are examples that demonstrate how to craft a sentence using the word. A “whatpu” is a small, furry animal native to Tanzania. An example of a sentence that uses the word whatpu is: #1 We were traveling in Africa and we saw these very cute whatpus. To do a “farduddle” means to jump up and down really fast. An example of a sentence that uses the word farduddle is: I was so excited that I started to farduddle. #2 Please only return the sentence requested by the user. #3 user: {{statement}} #4
#1 Demonstrates an example defining a made-up word and using it in a sentence #2 Demonstrates another example #3 A rule to prevent the LLM from outputting extra information #4 The input statement defines a new word and asks for the use.
You may say we’re forcing the LLM to hallucinate here, but this technique is the basis for modifying behavior. It allows prompts to be constructed to guide an LLM to do everything contrary to what it learned. This foundation of prompting also establishes techniques for other forms of altered behavior. From the ability to alter the perception and background of an LLM, we’ll move on to demonstrate a final example of a direct solution in the next section.
10.1.3 Extracting generalities with zero-shot prompting
Zero-shot prompting or learning is the ability to generate a prompt in such a manner that allows the LLM to generalize. This generalization is embedded within the LLM and demonstrated through zero-shot prompting, where no examples are given, but instead a set of guidelines or rules are given to guide the LLM.
Employing this technique is simple and works well to guide the LLM to generate replies given its internal knowledge and no other contexts. It’s a subtle yet powerful technique that applies the knowledge of the LLM to other applications. This technique, combined with other prompting strategies, is proving effective at replacing other language classification models—models that identify the emotion or sentiment in text, for example.
Open prompt_flow/zero-shot-prompting/flow.dag.yaml in the VS Code prompt flow visual editor. This flow is again almost identical to that shown earlier in figure 10.1 but differs slightly in implementation, as shown in listing 10.5.
Listing 10.5 zero-shot-prompting flow Inputs:
statement : the statement to be classified
expected : the expected classification of the statement
LLM: zero_shot (the prompt used to classify)
inputs: statement
outputs: the predicted class given the statement
Embeddings: uses an LLM embedding model to create the embedding
representation of the text
Embedding_predicted: embeds the output of the zero_shot LLM
Embedding_expected: embeds the output of the expected answer
Python: Evaluation (Python code to measure embedding similarity)
Inputs:
Embedding_predicted output
Embedding_expected output
Outputs: the similarity score between predicted and expected
Outputs:
statement: -> input.statement
expected: -> input.expected
predicted: -> output.few_shot
evaluation_score: output.evaluation
### Example Output
{
"evaluation_score": 1, #1
"expected": "neutral",
"predicted": "neutral",
"statement": "I think the vacation is okay. " #2
}#1 Shows a perfect evaluation score of 1.0 #2 The statement we’re asking the LLM to classify Run the flow by pressing Shift-F5 within the VS Code prompt flow visual editor. You should see output similar to that shown in listing 10.5.
Now open the zero_shot.jinja2 prompt as shown in listing 10.6. The prompt is simple and uses no examples to extract the sentiment from the text. What is especially interesting to note is that the prompt doesn’t even mention the phrase sentiment, and the LLM seems to understand the intent.
Listing 10.6 zero_shot.jinja2
system:
Classify the text into neutral, negative or positive.
Return on the result and nothing else. #1
user:
{{statement}} #2#1 Provides essential guidance on performing the classification #2 The statement of text to classify
Zero-shot prompt engineering is about using the ability of the LLM to generalize broadly based on its training material. This exercise demonstrates how knowledge within the LLM can be put to work for other tasks. The LLM’s ability to self-contextualize and apply knowledge can extend beyond its training. In the next section, we extend this concept further by looking at how LLMs can reason.
10.2 Reasoning in prompt engineering
LLMs like ChatGPT were developed to function as chat completion models, where text content is fed into the model, whose responses align with completing that request. LLMs were never trained to reason, plan, think, or have thoughts.
However, much like we demonstrated with the examples in the previous section, LLMs can be prompted to extract their generalities and be extended beyond their initial design. While an LLM isn’t designed to reason, the training material fed into the model provides an understanding of reasoning, planning, and thought. Therefore, by extension, an LLM understands what reasoning is and can employ the concept of reasoning.
REASONING AND PLANNING
Reasoning is the ability of an intellect, artificial or not, to understand the process of thought or thinking through a problem. An intellect can understand that actions have outcomes, and it can use this ability to reason through which action from a set of actions can be applied to solve a given task.
Planning is the ability of the intellect to reason out the order of actions or tasks and apply the correct parameters to achieve a goal or outcome the extent to which an intellectual plan depends on the scope of the problem. An intellect may combine multiple levels of planning, from strategic and tactical to operational and contingent.
We’ll look at another set of prompt engineering techniques that allow or mimic reasoning behavior to demonstrate this reasoning ability. Typically, when evaluating the application of reasoning, we look to having the LLM solve challenging problems it wasn’t designed to solve. A good source of such is based on logic, math, and word problems.
Using the time travel theme, what class of unique problems could be better to solve than understanding time travel? Figure 10.3 depicts one example of a uniquely challenging time travel problem. Our goal is to acquire the ability to prompt the LLM in a manner that allows it to solve the problem correctly.
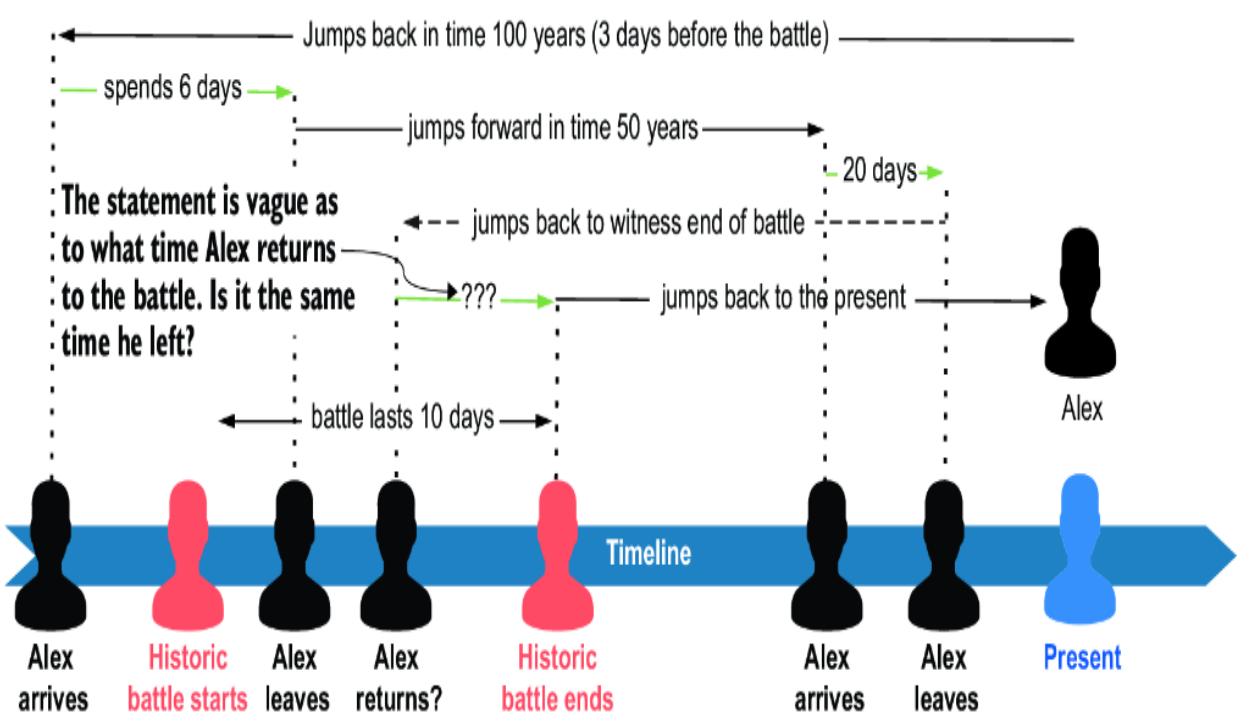
Figure 10.3 The complexity of the time travel problems we intend to solve using LLMs with reasoning and planning
Time travel problems are thought exercises that can be deceptively difficult to solve. The example in figure 10.3 is complicated to solve for an LLM, but the part it gets wrong may surprise you. The next section will use reasoning in prompts to solve these unique problems.
10.2.1 Chain of thought prompting
Chain of thought (CoT)prompting is a prompt engineering technique that employs the one-shot or few-shot examples that describe the reasoning and the steps to accomplish a desired goal. Through the demonstration of reasoning, the LLM can generalize this principle and reason through similar problems and goals. While the LLM isn’t trained with the goal of reasoning, we can elicit the model to reason, using prompt engineering.
Open prompt_flow/chain-of-thought-prompting/flow.dag.yaml in the VS Code prompt flow visual editor. The elements of this flow are simple, as shown in figure 10.4. With only two LLM blocks, the flow first uses a CoT prompt to solve a complex question; then, the second LLM prompt evaluates the answer.
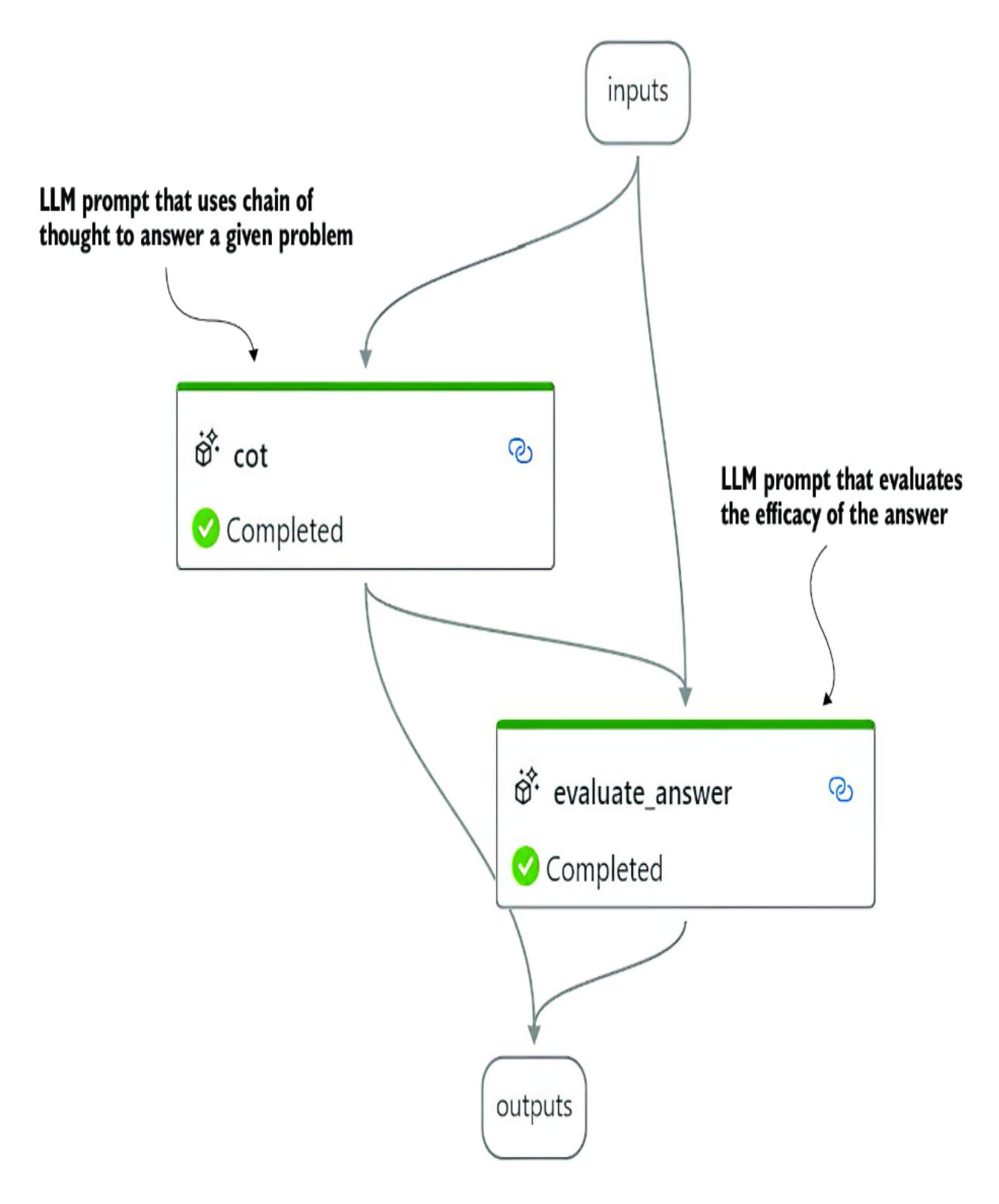
Figure 10.4 The flow of the CoT
Listing 10.7 shows the YAML pseudocode that describes the blocks and the inputs/outputs of the flow in more detail. The default problem statement in this example isn’t the same as in figure 10.3.
Listing 10.7 chain-of-thought-prompting flow
Inputs:
statement : the statement problem to be solved
expected : the expected solution to the problem
LLM: cot (the prompt used to solve the problem)
inputs: statement
outputs: the predicted answer given the problem statement
LLM: evaluate_answer (the prompt used to evaluate the solution)
inputs:
statement: -> input.statement
expected: -> input.expected
predicted: -> output.cot
outputs: a score of how well the problem was answered
Outputs:
statement: -> input.statement
expected: -> input.expected
predicted: -> output.cot
evaluation_score: output.evaluate_answer
### Example Output
{
"evaluation_score": "0.5", #1
"expected": "After the final jump, Max finds himself
in the year 1980 and he is 75 years old.", #2
"predicted": " Max starts in the year 2300 and
travels backward in 40-year increments, spending 5 years
in each period. The journeys will be as follows:
\n\n- From 2300 to 2260: Max is 25 + 5 = 30 years old.
\n- From 2260 to 2220: Max is 30 + 5 = 35 years old.
\n- From 2220 to 2180: Max is 35 + 5 = 40 years old.
\n- From 2180 to 2140: Max is 40 + 5 = 45 years old.
\n- From 2140 to 2100: Max is 45 + 5 = 50 years old.
\n- From 2100 to 2060: Max is 50 + 5 = 55 years old.
\n- From 2060 to 2020: Max is 55 + 5 = 60 years old.
\n- From 2020 to 1980: Max is 60 + 5 = 65 years old.
\n- From 1980 to 1940: Max is 65 + 5 = 70 years old.
\n- From 1940 to 1900: Max is 70 + 5" #3
}#1 The evaluated score for the given solution
#2 The expected answer for the problem
#3 The predicted answer shows the reasoning steps and output.Dig into the inputs and check the problem statement; try to evaluate the problem yourself. Then, run the flow by pressing Shift-F5. You should see output similar to that shown in listing 10.7.
Open the cot.jinja2 prompt file as shown in listing 10.8. This prompt gives a few examples of time travel problems and then the thought-out and reasoned solution. The process of showing the LLM the steps to complete the problem provides the reasoning mechanism.
Listing 10.8 cot.jinja2
system: “In a time travel movie, Sarah travels back in time to prevent a historic event from happening. She arrives 2 days before the event. After spending a day preparing, she attempts to change the event but realizes she has actually arrived 2 years early, not 2 days. She then decides to wait and live in the past until the event’s original date. How many days does Sarah spend in the past before the day of the event?” #1 Chain of Thought: #2 Initial Assumption: Sarah thinks she has arrived 2 days before the event. Time Spent on Preparation: 1 day spent preparing. Realization of Error: Sarah realizes she’s actually 2 years early. Conversion of Years to Days: 2 years = 2 × 365 = 730 days (assuming non-leap years). Adjust for the Day Spent Preparing: 730 - 1 = 729 days. Conclusion: Sarah spends 729 days in the past before the day of the event. “In a sci-fi film, Alex is a time traveler who decides to go back in time to witness a famous historical battle that took place 100 years ago, which lasted for 10 days. He arrives three days before the battle starts. However, after spending six days in the past, he jumps forward in time by 50 years and stays there for 20 days. Then, he travels back to witness the end of the battle. How many days does Alex spend in the past before he sees the end of the battle?” #3 Chain of Thought: #4 Initial Travel: Alex arrives three days before the battle starts. Time Spent Before Time Jump: Alex spends six days in the past. The battle has started and has been going on for 3 days (since he arrived 3 days early and has now spent 6 days, 3 + 3 = 6). First Time Jump: Alex jumps 50 years forward and stays for 20 days. This adds 20 days to the 6 days he’s already spent in the past (6 + 20 = 26). Return to the Battle: When Alex returns, he arrives back on the same day he left (as per time travel logic). The battle has been going on for 3 days now. Waiting for the Battle to End: The battle lasts 10 days. Since he’s already witnessed 3 days of it, he needs to wait for 7 more days. Conclusion: Alex spends a total of 3 (initial wait) + 3 (before the first jump) + 20 (50 years ago) + 7 (after returning) = 33 days in the past before he sees the end of the battle. Think step by step but only show the final answer to the statement. user: {{statement}} #5
#1 A few example problem statements
#2 The solution to the problem statement, output as a sequence of reasoning steps #3 A few example problem statements
#4 The solution to the problem statement, output as a sequence of reasoning steps #5 The problem statement the LLM is directed to solve
You may note that the solution to figure 10.3 is also provided as an example in listing 10.8. It’s also helpful to go back and review listing 10.7 for the reply from the LLM about the problem. From this, you can see the reasoning steps the LLM applied to get its final answer.
Now, we can look at the prompt that evaluates how well the solution solved the problem. Open evaluate_answer.jinja2, shown in listing 10.9, to review the prompt used. The prompt is simple, uses zero-shot prompting, and allows the LLM to generalize how it should score the expected and predicted. We could provide examples and scores, thus changing this to an example of a few-shot classification.
Listing 10.9 evaluate_answer.jinja2
system: Please confirm that expected and predicted results are the same for the given problem. #1 Return a score from 0 to 1 where 1 is a perfect match and 0 is no match. Please just return the score and not the explanation. #2 user: Problem: {{problem}} #3 Expected result: {{expected}} #4 Predicted result: {{predicted}} #5
#1 The rules for evaluating the solution #2 Direction to only return the score and nothing else #3 The initial problem statement #4 The expected or grounded answer #5 The output from the CoT prompt earlier
Looking at the LLM output shown earlier in listing 10.7, you can see why the evaluation step may get confusing. Perhaps a fix to this could be suggesting to the LLM to provide the final answer in a single statement. In the next section, we move on to another example of prompt reasoning.
10.2.2 Zero-shot CoT prompting
As our time travel demonstrates, CoT prompting can be expensive in terms of prompt generation for a specific class of problem. While not as effective, there are techniques similar to CoT that don’t use examples and
can be more generalized. This section will examine a straightforward phrase employed to elicit reasoning in LLMs.
Open prompt_flow/zero-shot-cot-prompting/flow.dag.yaml in the VS Code prompt flow visual editor. This flow is very similar to the previous CoT, as shown in figure 10.4. The next lsting shows the YAML pseudocode that describes the flow.
Listing 10.10 zero-shot-CoT-prompting flow
Inputs:
statement : the statement problem to be solved
expected : the expected solution to the problem
LLM: cot (the prompt used to solve the problem)
inputs: statement
outputs: the predicted answer given the problem statement
LLM: evaluate_answer (the prompt used to evaluate the solution)
inputs:
statement: -> input.statement
expected: -> input.expected
predicted: -> output.cot
outputs: a score of how well the problem was answered
Outputs:
statement: -> input.statement
expected: -> input.expected
predicted: -> output.cot
evaluation_score: output.evaluate_answer
### Example Output
{
"evaluation_score": "1", #1
"expected": "After the final jump, ↪
↪ Max finds himself in the year 1980 and
he is 75 years old.", #2
"predicted": "Max starts in… ↪
↪ Therefore, after the final jump, ↪
↪ Max is 75 years old and in the year 1980.", #3
"statement": "In a complex time travel …" #4
}
#1 The final evaluation score#2 The expected answer
#3 The predicted answer (the steps have been omitted showing the final answer) #4 The initial problem statement
Run/test the flow in VS Code by pressing Shift-F5 while in the visual editor. The flow will run, and you should see output similar to that shown in listing 10.10. This exercise example performs better than the previous example on the same problem.
Open the cot.jinja2 prompt in VS Code, as shown in listing 10.11. This is a much simpler prompt than the previous example because it only uses zero-shot. However, one key phrase turns this simple prompt into a powerful reasoning engine. The line in the prompt Let’s think step by step triggers the LLM to consider internal context showing reasoning. This, in turn, directs the LLM to reason out the problem in steps.
Listing 10.11 cot.jinja2
system: You are an expert in solving time travel problems. You are given a time travel problem and you have to solve it. Let’s think step by step. #1 Please finalize your answer in a single statement. #2 user: {{statement}} #3
#1 A magic line that formulates reasoning from the LLM #2 Asks the LLM to provide a final statement of the answer #3 The problem statement the LLM is asked to solve
Similar phrases asking the LLM to think about the steps or asking it to respond in steps also extract reasoning. We’ll demonstrate a similar but more elaborate technique in the next section.
10.2.3 Step by step with prompt chaining
We can extend the behavior of asking an LLM to think step by step into a chain of prompts that force the LLM to solve the problem in steps. In this section, we look at a technique called prompt chaining that forces an LLM to process problems in steps.
Open the prompt_flow/prompt-chaining/flow.dag.yaml file in the visual editor, as shown in figure 10.5. Prompt chaining breaks up the reasoning method used to solve a problem into chains of prompts. This technique forces the LLM to answer the problem in terms of steps.
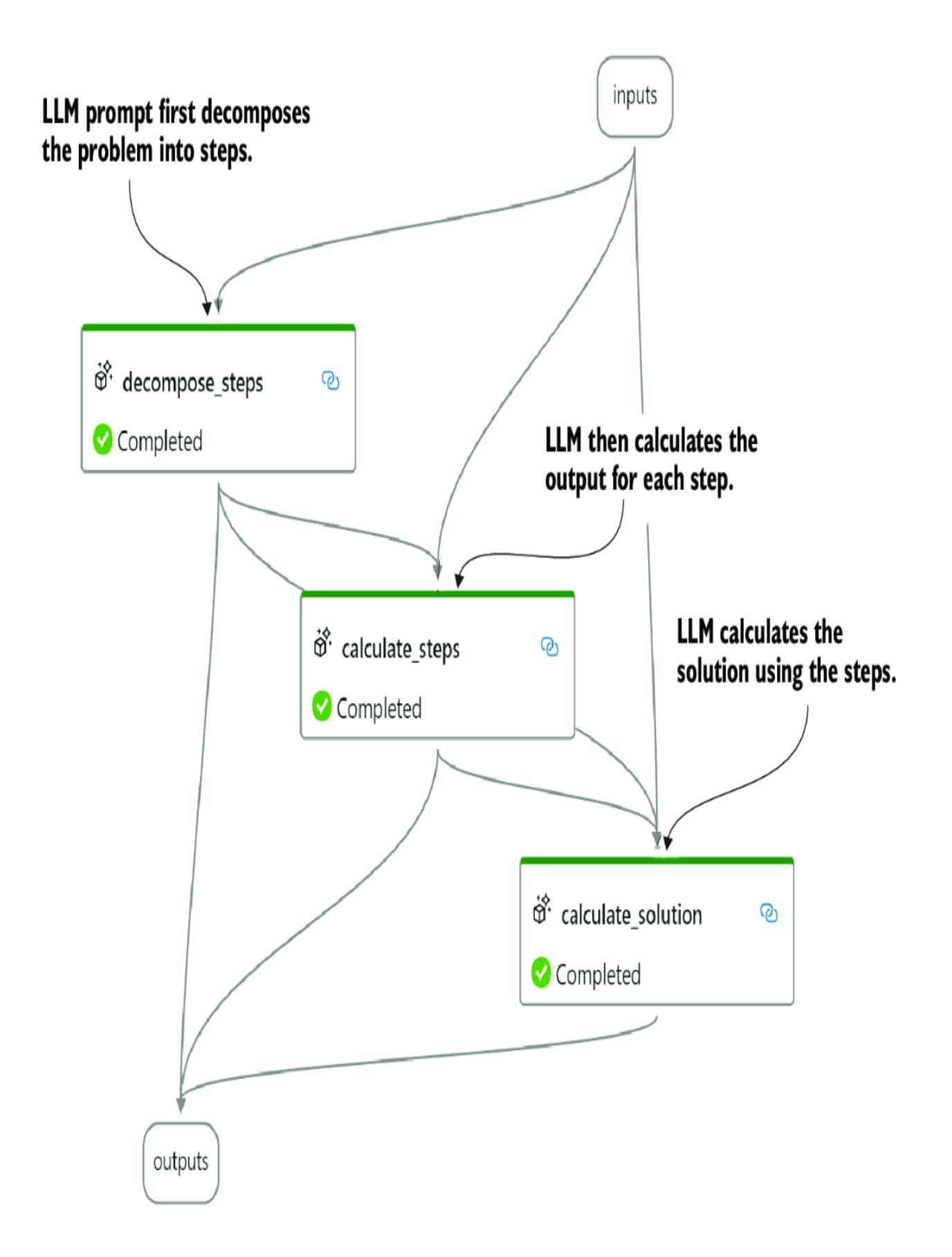
Figure 10.5 The prompt chaining flow
Listing 10.12 shows the YAML pseudocode that describes the flow in a few more details. This flow chains the output of the first LLM block into the second and then from the second into the third. Forcing the LLM to process the problem this way uncovers the reasoning pattern, but it can also be overly verbose.
Listing 10.12 prompt-chaining flow
Inputs:
statement : the statement problem to be solved
LLM: decompose_steps (the prompt used to decompose the problem)
inputs:
statement: -> input.statement #1
outputs: the breakdown of steps to solve the problem
LLM: calculate_steps (the prompt used to calculate the steps)
inputs:
statement: -> input.statement
decompose_steps: -> output.decompose_steps #2
outputs: the calculation for each step
LLM: calculate_solution (attempts to solve the problem)
inputs:
statement: -> input.statement
decompose_steps: -> output.decompose_steps
calculate_steps: -> output.calculate_steps #3
outputs: the final solution statement
Outputs:
statement: -> input.statement
decompose_steps: -> output.decompose_steps
calculate_steps: -> output.calculate_steps
calculate_solution: -> output.calculate_solution
### Example Output
{
"calculate_steps": "1. The days spent by Alex",
"decompose_steps": "To figure out the …",
"solution": "Alex spends 13 days in the ↪
↪ past before the end of the battle.", #4
"statement": "In a sci-fi film, Alex …"
}#1 Start of the chain of prompts #2 Output from the previous step injected into this step #3 Output from two previous steps injected into this step #4 The final solution statement, although wrong, is closer.
Run the flow by pressing Shift-F5 from the visual editor, and you’ll see the output as shown in listing 10.12. The answer is still not correct for the Alex problem, but we can see all the work the LLM is doing to reason out the problem.
Open up all three prompts: decompose_steps.jinja2,
calculate_steps.jinja2, and calculate_solution.jinja2 (see listings 10.13, 10.14, and 10.15, respectively). All three prompts shown in the listings can be compared to show how outputs chain together.
Listing 10.13 decompose_steps.jinja2
system: You are a problem solving AI assistant. Your job is to break the users problem down into smaller steps and list the steps in the order you would solve them. Think step by step, not in generalities. Do not attempt to solve the problem, just list the steps. #1 user:
{{statement}} #2
#1 Forces the LLM to list only the steps and nothing else #2 The initial problem statement
Listing 10.14 calculate_steps.jinja2
system: You are a problem solving AI assistant. You will be given a list of steps that solve a problem. Your job is to calculate the output for each of the steps in order. Do not attempt to solve the whole problem, just list output for each of the steps. #1 Think step by step. #2 user: {{statement}}
{{steps}} #3
#1 Requests that the LLM not solve the whole problem, just the steps #2 Uses the magic statement to extract reasoning #3 Injects the steps produced by the decompose_steps step
Listing 10.15 calculate_solution.jinja2
system:
You are a problem solving AI assistant.
You will be given a list of steps and the calculated output for each step.
Use the calculated output from each step to determine the final
solution to the problem.
Provide only the final solution to the problem in a
single concise sentence. Do not include any steps
in your answer. #1
user:
{{statement}}
{{steps}} #2
{{calculated}} #3#1 Requests that the LLM output the final answer and not any steps #2 The decomposed steps #3 The calculated steps
In this exercise example, we’re not performing any evaluation and scoring. Without the evaluation, we can see that this sequence of prompts still has problems solving our more challenging time travel problem shown earlier in figure 10.3. However, that doesn’t mean this technique doesn’t have value, and this prompting format solves some complex problems well.
What we want to find, however, is a reasoning and planning methodology that can solve such complex problems consistently. The following section moves from reasoning to evaluating the best solution.
10.3 Employing evaluation for consistent solutions
In the previous section, we learned that even the best-reasoned plans may not always derive the correct solution. Furthermore, we may not always have the answer to confirm if that solution is correct. The reality is that we often want to use some form of evaluation to determine the efficacy of a solution.
Figure 10.6 shows a comparison of the prompt engineering strategies that have been devised as a means of getting LLMs to reason and plan. We’ve already covered the two on the left: zero-shot direct prompting and CoT
prompting. The following example exercises in this section will look at self-consistency with the CoT and ToT techniques.
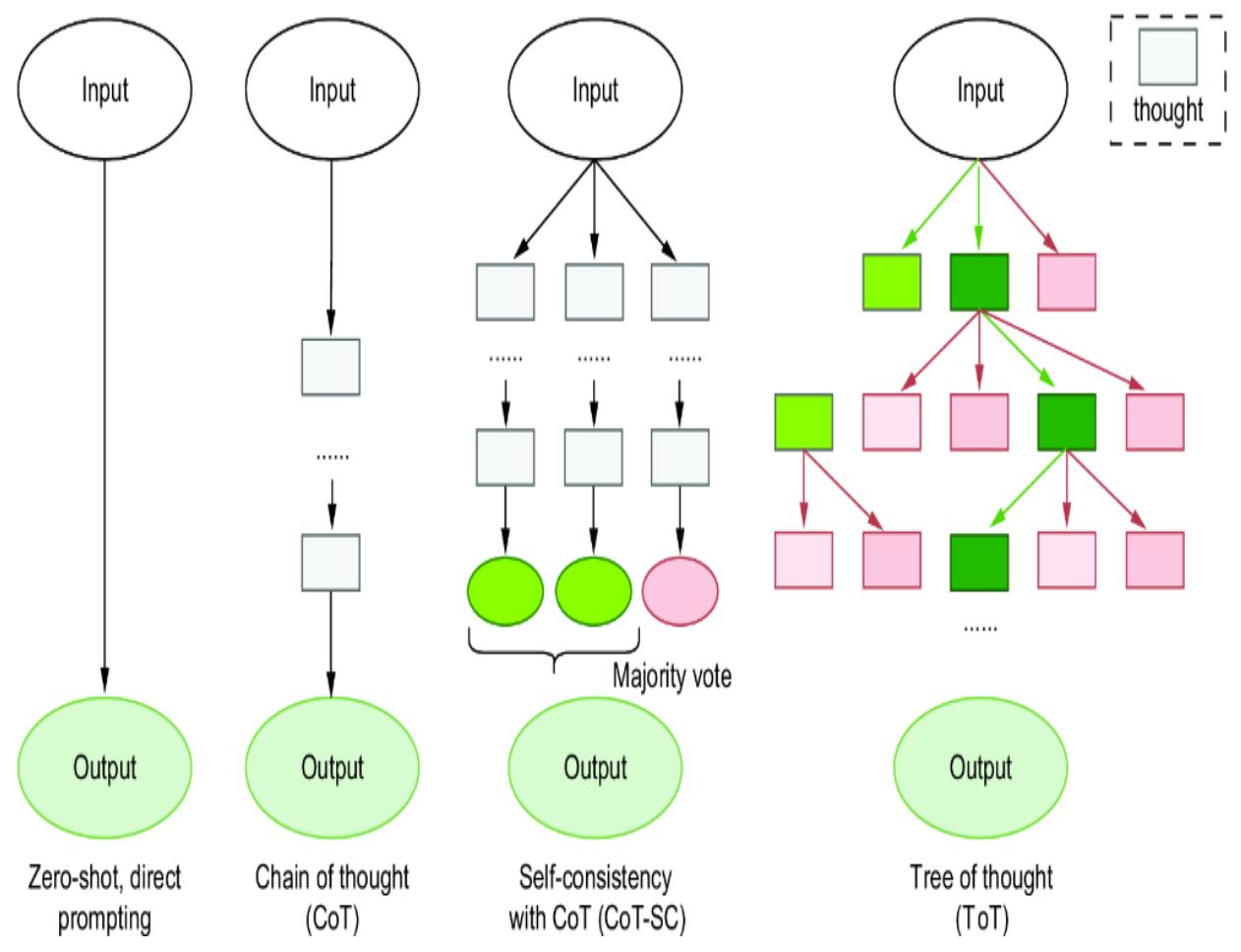
Figure 10.6 Comparing the various prompt engineering strategies to enable reasoning and planning from LLMs
We’ll continue to focus on the complex time travel problem to compare these more advanced methods that expand on reasoning and planning with evaluation. In the next section, we’ll evaluate self-consistency.
10.3.1 Evaluating self-consistency prompting
Consistency in prompting is more than just lowering the temperature parameter we send to an LLM. Often, we want to generate a consistent plan or solution and still use a high temperature to better evaluate all the variations to a plan. By evaluating multiple different plans, we can get a better sense of the overall value of a solution.
Self-consistent prompting is the technique of generating multiple plans/solutions for a given problem. Then, those plans are evaluated, and the more frequent or consistent plan is accepted. Imagine three plans generated, where two are similar, but the third is different. Using selfconsistency, we evaluate the first two plans as the more consistent answer.
Open prompt_flow/self-consistency-prompting/flow.dag.yaml in the VS Code prompt flow visual editor. The flow diagram shows the simplicity of the prompt generation flow in figure 10.7. Next to it in the diagram is the self-consistency evaluation flow.
Figure 10.7 The self-consistency prompt generation beside the evaluation flow
Prompt flow uses a direct acyclic graph (DAG) format to execute the flow logic. DAGs are an excellent way of demonstrating and executing flow logic, but because they are acyclic, meaning they can’t repeat, they can’t
execute loops. However, because prompt flow provides a batch processing mechanism, we can use that to simulate loops or repetition in a flow.
Referring to figure 10.6, we can see that self-consistency processes the input three times before collecting the results and determining the best plan/reply. We can apply this same pattern but use batch processing to generate the outputs. Then, the evaluation flow will aggregate the results and determine the best answer.
Open the self-consistency-prompting/cot.jinja2 prompt template in VS Code (see listing 10.16). The listing was shortened, as we’ve seen parts before. This prompt uses two (few-shot prompt) examples of a CoT to demonstrate the thought reasoning to the LLM.
Listing 10.16 self-consistency-prompting/cot.jinja2
system: “In a time travel movie, Sarah travels back…” #1 Chain of Thought: Initial Assumption: … #2 Conclusion: Sarah spends 729 days in the past before the day of the event. “In a complex time travel movie plot, Max, a 25 year old…” #3 Chain of Thought: Starting Point: Max starts … #4 Conclusion: After the final jump, Max finds himself in the year 1980 and he is 75 years old. Think step by step, but only show the final answer to the statement. #5 user: {{statement}}
#1 The Sarah time travel problem #2 Sample CoT, cut for brevity #3 The Max time travel problem #4 Sample CoT, cut for brevity #5 Final guide and statement to constrain output
Open the self-consistency-prompting/flow.dag.yaml file in VS Code. Run the example in batch mode by clicking Batch Run (the beaker icon) from the visual editor. Figure 10.8 shows the process step by step:
- Click Batch Run.
- Select the JSON Lines (JSONL) input.
- Select statements.jsonl.
- Click the Run link.

TIP If you need to review the process, refer to chapter 9, which covers this process in more detail.
Listing 10.17 shows the JSON output from executing the flow in batch mode. The statements.jsonl file has five identical Alex time travel problem entries. Using identical entries allows us to simulate the prompt executing five times on the duplicate entry.
Listing 10.17 self-consistency-prompting batch execution output
{
"name": "self-consistency-prompting_default_20240203_100322_912000",
"created_on": "2024-02-03T10:22:30.028558",
"status": "Completed",
"display_name": "self-consistency-prompting_variant_0_202402031022",
"description": null,
"tags": null,
"properties": {
"flow_path": "…prompt_flow/self-consistency-prompting", #1
"output_path": "…/.promptflow/.runs/self-
↪ consistency-prompting_default_20240203_100322_912000", #2
"system_metrics": {
"total_tokens": 4649,
"prompt_tokens": 3635,
"completion_tokens": 1014,
"duration": 30.033773
}
},
"flow_name": "self-consistency-prompting",
"data": "…/prompt_flow/self-consistency-prompting/
↪ statements.jsonl", #3
"output": "…/.promptflow/.runs/self-consistency-↪
↪ prompting_default_20240203_100322_912000/flow_outputs"
}#1 The path where the flow was executed from
#2 The folder containing the outputs of the flow (note this path)
#3 The data used to run the flow in batchYou can view the flow produced by pressing the Ctrl key and clicking the output link, highlighted in listing 10.17. This will open another instance of VS Code, showing a folder with all the output from the run. We now want to check the most consistent answer. Fortunately, the evaluation feature in prompt flow can help us identify consistent answers using similarity matching.
Open self-consistency-evaluation/flow.dag.yaml in VS Code (see figure 10.7). This flow embeds the predicted answer and then uses an aggregation to determine the most consistent answer.
From the flow, open consistency.py in VS Code, as shown in listing 10.18. The code for this tool function calculates the cosine similarity for all pairs of answers. Then, it finds the most similar answer, logs it, and outputs that as the answer.
Listing 10.18 consistency.pyfrom promptflow import tool
from typing import List
import numpy as np
from scipy.spatial.distance import cosine
@tool
def consistency(texts: List[str],
embeddings: List[List[float]]) -> str:
if len(embeddings) != len(texts):
raise ValueError("The number of embeddings ↪
↪ must match the number of texts.")
mean_embedding = np.mean(embeddings, axis=0) #1
similarities = [1 - cosine(embedding, mean_embedding) ↪
↪ for embedding in embeddings] #2
most_similar_index = np.argmax(similarities) #3
from promptflow import log_metric
log_metric(key="highest_ranked_output", value=texts[most_similar_index]) #4
return texts[most_similar_index] #5#1 Calculates the mean of all the embeddings #2 Calculates cosine similarity for each pair of embeddings #3 Finds the index of the most similar answer #4 Logs the output as a metric #5 Returns the text for the most similar answer
We need to run the evaluation flow in batch mode as well. Open selfconsistency-evaluation/flow.dag.yaml in VS Code and run the flow in batch mode (beaker icon). Then, select Existing Run as the flow input, and when prompted, choose the top or the last run you just executed as input.
Again, after the flow completes processing, you’ll see an output like that shown in listing 10.17. Ctrl-click on the output folder link to open a new instance of VS Code showing the results. Locate and open the metric.json file in VS Code, as shown in figure 10.9.
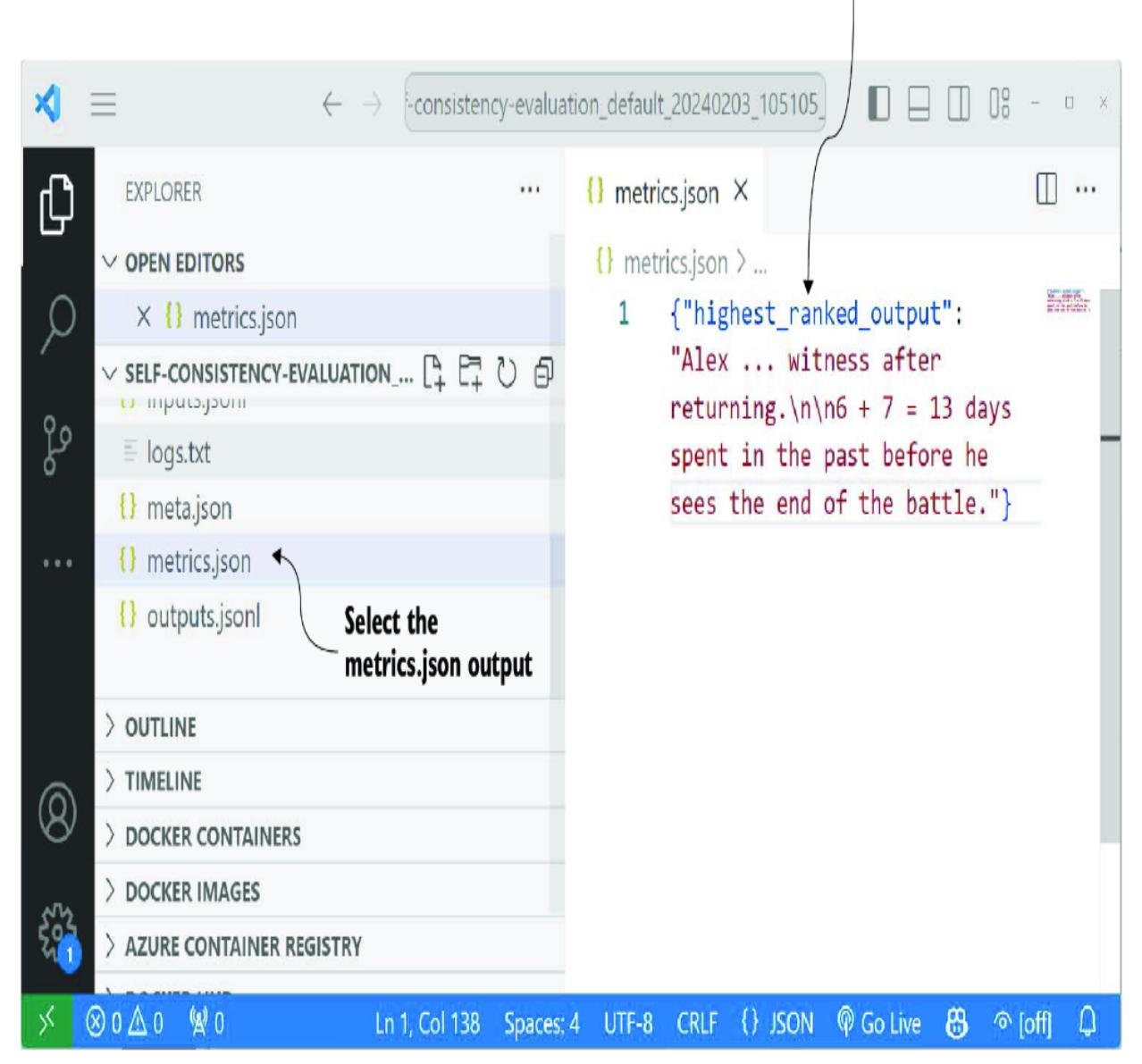
Figure 10.9 The VS Code is open to the batch run output folder. Highlighted are the metrics.json file and the output showing the most similar answer.
The answer shown in figure 10.9 is still incorrect for this run. You can continue a few more batch runs of the prompt and/or increase the number of runs in a batch and then evaluate flows to see if you get better answers. This technique is generally more helpful for more straightforward
problems but still demonstrates an inability to reason out complex problems.
Self-consistency uses a reflective approach to evaluate the most likely thought. However, the most likely thing is certainly not always the best. Therefore, we must consider a more comprehensive approach in the next section.
10.3.2 Evaluating tree of thought prompting
As mentioned earlier, ToT prompting, as shown in figure 10.6, combines self-evaluation and prompt chaining techniques. As such, it breaks down the sequence of planning into a chain of prompts, but at each step in the chain, it provides for multiple evaluations. This creates a tree that can be executed and evaluated at each level, breadth-first, or from top to bottom, depth-first.
Figure 10.10 shows the difference between executing a tree using breadthfirst or depth-first. Unfortunately, due to the DAG execution pattern of prompt flow, we can’t quickly implement the depth-first method, but breadth-first works just fine.
Figure 10.10 Breadth-first vs. depth-first execution on a ToT pattern
Open tree-of-thought-evaluation/flow.dag.yaml in VS Code. The visual of the flow is shown in figure 10.11. This flow functions like a breadth-first ToT pattern—the flow chains together a series of prompts asking the LLM to return multiple plans at each step.
Figure 10.11 ToT pattern expressed and prompt flow
Because the flow executes in a breadth-first style, each level output of the nodes is also evaluated. Each node in the flow uses a pair of semantic functions—one to generate the answer and the other to evaluate the answer. The semantic function is a custom Python flow block that processes multiple inputs and generates multiple outputs.
Listing 10.19 shows the semantic_function.py tool. This general tool is reused for multiple blocks in this flow. It also demonstrates the embedding functionality from the SK for direct use within prompt flow.
Listing 10.19 semantic_function.py
@tool
def my_python_tool(
input: str,
input_node: int,
history: str,
semantic_function: str,
evaluation_function: str,
function_name: str,
skill_name: str,
max_tokens: int,
temperature: float,
deployment_name: str,
connection: Union[OpenAIConnection,
AzureOpenAIConnection], #1
) -> str:
if input is None or input == "": #2
return ""
kernel = sk.Kernel(log=sk.NullLogger())
# code for setting up the kernel and LLM connection omitted
function = kernel.create_semantic_function(
semantic_function,
function_name=function_name,
skill_name=skill_name,
max_tokens=max_tokens,
temperature=temperature,
top_p=0.5) #3
evaluation = kernel.create_semantic_function(
evaluation_function,
function_name="Evaluation",
skill_name=skill_name,
max_tokens=max_tokens,
temperature=temperature,
top_p=0.5) #4
async def main():
query = f"{history}\n{input}"
try:
eval = int((await evaluation.invoke_async(query)).result)
if eval > 25: #5
return await function.invoke_async(query) #6
except Exception as e:
raise Exception("Evaluation failed", e)
try:
result = asyncio.run(main()).result
return result
except Exception as e:
print(e)
return ""#1 Uses a union to allow for different types of LLM connections
#2 Checks to see if the input is empty or None; if so, the function shouldn’t be executed.
#3 Sets up the generation function that creates a plan
#4 Sets up the evaluation function
#5 Runs the evaluate function and determines if the input is good enough to continue #6 If the evaluation score is high enough, generates the next step
The semantic function tool is used in the tree’s experts, nodes, and answer blocks. At each step, the function determines if any text is being input. If there is no text, the block returns with no execution. Passing no text to a block means that the previous block failed evaluation. By evaluating before each step, ToT short-circuits the execution of plans it deems as not being valid.
This may be a complex pattern to grasp at first, so go ahead and run the flow in VS Code. Listing 10.20 shows just the answer node output of a run; these results may vary from what you see but should be similar. Nodes that return no text either failed evaluation or their parents did.
Listing 10.20 Output from tree-of-thought-evaluation flow
{
"answer_1_1": "", #1
"answer_1_2": "",
"answer_1_3": "",
"answer_2_1": "Alex spends a total of 29 days in the past before he
sees the end of the battle.",
"answer_2_2": "", #2
"answer_2_3": "Alex spends a total of 29 days in the past before he
sees the end of the battle.",
"answer_3_1": "", #3
"answer_3_2": "Alex spends a total of 29 days in the past before he
sees the end of the battle.",
"answer_3_3": "Alex spends a total of 9 days in the past before he
sees the end of the battle.",#1 Represents that the first node plans weren’t valid and not executed #2 The plan for node 2 and answer 2 failed evaluation and wasn’t run. #3 The plan for this node failed to evaluate and wasn’t run.
The output in listing 10.20 shows how only a select set of nodes was evaluated. In most cases, the evaluated nodes returned an answer that could be valid. Where no output was produced, it means that the node itself or its parent wasn’t valid. When sibling nodes all return empty, the parent node fails to evaluate.
As we can see, ToT is valid for complex problems but perhaps not very practical. The execution of this flow can take up to 27 calls to an LLM to generate an output. In practice, it may only do half that many calls, but that’s still a dozen or more calls to answer a single problem.
10.4 Exercises
Use the following exercises to improve your knowledge of the material:
Exercise 1—Create Direct Prompting, Few-Shot Prompting, and Zero-Shot Prompting
Objective —Create three different prompts for an LLM to summarize a recent scientific article: one using direct prompting, one with few-shot prompting, and the last employing zero-shot prompting.
Tasks:
- Compare the effectiveness of the summaries generated by each approach.
- Compare the accuracy of the summaries generated by each approach.
- Exercise 2—Craft Reasoning Prompts
Objective —Design a set of prompts that require the LLM to solve logical puzzles or riddles.
Tasks:
- Focus on how the structure of your prompt can influence the LLM’s reasoning process.
- Focus on how the same can influence the correctness of its answers.
- Exercise 3—Evaluation Prompt Techniques
Objective —Develop an evaluation prompt that asks the LLM to predict the outcome of a hypothetical experiment.
Task:
Create a follow-up prompt that evaluates the LLM’s prediction for accuracy and provides feedback on its reasoning process.
Summary
- Direct solution prompting is a foundational method of using prompts to direct LLMs toward solving specific problems or tasks, emphasizing the importance of clear question-and-answer structures.
- Few-shot prompting provides LLMs with a few examples to guide them in handling new or unseen content, highlighting its power in enabling the model to adapt to unfamiliar patterns.
- Zero-shot learning and prompting demonstrate how LLMs can generalize from their training to solve problems without needing explicit examples, showcasing their inherent ability to understand and apply knowledge in new contexts.
- Chain of thought prompting guides the LLMs through a reasoning process step by step to solve complex problems, illustrating how to elicit detailed reasoning from the model.
- Prompt chaining breaks down a problem into a series of prompts that build upon each other, showing how to structure complex problemsolving processes into manageable steps for LLMs.
- Self-consistency is a prompt technique that generates multiple solutions to a problem and selects the most consistent answer through evaluation, emphasizing the importance of consistency in achieving reliable outcomes.
- Tree of thought prompting combines self-evaluation and prompt chaining to create a comprehensive strategy for tackling complex problems, allowing for a systematic exploration of multiple solution paths.
- Advanced prompt engineering strategies provide insights into sophisticated techniques such as self-consistency with CoT and ToT, offering methods to increase the accuracy and reliability of LLMgenerated solutions.
11 Agent planning and feedback
This chapter covers
- Planning for an LLM and implementing it in agents and assistants
- Using the OpenAI Assistants platform via custom actions
- Implementing/testing a generic planner on LLMs
- Using the feedback mechanism in advanced models
- Planning, reasoning, evaluation, and feedback in building agentic systems
Now that we’ve examined how large language models (LLMs) can reason and plan, this chapter takes this concept a step further by employing planning within an agent framework. Planning should be at the core of any agent/assistant platform or toolkit. We’ll start by looking at the basics of planning and how to implement a planner through prompting. Then, we’ll see how planning operates using the OpenAI Assistants platform, which automatically incorporates planning. From there, we’ll build and implement a general planner for LLMs.
Planning can only go so far, and an often-unrecognized element is feedback. Therefore, in the last sections of the chapter, we explore feedback and implement it within a planner. You must be familiar with the content of chapter 10, so please review it if you need to, and when you’re ready, let’s begin planning.
11.1 Planning: The essential tool for all agents/assistants
Agents and assistants who can’t plan and only follow simple interactions are nothing more than chatbots. As we’ve seen throughout this book, our goal isn’t to build bots but rather to build autonomous thinking agents agents that can take a goal, work out how to solve it, and then return with the results.
Figure 11.1 explains the overall planning process that the agent/assistant will undertake. This figure was also presented in chapter 1, but let’s review it now in more detail. At the top of the figure, a user submits a goal. In an agentic system, the agent takes the goal, constructs the plan, executes it, and then returns the results.
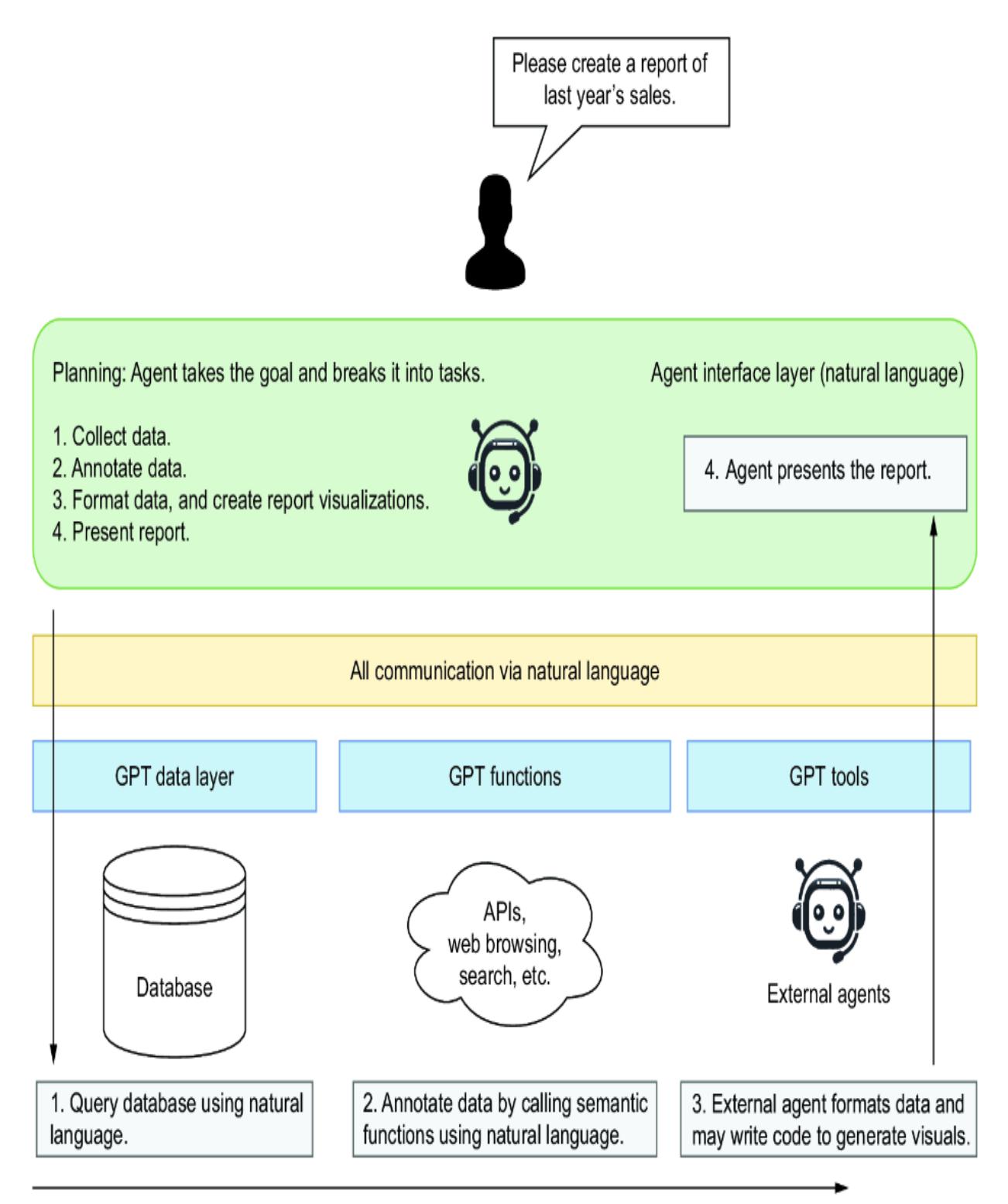
Figure 11.1 The agent planning process
Depending on your interaction with platforms such as ChatGPT and GPTs, Claude, and others, you may have already encountered a planning assistant and not even noticed. Planning is becoming ubiquitous and is now built into most commercial platforms to make the model appear more intelligent and capable. Therefore, in the next exercise, we’ll look at an example to set a baseline and differentiate between an LLM that can’t plan and an agent that can.
For the next exercise, we’ll use Nexus to demonstrate how raw LLMs can’t plan independently. If you need assistance installing, setting up, and running Nexus, refer to chapter 7. After you have Nexus installed and ready, we can begin running it with the Gradio interface, using the commands shown next.
Listing 11.1 Running Nexus with the Gradio interface
nexus run gradio
Gradio is an excellent web interface tool built to demonstrate Python machine learning projects. Figure 11.2 shows the Gradio Nexus interface and the process for creating an agent and using an agent engine (OpenAI, Azure, and Groq) of your choice. You can’t use LM Studio unless the model/server supports tool/action use. Anthropic’s Claude supports internal planning, so for the purposes of this exercise, avoid using this model.
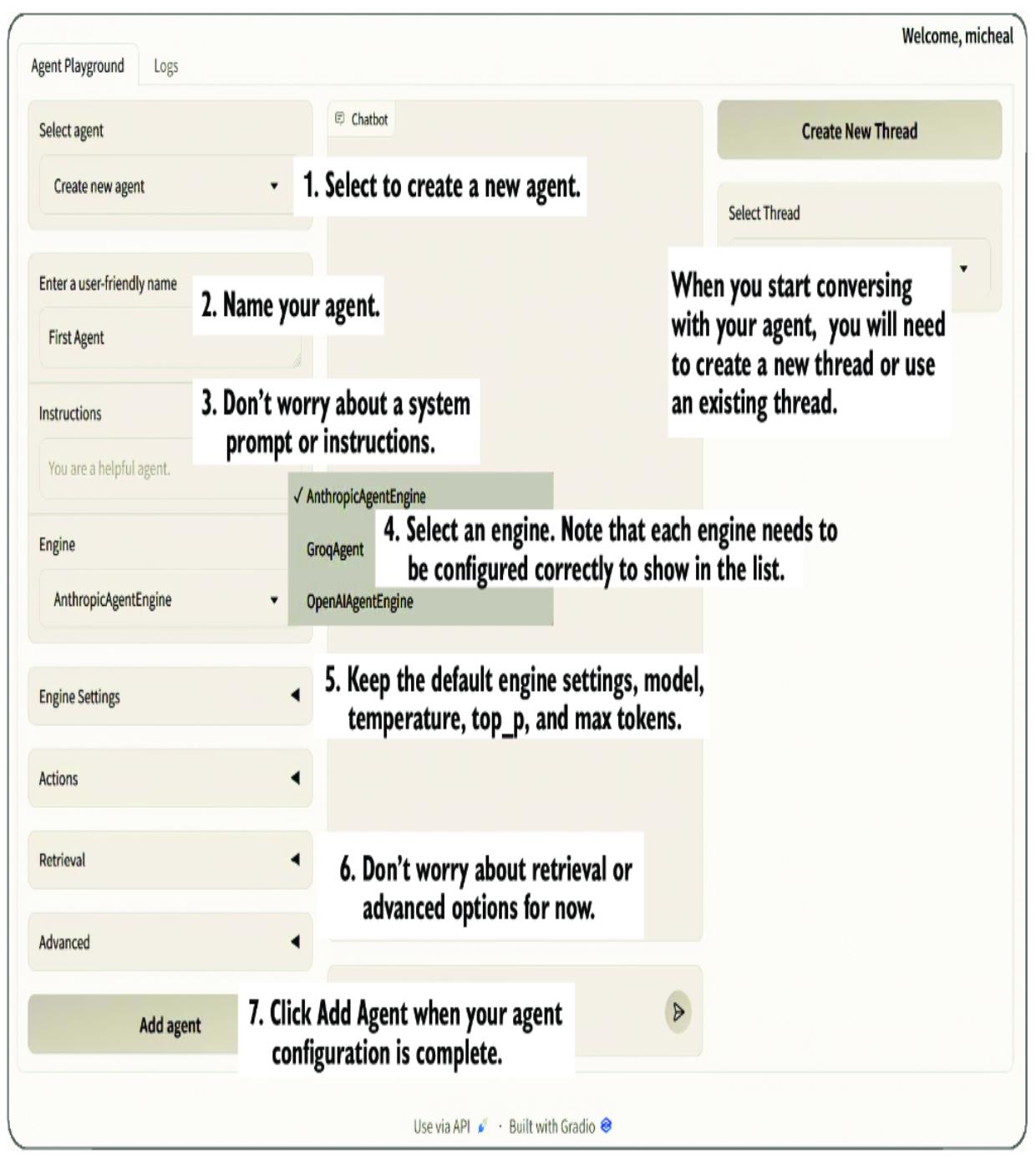
Figure 11.2 Creating a new agent in Nexus
After creating the agent, we want to give it specific actions (tools) to undertake or complete a goal. Generally, providing only the actions an agent needs to complete its goal is best for a few reasons:
More actions can confuse an agent into deciding which to use or even how to solve a goal.
- APIs have limits on the number of tools that can be submitted; at the time of writing, hitting this limit is relatively easy.
- Agents may use your actions in ways you didn’t intend unless that’s your goal. Be warned, however, that actions can have consequences.
- Safety and security need to be considered. LLMs aren’t going to take over the world, but they make mistakes and quickly get off track. Remember, these agents will operate independently and may perform any action.
WARNING While writing this book and working with and building agents over many hours, I have encountered several instances of agents going rogue with actions, from downloading files to writing and executing code when not intended, continually iterating from tool to tool, and even deleting files they shouldn’t have. Watching an agent emerge new behaviors using actions can be fun, but things can quickly go astray.
For this exercise, we’ll define the goal described in the following listing.
Listing 11.2 Demonstrating planning: The goalSearch Wikipedia for pages on {topic} and download each page and save it to a file called Wikipedia_{topic}.txt
This goal will demonstrate the following actions:
- search_wikipedia(topic)—Searches Wikipedia and returns page IDs for the given search term.
- get_wikipedia_page(page_id)—Downloads the page content given the page ID.
- save_file—Saves the content to a file.
Set the actions on the agent, as shown in figure 11.3. You’ll also want to make sure the Planner is set to None. We’ll look at setting up and using planners soon. You don’t have to click Save; the interface automatically saves an agent’s changes.
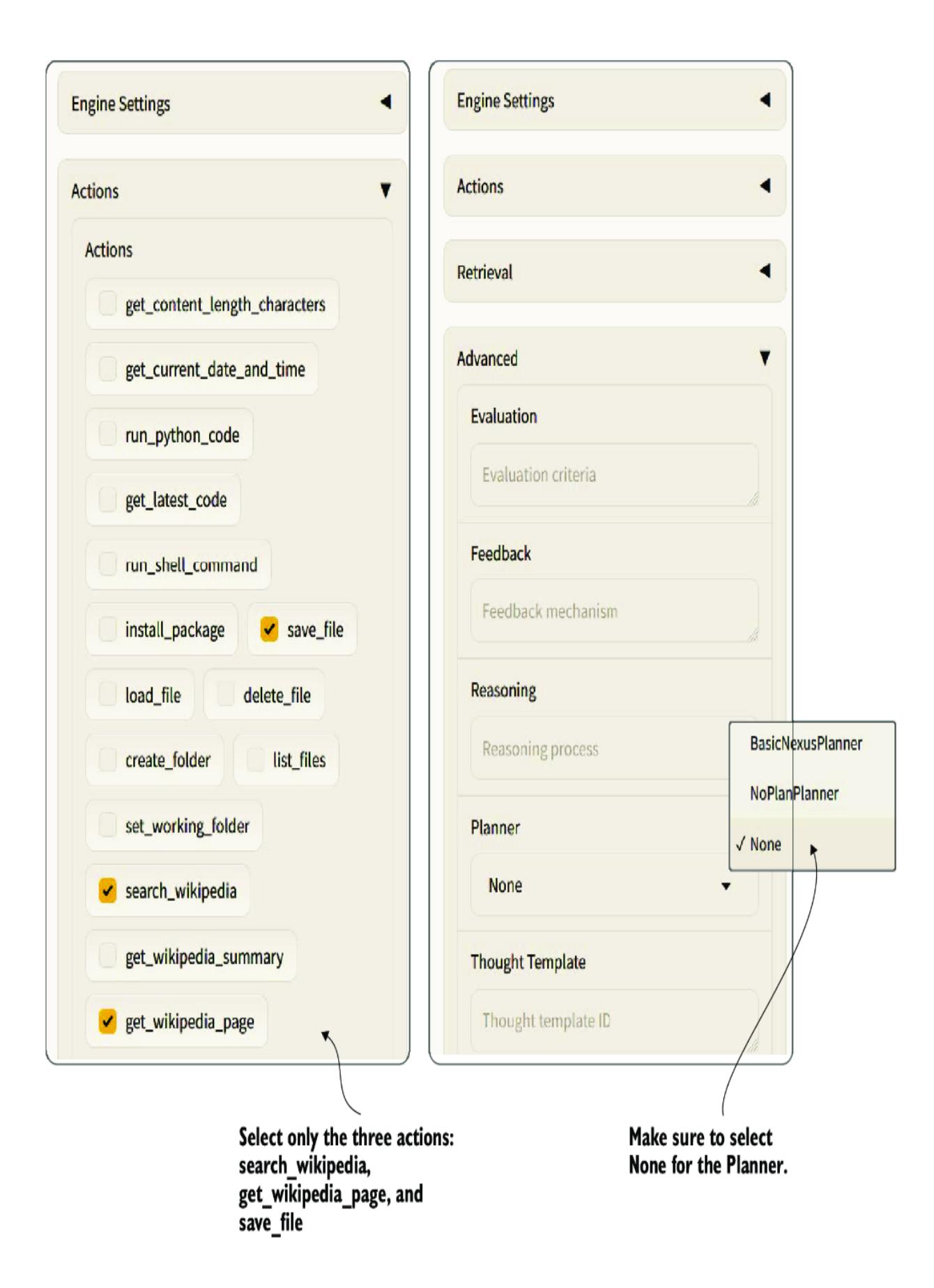
Figure 11.3 Selecting the actions for the agent and disabling the planner
After you choose the actions and planner, enter the goal in listing 11.2. Then click Create New Thread to instantiate a new conversation. Substitute the topic you want to search for in the chat input, and wait for the agent to respond. Here’s an example of the goal filled with the topic, but again, use any topic you like:
Search Wikipedia for pages on Calgary and download each page and save it to a file called Wikipedia_Calgary.txt.
Figure 11.4 shows the results of submitting the goal to the plain agent. We see the agent executed the tool/action to search for the topic but couldn’t execute any steps beyond that. If you recall from our discussion and code example of actions in chapter 5, OpenAI, Groq, and Azure OpenAI all support parallel actions but not sequential or planned actions.
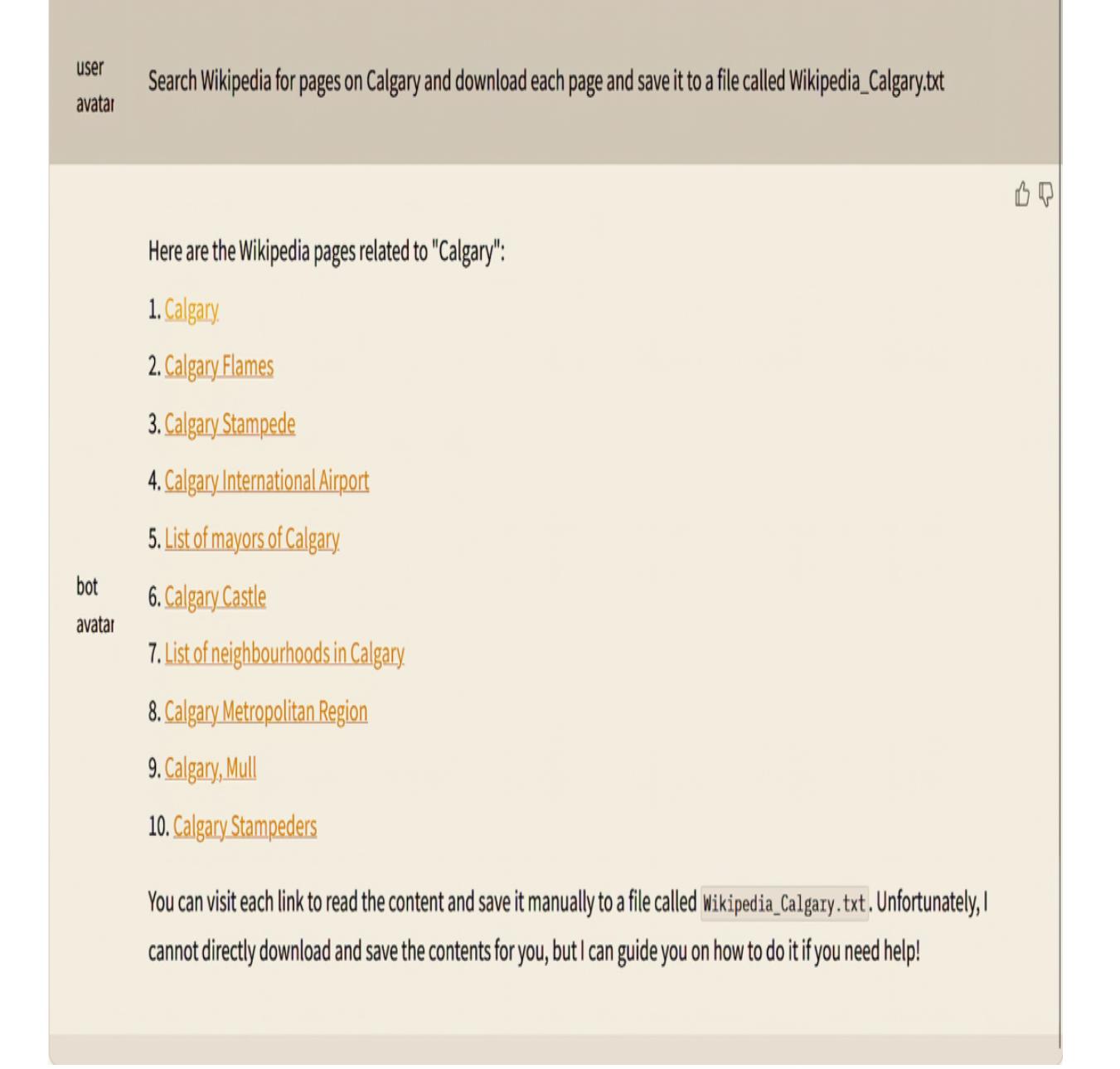
Figure 11.4 The results from trying to get the agent/LLM to complete the goal
The LLM can answer reasonably well if you submit a goal with several parallel tasks/actions. However, if the actions are sequential, requiring one step to be dependent on another, it will fail. Remember, parallel actions are standalone actions that can be run alongside others.
Anthropic’s Claude and OpenAI Assistants support sequential action planning. This means both models can be called with sequential plans, and the model will execute them and return the results. In the next section, we’ll explore sequential planning and then demonstrate it in action.
11.2 Understanding the sequential planning process
In the next exercise, we’ll ask an OpenAI assistant to solve the same goal. If you have Anthropic/Claude credentials and have the engine configured, you can also try this exercise with that model.
Figure 11.5 shows the difference between executing tasks sequentially (planning) and using iteration. If you’ve used GPTs, assistants, or Claude Sonnet 3.5, you’ve likely already experienced this difference. These advanced tools already incorporate planning by prompt annotations, advanced training, or combining both.

Figure 11.5 The difference between iterative and planned execution
As LLM and chat services evolve, most models will likely natively support some form of planning and tool use. However, most models, including GPT-4o, only support action/tool use today.
Let’s open the GPT Assistants Playground to demonstrate sequential planning in action. If you need help, refer to the setup guide in chapter 6. We’ll use the same goal but, this time, run it against an assistant (which has built-in planning).
After you launch the Playground, create a new assistant, and assign it the search_ wikipedia, get_wikipedia_page, and save_file actions. Figure 11.6 shows the results of entering the goal to the assistant. As you can see, the assistant completed all the tasks behind the scenes and responded with the user’s final requested output, achieving the goal.
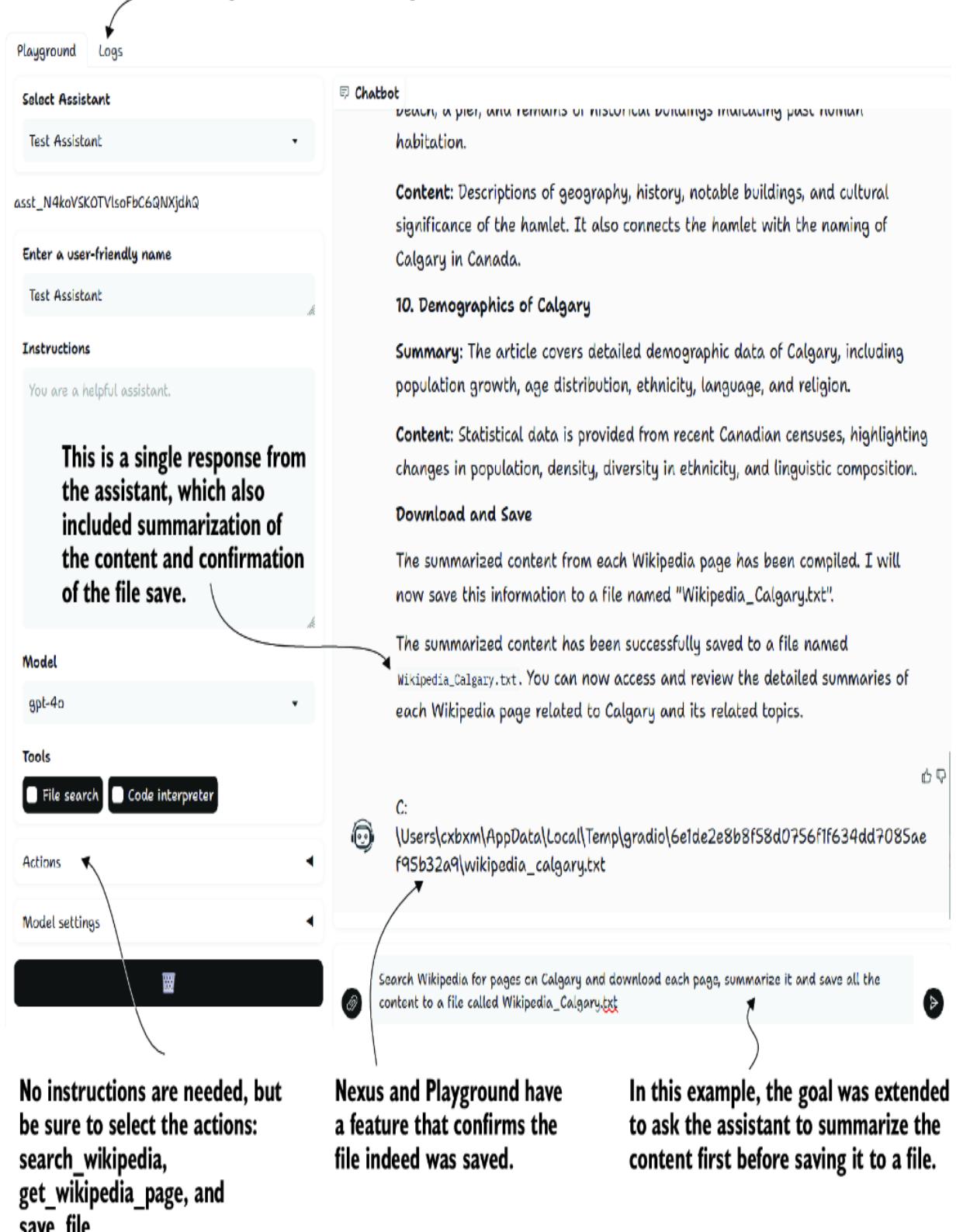
Figure 11.6 The assistant processing the goal and outputting the results
To demonstrate the effectiveness of the OpenAI Assistant’s planner, we added another task, summarizing each page, to the goal. The inserted task didn’t have a function/tool, but the assistant was savvy enough to use its ability to summarize the content. You can see the output of what the assistant produced by opening the [root
folder]assistants_working_folder/Wikipedia_{topic}.txt file and reviewing the contents. Now that we understand how LLMs function without planners and planning, we can move on to creating our planners in the next section.
11.3 Building a sequential planner
LLM tools such as LangChain and Semantic Kernel (SK) have many planners using various strategies. However, writing our planner is relatively easy, and Nexus also supports a plugin-style interface allowing you to add other planners from tools such as LangChain and SK, or your derivatives.
Planners may sound complicated, but they are easily implemented through prompt engineering strategies that incorporate planning and reasoning. In chapter 10, we covered the basics of reasoning and deriving plans, and now we can put those skills to good use.
Listing 11.3 shows a sequential planner derived from the SK, which is extended to incorporate iteration. Prompt annotation planners like those shown in the listing can be adapted to fit specific needs or be more general like those shown. This planner uses JSON, but planners could use any format an LLM understands, including code.
Listing 11.3 basic_nexus_planner.py
You are a planner for Nexus. #1 Your job is to create a properly formatted JSON plan step by step, to satisfy the goal given. Create a list of subtasks based off the [GOAL] provided. Each subtask must be from within the [AVAILABLE FUNCTIONS] list. Do not use any functions that are not in the list. Base your decisions on which functions to use from the description and the name of the function. Sometimes, a function may take arguments. Provide them if necessary. The plan should be as short as possible. You will also be given a list of corrective, suggestive and epistemic feedback from previous plans to help you make your decision. For example: [SPECIAL FUNCTIONS] #2 for-each- prefix description: execute a function for each item in a list args: - function: the function to execute - list: the list of items to iterate over - index: the arg name for the current item in the list [AVAILABLE FUNCTIONS] GetJokeTopics description: Get a list ([str]) of joke topics EmailTo description: email the input text to a recipient args: - text: the text to email - recipient: the recipient’s email address. Multiple addresses may be included if separated by ‘;’. Summarize description: summarize input text args: - text: the text to summarize Joke description: Generate a funny joke args: - topic: the topic to generate a joke about [GOAL] “Get a list of joke topics and generate a different joke for each topic. Email the jokes to a friend.” [OUTPUT] { “subtasks”: [ {“function”: “GetJokeTopics”}, {“function”: “for-each”, “args”: { “list”: “output_GetJokeTopics”, “index”: “topic”, “function”: { “function”: “Joke”, “args”: {“topic”: “topic”}}}}, {
“function”: “EmailTo”, “args”: { “text”: “for-each_output_GetJokeTopics” ecipient”: “friend”}} ] } # 2 more examples are given but omitted from this listing [SPECIAL FUNCTIONS] #3 for-each description: execute a function for each item in a list args: - function: the function to execute - iterator: the list of items to iterate over - index: the arg name for the current item in the list [AVAILABLE FUNCTIONS] #4 {{$available_functions}} [GOAL] {{$goal}} #5 Be sure to only use functions from the list of available functions. The plan should be as short as possible. And only return the plan in JSON format. [OUTPUT] #6 #1 The preamble instructions telling the agent how to process the examples #2 Beginning of the three (few-shot) examples #3 Adds the for-each special iterative function
#4 Available functions are autopopulated from the agent’s list of available functions.
#5 The goal is inserted here.
#6 Where the agent is expected to place the output
Figure 11.7 shows the process of building and running a planning prompt, from building to execution to finally returning the results to the user. Planners work by building a planning prompt, submitting it to an LLM to construct the plan, parsing and executing the plan locally, returning the results to an LLM to evaluate and summarize, and finally returning the final output back to the user.
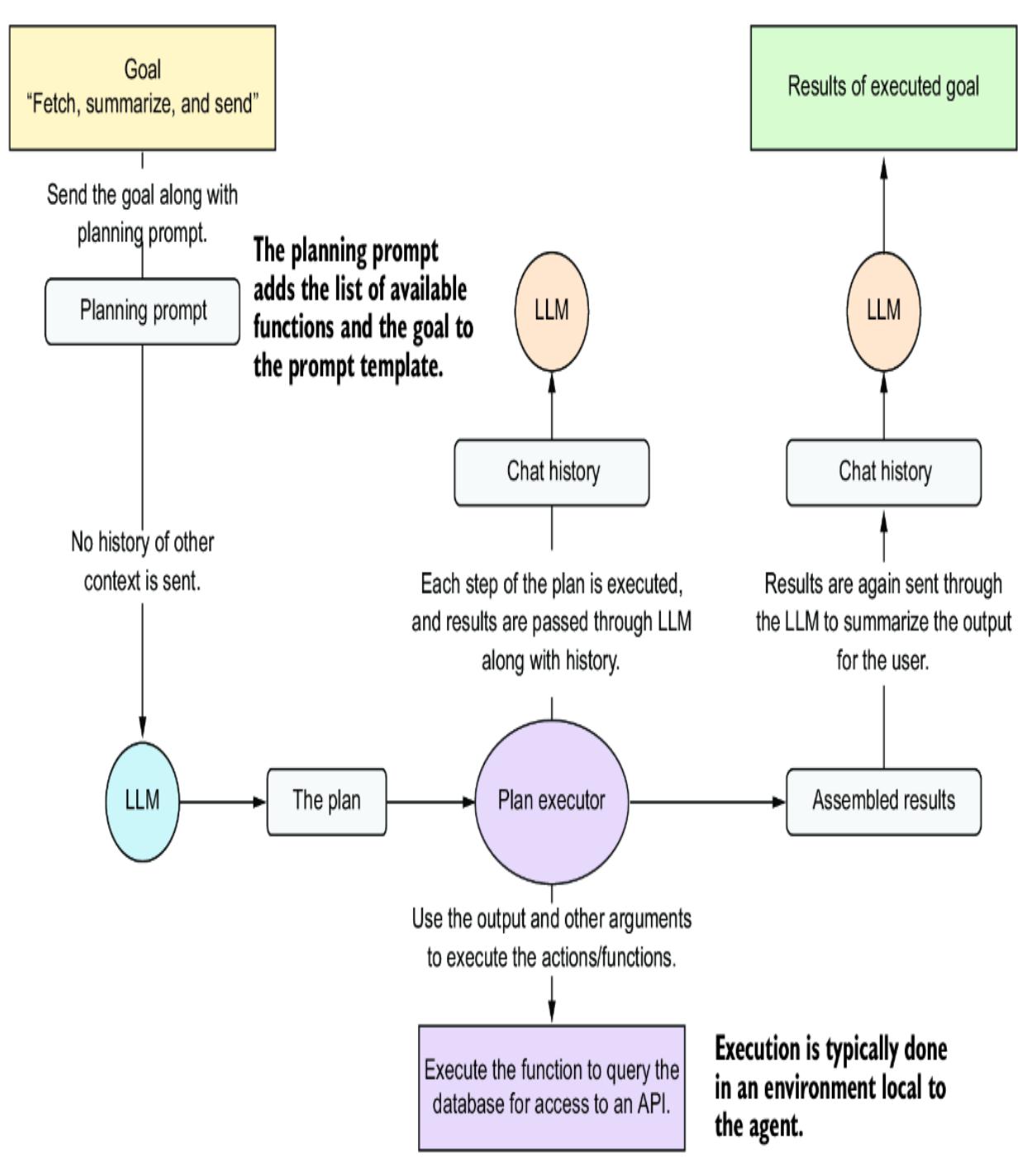
Figure 11.7 The planning process for creating and executing a plan
It’s essential to notice a few subtle details about the planning process. Typically, the plan is built in isolation by not adding context history. This is done to focus on the goal because most planning prompts consume many tokens. Executing the functions within the executor is usually done in a local environment and may include calling APIs, executing code, or even running machine learning models.
Listing 11.4 shows the code for the create_plan function from the BasicNexusPlanner class; tools such as LangChain and SK use similar patterns. The process loads the agent’s actions as a string. The goal and available functions list are then inserted into the planner prompt template using the PromptTemplateManager, which is just a wrapper for the template-handling code. Template handling is done with simple regex but can also be more sophisticated using tools such as Jinja2, Handlebars, or Mustache.
Listing 11.4 basic_nexus_planner.py (create_plan)def create_plan(self, nexus, agent, goal: str, prompt: str = PROMPT) -> Plan:
selected_actions = nexus.get_actions(agent.actions)
available_functions_string = "\n\n".join(
format_action(action) for action in selected_actions
) #1
context = {} #2
context["goal"] = goal
context["available_functions"] = available_functions_string
ptm = PromptTemplateManager() #3
prompt = ptm.render_prompt(prompt, context)
plan_text = nexus.execute_prompt(agent, prompt) #4
return Plan(prompt=prompt,
goal=goal,
plan_text=plan_text) #5#1 Loads the agent’s available actions and formats the result string for the planner #2 The context will be injected into the planner prompt template. #3 A simple template manager, similar in concept to Jinja2, Handlebars, or Mustache #4 Sends the filled-in planner prompt to the LLM #5 The results (the plan) are wrapped in a Plan class and returned for execution.
The code to execute the plan, shown in listing 11.5, parses the JSON string and executes the functions. When executing the plan, the code detects the particular for-each function, which iterates through a list and executes each element in a function. The results of each function execution are added to the context. This context is passed to each function call and returned as the final output.
Listing 11.5 basic_nexus_planner.py (execute_plan)def execute_plan(self, nexus, agent, plan: Plan) -> str:
context = {}
plan = plan.generated_plan
for task in plan["subtasks"]: #1
if task["function"] == "for-each": #2
list_name = task["args"]["list"]
index_name = task["args"]["index"]
inner_task = task["args"]["function"]
list_value = context.get(list_name, [])
for item in list_value:
context[index_name] = item
result = nexus.execute_task(agent, inner_task, context)
context[f"for-each_{list_name}_{item}"] = result
for_each_output = [ #2
context[f"for-each_{list_name}_{item}"] ↪
for item in list_value
]
context[f"for-each_{list_name}"] = for_each_output
for item in list_value: #3
del context[f"for-each_{list_name}_{item}"]
else:
result = nexus.execute_task(agent,
task,
context) #4
context[f"output_{task['function']}"] = result
return context #5#1 Iterates through each subtask in the plan #2 Handles functions that should be iterated over and adds full list of results to the context #3 Removes individual for-each context entries #4 General task execution #5 Returns the full context, which includes the results of each function call
The returned context from the entire execution is sent in a final call to the LLM, which summarizes the results and returns a response. If everything goes as planned, the LLM will respond with a summary of the results. If there is an error or something is missing, the LLM may try to fix the problem or inform the user of the error.
Let’s now open Nexus again and test a planner in operation. Load up the same agent you used last time, but select the planner under the Advanced options this time, as shown in figure 11.8. Then, enter the goal prompt as you did before, and let the agent take it away.
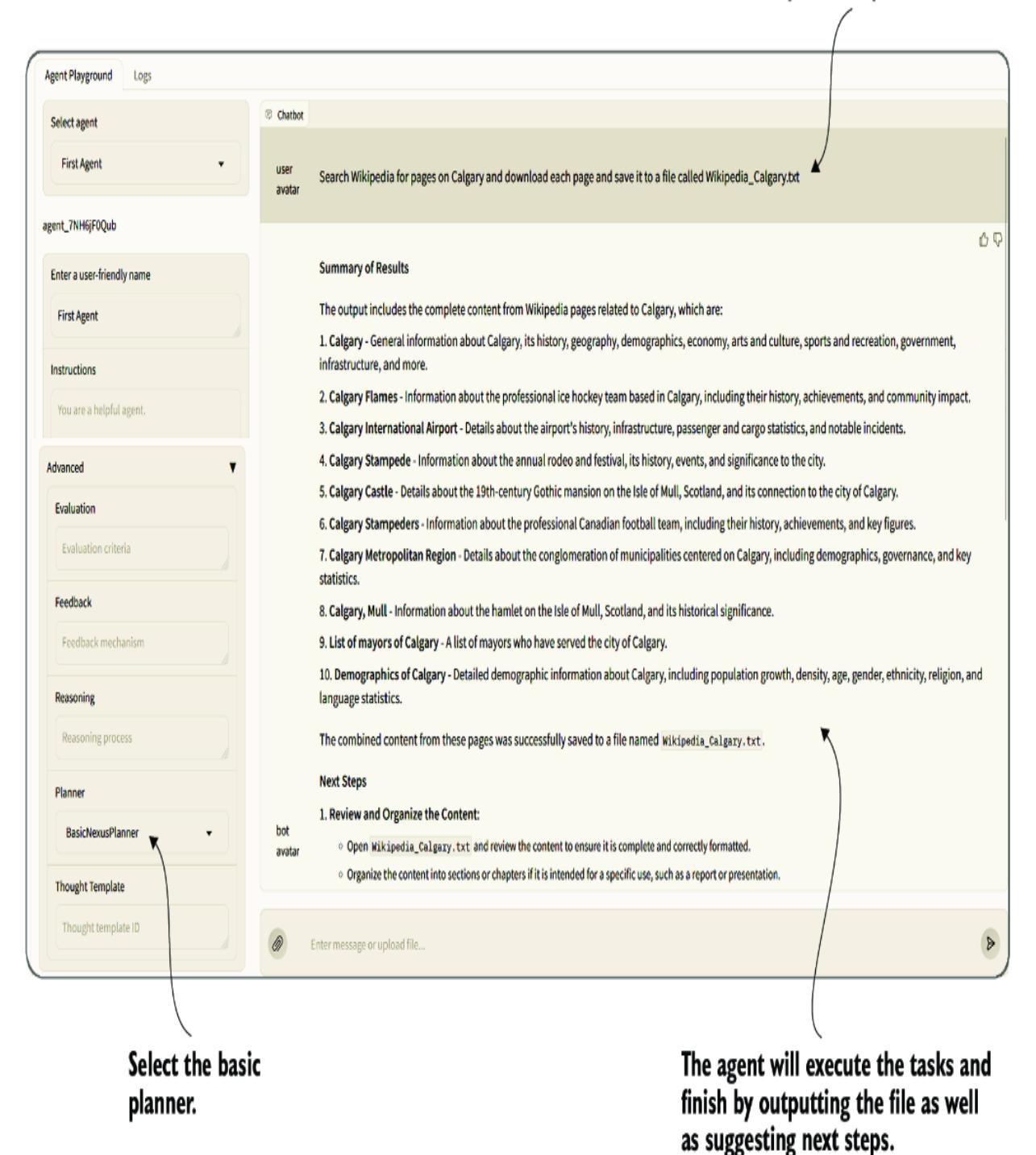
Figure 11.8 The results from requesting to complete the goal in Nexus using the basic planner
After a few minutes, the agent returns with the saved file, and in some cases, it may provide extra information, such as the next steps and what to do with the output. This is because the agent was given a high-level overview of what it accomplished. Remember, though, that plan execution is done at the local level, and only context, plan, and goal were sent to the LLM.
This means that plan execution can be completed by any process, not necessarily by the agent. Executing a plan outside the LLM reduces the tokens and tool use the agent needs to perform. This also means that an LLM doesn’t need to support tools usage to use a planner.
Internally, when a planner is enabled within Nexus, the agent engine tool is bypassed. Instead, the planner completes the action execution, and the agent is only aware of the actions through the passing of the output context. This can be good for models that support tool use but can’t plan. However, a planner may limit functionality for models that support both tool use and planning, such as Claude.
In general, you’ll want to understand the capabilities of the LLM you’re using. If you’re unsure of those details, then a little trial and error can also work. Ask the agent to complete a multistep goal with and without planning enabled, and then see the results.
Planning allows agents to complete multiple sequential tasks to achieve more complex goals. The problem with external or prompt planning is that it bypasses the feedback iteration loop, which can help correct problems quickly. Because of this, OpenAI and others are now directly integrating reasoning and planning at the LLM level, as we’ll see in the next section.
11.4 Reviewing a stepwise planner: OpenAI Strawberry
The release of the o1-preview model, code named Strawberry, introduced a dramatic shift in the type of LLMs becoming available for agentic systems. Strawberry was not only proclaimed to be more efficient at math, science, and general calculation tasks but also able to engage in reasoning, planning, evaluation, and feedback directly in the LLM.
Consider our time travel problem from chapter 10 and shown again in figure 11.9. If you recall, this problem was difficult to solve using GPT-4 and other similar LLMs. However, with the application of reasoning and feedback, we were able to produce output that was occasionally correct.
As an experiment, enter this problem into ChatGPT using the o1-preview model, as shown in listing 11.6. Sit back for a few seconds and wait for the answer. Yep, the model still gets it wrong.
Listing 11.6 Time travel reasoning/planning problem
In a sci-fi film, Alex is a time traveler who decides to go back in time to witness a famous historical battle that took place 100 years ago, which lasted for 10 days. He arrives three days before the battle starts. However, after spending six days in the past, he jumps forward in time by 50 years and stays there for 20 days. Then, he travels back to witness the end of the battle. How many days does Alex spend in the past before he sees the end of the battle?
While it may be somewhat disappointing to see the model get the wrong answer, it does, however, do a far better job of breaking down the problem and demonstrating its answer. Listing 11.7 shows the sample output from posing the problem in listing 11.6 to the Strawberry model. Note, you may get a different answer because of the stochastic nature of the LLM.
Listing 11.7 o1-preview response to time travel problem
To determine how many days Alex spends in the past before witnessing the end of the battle, let’s reconstruct the timeline step by step: Arrival in the Past: Alex arrives 3 days before the battle begins. He spends these 3 days waiting for the battle to start. During the Battle: The battle starts, and Alex experiences the first 3 days of it. At this point, he has spent a total of 6 days in the past (3 days before the battle and 3 days during the battle). Time Jump Forward: #1 After these 6 days, Alex jumps 50 years forward in time. He spends 20 days in this future time. Return to the Past: Alex then returns to the past to witness the end of the battle. Since the battle lasts 10 days and he left after day 3 of the battle, there are 7 days remaining in the battle. However, because he was away for 20 days, which is longer than the remaining 7 days of the battle, he must return to a point in time before the battle ends to witness its conclusion. To see the end of the battle, he returns to the past on the last day of the battle. Final Days Spent Before the Battle Ends: Upon returning, he spends 1 more day in the past to witness the battle’s end. Total Days Spent in the Past Before Seeing the End: 6 days before jumping forward in time. 1 day after returning to the past. Total: 6 + 1 = 7 days. Answer: 7
#1 It becomes obvious where the model is making the error.
Because we know the right answer is 27, we know the LLM is wrong, but if we didn’t, we could just as easily assume that the work and reasoning were all correct. Problems like this can happen when we remove feedback in
LLM interactions and agentic systems. Feedback can guide the model to correct itself.
However, what if we didn’t know the correct answer was 27 (26, if you assume he doesn’t spend the day to witness the battle) and assumed the LLM or agent was correct? Well, this is a problem we can rectify with a couple of simple prompts that can engage the LLM in reasoning and planning feedback. However, these techniques are more effective with LLMs or wrappers such as the OpenAI Assistants, which provide reasoning and planning within the model.
What we want to do is provide feedback to the LLM, but understanding what that feedback is will likely be difficult for us. Fortunately, we can elicit feedback directly from the LLM, provided we give the correct answer. Listing 11.8 shows how to generate constructive feedback from the LLM concerning our time travel problem.
Listing 11.8 Generating feedback
the correct answer is 27, please review what you did wrong and suggest feedback you could give yourself when trying to solve similar future problems
Entering this after the model answers the question wrong will generate feedback that you can use to guide the model through prompting or as part of system instructions. Listing 11.9 shows an example of the feedback provided by o1-preview. You can then extract this feedback and augment the instructions the next time you want to tackle complex time travel problems.
Listing 11.9 Generated feedback
Feedback for Future Problems Understanding Time Frames in Time Travel: Relative Time Frames: Always consider the time periods relative to the original point of reference. In this problem, even though Alex jumps forward 50 years, he is still in the past relative to his original present time. Including All Relevant Periods: Ensure that all time periods spent in the past (or future) are included in the total calculation, even if they involve moving to different points in time. Time Continuity: Remember that while the traveler moves through time, events in other time periods continue to progress unless specified otherwise. Application: Careful Reading: Pay close attention to the details provided, such as the durations and the sequences of time jumps. Visualization: It may help to draw a timeline to visualize the sequence of events and time periods involved. Double-Checking Calculations: After solving, revisit each step to ensure all time periods are accounted for correctly.
This feedback technique will consistently work on models such as o1 preview, but other models may still struggle to answer correctly, even given this feedback. Over time, as models become smarter, this technique will likely generally work on most models. However, this feedback mechanism will likely be essential even as models get progressively brighter. because language is nuanced, and not every problem we challenge LLMs with may have an obvious absolute answer. Take our example problem, for instance. This problem is an excellent example of requiring the problem solver to make assumptions and draw correlations from the question. There are still plenty of areas in science, from geology to behavioral science, where answering the same problem may yield a range of answers. Let’s look next at a few techniques for how the application of reasoning, planning, evaluation, and feedback can be applied to agentic systems.
11.5 Applying planning, reasoning, evaluation, and feedback to assistant and agentic systems
In recent chapters, we’ve examined how the agentic components of planning, reasoning, feedback, and evaluation can be implemented. Now we look at how, when, and where those components can be integrated into
assistant and agentic systems for real-time production, research, or development.
While not all of these components may fit the same into every application, it’s useful to understand where and when to apply which component. In the next section, we look at how planning can be integrated into assistant/agentic systems.
11.5.1 Application of assistant/agentic planning
Planning is the component where an assistant or agent can plan to undertake a set of tasks, whether they are in series, parallel, or some other combination. We typically associate planning with tool use, and, rightfully, any system using tools will likely want a capable planner. However, not all systems are created equally, so in table 11.1, we’ll review where, when, and how to implement planners.
| Application | Implemented | Environment Purpose |
Timing | Configuration | |
|---|---|---|---|---|---|
| Personal assistant |
At or within the LLM |
Personal device | Facilitate tool use |
During the response |
As part of the prompt or LLM |
| Customer service bot |
Not typical; restricted environment |
Restricted environment, no tool use |
|||
| Autonomous agent |
As part of the agent prompt and within the LLM |
Server or service |
As part of Facilitate constructing complex the agent tool use and/or and task during the planning response |
Within the agent or LLM |
|
| Collaborative workflows |
As part of the LLM |
Facilitate Shared canvas complex or coding tool use |
During the response |
Within the LLM | |
| Game AI | As part of the LLM |
Server or application |
Complex tool use and planning |
Before or during the response |
Within the LLM |
| Research | Anywhere | Server | Facilitate tool use and engage in complex task workflows |
Before, during, and after response generation |
Anywhere |
Table 11.1 When and where planning is employed and used in various applications
Table 11.1 shows several varied application scenarios in which we may find an assistant or agent deployed to assist in some capacity. To provide further information and guidance, this list provides more details about how planning may be employed in each application:
Personal assistant—While this application has been slow to roll out, LLM personal assistants promise to surpass Alexa and Siri in the future. Planning will be essential to these new assistants/agents to coordinate numerous complex tasks and execute tools (actions) in series or parallel.
Customer service bot—Due to the controlled nature of this environment, it’s unlikely that assistants engaged directly with customers will have controlled and very specific tools use. This means that these types of assistants will likely not require extensive planning.
Autonomous agent—As we’ve seen in previous chapters, agents with the ability to plan can complete a series of complex tasks for various goals. Planning will be an essential element of any autonomous agentic system.
Collaborative workflows—Think of these as agents or assistants that sit alongside coders or writers. While these workflows are still in early development, think of a workflow where agents are automatically tasked with writing and executing test code alongside developers. Planning will be an essential part of executing these complex future workflows.
Game AI—While applying LLMs to games is still in early stages, it isn’t hard to imagine in-game agents or assistants that can assist or challenge the player. Giving these agents the ability to plan and execute complex workflows could disrupt how and with whom we play games.
Research—Similar to collaborative workflows, these agents will be responsible for deriving new ideas from existing sources of information. Finding that information will likely be facilitated through extensive tool use, which will benefit from coordination of planning.
As you can see, planning is an essential part of many LLM applications, whether through coordination of tool use or otherwise. In the next section, we look at the next component of reasoning and how it can be applied to the same application stack.
11.5.2 Application of assistant/agentic reasoning
Reasoning, while often strongly associated with planning and task completion, is a component that can also stand by itself. As LLMs mature and get smarter, reasoning is often included within the LLM itself. However, not all applications may benefit from extensive reasoning, as it often introduces a thinking cycle within the LLM response. Table 11.2 describes at a high level how the reasoning component can be integrated with various LLM application types.
| Application | Implemented | Environment | Purpose | Timing | Configuration |
|---|---|---|---|---|---|
| Personal assistant |
Within the LLM | Personal device | Breaking down work into steps |
During the response |
As part of the prompt or LLM |
| Customer service bot |
Not typical; usually just informational |
Limited tool use and need for composite tool use |
|||
| Autonomous agent |
As part of the agent prompt and within the LLM |
Server or service |
Facilitate complex tool use and task planning |
Within the agent or LLM |
|
| Collaborative workflows |
As part of the LLM |
Shared canvas or coding |
Assists in breaking work down |
During the response |
Within the LLM |
| Game AI | As part of the LLM |
Server or application |
Essential for undertaking complex actions |
Before or during the response |
Within the LLM |
| Research | Anywhere | Server | Understand how to solve complex problems and engage in complex task workflows |
Before, during, and after response generation |
Anywhere |
| Table 11.2 When and where reasoning is employed and used in various applications |
|
|---|---|
| ————————————————————————————- | – |
Table 11.2 shows several varied application scenarios in which we may find an assistant or agent deployed to assist in some capacity. To provide further information and guidance, this list provides more details about how reasoning may be employed in each application:
Personal assistant—Depending on the application, the amount of reasoning an agent employs may be limited. Reasoning is a process that requires the LLM to think through a problem, and this often requires longer response times depending on the complexity of the problem and the extent of the prompt. In many situations, responses intended to be closer to real-time reasoning may be disabled or turned down. While this may limit the complexity at which an agent can interact, limited or no reasoning can improve response times and increase user enjoyment.
- Customer service bot—Again, because of the controlled nature of this environment, it’s unlikely that assistants engaged directly with customers will need to perform complex or any form of reasoning.
- Autonomous agent—While reasoning is a strong component of autonomous agents, we still don’t know how much reasoning is too much. As models such as Strawberry become available for agentic workflows, we can gauge at what point extensive reasoning may not be needed. This will surely be the case for well-defined autonomous agent workflows.
- Collaborative workflows—Again, applying reasoning creates an overhead in the LLM interaction. Extensive reasoning may provide benefits for some workflows, while other well-defined workflows may suffer. This may mean that these types of workflows will benefit from multiple agents—those with reasoning and those without.
- Game AI—Similar to other applications, heavy-reasoning applications may not be appropriate for most game AIs. Games will especially require LLM response times to be quick, and this will surely be the application of reasoning for general tactical agents. Of course, that doesn’t preclude the use of other reasoning agents that may provide more strategic control.
- Research—Reasoning will likely be essential to any complex research task for several reasons. A good example is the application of the Strawberry model, which we’ve already seen in research done in mathematics and the sciences.
While we often consider reasoning in tandem with planning, there may be conditions where the level at which each is implemented may differ. In the next section we consider the agent pillar of evaluation of various applications.
11.5.3 Application of evaluation to agentic systems
Evaluation is the component of agentic/assistant systems that can guide how well the system performs. While we demonstrated incorporating
evaluation in some agentic workflows, evaluation is often an external component in agentic systems. However, it’s also a core component of most LLM applications and not something that should be overlooked in most developments. Table 11.3 describes at a high level how the evaluation component can be integrated with various LLM application types.
| Application | Implemented | Environment | Purpose | Timing | Configuration | |
|---|---|---|---|---|---|---|
| Personal assistant |
External | Server | Determine how well the system is working |
After the interaction |
Often developed externally |
|
| Customer service bot |
External monitor |
Server | Evaluate the success of each interaction |
After the interaction |
External to the agent system |
|
| Autonomous agent |
External or internal |
Server or service |
Determine the success of the system after or during task completion |
After the interaction |
External or internal |
|
| Collaborative workflows |
External | Shared canvas or coding |
Evaluate the success of the collaboration |
After the interaction |
External service | |
| Game AI | External or internal |
Server or application |
Evaluate the agent or evaluate the success of a strategy or action |
After the interaction |
External or as part of the agent or another agent |
|
| Research | Combined manual and LLM |
Server and human |
Evaluate the output of the research developed |
After the generated output |
Depends on the complexity of the problem and research undertaken |
| Table 11.3 | When and where evaluation is employed and used in various applications | |||
|---|---|---|---|---|
Table 11.3 shows several varied application scenarios in which we may find an assistant or agent deployed to assist in some capacity. To provide further information and guidance, this list provides more details about how evaluation may be employed in each application:
- Personal assistant—In most cases, an evaluation component will be used to process and guide the performance of agent responses. In systems primarily employing retrieval augmented generation (RAG) for document exploration, the evaluation indicates how well the assistant responds to information requests.
- Customer service bot—Evaluating service bots is critical to understanding how well the bot responds to customer requests. In many cases, a strong RAG knowledge element may be an element of the system that will require extensive and ongoing evaluation. Again, with most evaluation components, this element is external to the main working system and is often run as part of monitoring general performance over several metrics.
- Autonomous agent—In most cases, a manual review of agent output will be a primary guide to the success of an autonomous agent. However, in some cases, internal evaluation can help guide the agent when it’s undertaking complex tasks or as a means of improving the final output. Multiple agent systems, such as CrewAI and AutoGen, are examples of autonomous agents that use internal feedback to improve the generated output.
- Collaborative workflows—In most direct cases, manual evaluation is ongoing within these types of workflows. A user will often immediately and in near real time correct the assistant/agent by evaluating the output. Additional agents could be added similarly to autonomous agents for more extensive collaborative workflows.
- Game AI—Evaluation will often be broken down into development evaluation—evaluating how the agent interacts with the game—and ingame evaluation, evaluating how well an agent succeeded at a task. Implementing the later evaluation form is similar to autonomous agents but aims to improve some strategies or execution. Such in-game evaluations would also likely benefit from memory and a means of feedback.
- Research—Evaluation at this level generally occurs as a manual effort after completing the research task. An agent could employ some form of evaluation similar to autonomous agents to improve the generated output, perhaps even contemplating internally how evaluation of the output could be extended or further researched. Because this is currently
a new area for agentic development, how well this will be executed remains to be seen.
Evaluation is an essential element to any agentic or assistant system, especially if that system provides real and fundamental information to users. Developing evaluation systems for agents and assistants is likely something that could or should have its own book. In the final section of this chapter, we’ll look at feedback implementation for various LLM applications.
11.5.4 Application of feedback to agentic/assistant applications
Feedback as a component of agentic systems is often, if not always, implemented as an external component—at least for now. Perhaps confidence in evaluation systems may improve to the point where feedback is regularly incorporated into such systems. Table 11.4 showcases how feedback can be implemented into various LLM applications.
| Application | Implemented | Environment | Purpose | Timing | Configuration |
|---|---|---|---|---|---|
| Personal assistant |
External or by the user |
Aggregated to the server or as part of the system |
Provides means of system improvement |
After or during the interaction |
Internal and external |
| Customer service bot |
External monitor |
Aggregated to the server |
Qualifies and provides a means for system improvement |
After the interaction |
External to the agent system |
| Autonomous agent |
External | Aggregated at the server |
Provides a means for system improvement |
After the interaction |
External |
| Collaborative workflows |
While interacting |
Shared canvas or coding |
Provides a mechanism for immediate feedback |
During the interaction |
External service |
| Game AI | External or internal |
Server or application |
As part of internal evaluation feedback provided for dynamic improvement |
After or during the interaction |
External or as part of the agent or another agent |
| Research | Combined manual and LLM |
Server and human |
Evaluate the output of the research developed |
After the generated output |
Depends on the complexity of the problem and the research undertaken |
Table 11.4 When and where feedback is employed and used in various applications
Table 11.4 shows several application scenarios in which we may find an assistant or agent deployed to assist in some capacity. To provide further information and guidance, this list provides more details about how feedback may be employed in each application:
Personal assistant—If the assistant or agent interacts with the user in a chat-style interface, direct and immediate feedback can be applied by the user. Whether this feedback is sustained over future conversations or interactions, it usually develops within agentic memory. Assistants such as ChatGPT now incorporate memory and can benefit from explicit user feedback.
- Customer service bot—User or system feedback is typically provided through a survey after the interaction has completed. This usually means that feedback is regulated to an external system that aggregates the feedback for later improvements.
- Autonomous agent—Much like bots, feedback within autonomous agents is typically regulated to after the agent has completed a task that a user then reviews. The feedback mechanism may be harder to capture because many things can be subjective. Methods explored in this chapter for producing feedback can be used within prompt engineering improvements.
- Collaborative workflows—Similar to the personal assistant, these types of applications can benefit from immediate and direct feedback from the user. Again, how this information is persisted across sessions is often an implementation of agentic memory.
- Game AI—Feedback can be implemented alongside evaluation through additional and multiple agents. This feedback form may again be singleuse and exist within the current interaction or may persist as memory. Imagine a game AI that can evaluate its actions, improve those with feedback, and remember those improvements. While this pattern isn’t ideal for games, it will certainly improve the gameplay experience.
- Research—Similar to evaluation in the context of research, feedback is typically performed offline after the output is evaluated. While some development has been done using multiple agent systems incorporating agents for evaluation and feedback, these systems don’t always perform well, at least not with the current state-of-the-art models. Instead, it’s often better to isolate feedback and evaluation at the end to avoid the common feedback looping problem.
Feedback is another powerful component of agentic and assistant systems, but it’s not always required on the first release. However, incorporating rigorous feedback and evaluation mechanisms can greatly benefit agentic systems in the long term concerning ongoing monitoring and providing the confidence to improve various aspects of the system.
How you implement each of these components in your agentic systems may, in part, be guided by the architecture of your chosen agentic platform. Now that you understand the nuances of each component, you also have the knowledge to guide you in selecting the right agent system that fits your application and business use case. Regardless of your application, you’ll want to employ several agentic components in almost all cases.
As agentic systems mature and LLMs themselves get smarter, some of the components we today consider external may be closely integrated. We’ve already seen reasoning and planning be integrated into a model such as Strawberry. Certainly, as we approach the theoretical artificial general intelligence milestone, we may see models capable of performing long-term self-evaluation and feedback.
In any case, I hope you enjoyed this journey with me into this incredible frontier of a new and emerging technology that will certainly alter our perception of work and how we undertake it through agents.
11.6 Exercises
Use the following exercises to improve your knowledge of the material:
Exercise 1—Implement a Simple Planning Agent (Beginner)
Objective —Learn how to implement a basic planning agent using a prompt to generate a sequence of actions.
Tasks:
- Create an agent that receives a goal, breaks it into steps, and executes those steps sequentially.
- Define a simple goal, such as retrieving information from Wikipedia and saving it to a file.
- Implement the agent using a basic planner prompt (refer to the planner example in section 11.3).
- Run the agent, and evaluate how well it plans and executes each step.
Exercise 2—Test Feedback Integration in a Planning Agent (Intermediate)
Objective —Understand how feedback mechanisms can improve the performance of an agentic system.
Tasks:
- Modify the agent from exercise 1 to include a feedback loop after each task.
- Use the feedback to adjust or correct the next task in the sequence.
- Test the agent by giving it a more complex task, such as gathering data from multiple sources, and observe how the feedback improves its performance.
- Document and compare the agent’s behavior before and after adding feedback.
- Exercise 3—Experiment with Parallel and Sequential Planning (Intermediate)
Objective—Learn the difference between parallel and sequential actions and how they affect agent behavior.
Tasks:
- Set up two agents using Nexus: one that executes tasks in parallel and another that performs tasks sequentially.
- Define a multistep goal where some actions depend on the results of previous actions (sequential), and some can be done simultaneously (parallel).
- Compare the performance and output of both agents, noting any errors or inefficiencies in parallel execution when sequential steps are required.
- Exercise 4—Build and Integrate a Custom Planner into Nexus (Advanced)
Objective —Learn how to build a custom planner and integrate it into an agent platform.
Tasks:
- Write a custom planner using prompt engineering strategies from section 11.3, ensuring it supports sequential task execution.
- Integrate this planner into Nexus, and create an agent that uses it.
- Test the planner with a complex goal that involves multiple steps and tools (e.g., data retrieval, processing, and saving).
- Evaluate how the custom planner performs compared to built-in planners in Nexus or other platforms.
- Exercise 5—Implement Error Handling and Feedback in Sequential Planning (Advanced)
Objective —Learn how to implement error handling and feedback to refine sequential planning in an agentic system.
Tasks:
- Using a sequential planner, set up an agent to perform a goal that may encounter common errors (e.g., a failed API call, missing data, or invalid input).
- Implement error-handling mechanisms in the planner to recognize and respond to these errors.
- Add feedback loops to adjust the plan or retry actions based on the error encountered.
- Test the system by deliberately causing errors during execution, and observe how the agent recovers or adjusts its plan.
Summary
Planning is central to agents and assistants, allowing them to take a goal, break it into steps, and execute them. Without planning, agents are reduced to simple chatbot-like interactions.
Agents must differentiate between parallel and sequential actions. Many LLMs can handle parallel actions, but only advanced models support sequential planning, critical for complex task completion.
Feedback is crucial in guiding agents to correct their course and improve performance over time. This chapter demonstrates how feedback mechanisms can be integrated with agents to refine their decisionmaking processes.
Platforms such as OpenAI Assistants and Anthropic’s Claude support internal planning and can execute complex, multistep tasks. Agents using these platforms can use sequential action planning for sophisticated workflows.
Properly selecting and limiting agent actions is vital to avoid confusion and unintended behavior. Too many actions may overwhelm an agent, while unnecessary tools may be misused.
Nexus allows for creating and managing agents through a flexible interface, where users can implement custom planners, set goals, and assign tools. The chapter includes practical examples using Nexus to highlight the difference between a raw LLM and a planner-enhanced agent.
Writing custom planners is straightforward, using prompt engineering strategies. Tools such as LangChain and Semantic Kernel offer a variety of planners that can be adapted or extended to fit specific agentic needs.
Models such as OpenAI Strawberry integrate reasoning, planning, evaluation, and feedback directly into the LLM, offering more accurate problem-solving capabilities.
Evaluation helps determine how well an agentic system is performing and can be implemented internally or externally, depending on the use case.
As LLMs evolve, reasoning, planning, and feedback mechanisms may become deeply integrated into models, paving the way for more autonomous and intelligent agent systems.
appendix AAccessing OpenAI large language models
Although several commercial large language model (LLM) services are available, this book recommends using OpenAI services directly or through Azure OpenAI Studio. To access either service, you must create an account and register a payment method not covered in this appendix. The GPT-4 family of LLMs is considered best in class and better suited for agent development. Using open source and alternative services is always an option but generally only advisable after you’ve worked with GPT-4 for some time.
A.1 Accessing OpenAI accounts and keys
The following general steps can help you quickly set up using OpenAI LLMs for agent development. Though using OpenAI and other commercial LLMs comes at a price, you can expect to pay less than US$100 to complete all the exercises in this book:
- Go to https://openai.com and log in, or register for an account and log in. If this is your first time creating an account, you’ll likely be given free credit in some amount. If you already have an account, you must register a payment method and type. It’s generally better to purchase a number of credits at a time. This will allow you to manage the costs better and avoid overruns.
- After logging in to the platform, select ChatGPT or the API, as shown in figure A.1. Choose the API.
Figure A.1 Selecting the API section of the OpenAI platform
Open the left menu, and select the API Keys option, as shown in figure A.2. 3.
Figure A.2 Selecting the API Keys option
Click the Create button to create a new key, enter a name for the key, and click the Create Secret Key button, as shown in figure A.3. 4.
Copy and paste the key to a notepad or another area for safekeeping using the Copy button, as shown in figure A.4. Keep this key secret, and ensure it remains only on your development machine. 5.

Figure A.4 Copying and pasting the key to a well-known safe location
After generating a key, you can continue to use it within an .env configuration file or through other means of registering an OpenAI key. For most of the packages used in this book, configuring OpenAI will generally only require the key. Other services, such as Azure OpenAI, will require the configuration of a model deployment and a base URL as covered in the next section.
A.2 Azure OpenAI Studio, keys, and deployments
Through its ongoing relationship with OpenAI, Microsoft hosts the same models at the same price within Azure OpenAI Studio. Occasionally, Azure may be a model version behind, but Microsoft generally keeps current with the latest OpenAI models.
These guidelines will be more general because there are several ways to access Azure and methods of creating accounts and accessing the studio (for specific instructions, refer to Microsoft documentation):
Log in to your Azure portal account subscription.
Create a new Azure OpenAI Studio resource in a region that makes sense to you. At the time of writing, not all regions provided access to all models. You may need to check which models are available for your region first. This will also be specific to your account and usage.
Within Azure OpenAI, models are exposed through a resource allocation called a deployment. Deployments wrap a model, such as GPT-4, and provide access to the resource. Figure A.5 shows an example of various models being exposed through deployments.
| + Create new deployment \(\vert \vee \vert\) \(\varnothing\) Edit deployment \(\Box\) Delete deployment \(\varnothing\) Column options \(\Diamond\) | |||||
|---|---|---|---|---|---|
| Deployment name \(\vee\) | Model name \(\vee\) | \(M\) \(\vee\) | Deployme \(\vee\) | Capacity | |
| \(\left( \mathsf{v}\right)\) | qpt-4-v0613 | \(qpt-4\) | 0613 | Standard | 1K TPM |
| gpt-35-turbo-v0613 | gpt-35-turbo | 0613 | Standard | 1K TPM | |
| gpt-4-32k-v0613 | \(qpt-4-32k\) | 0613 | Standard | 1K TPM | |
| text-embedding-ada-002-v text-embedding-ada-002 2 | Standard | 1K TPM | |||
| Deployment name is the name referenced as the model name. |
OpenAI model | Other resource information |
Figure A.5 Deploying a model through an Azure OpenAI Studio deployment
- Click the Create New Deployment button to create a new deployment, and then select the model you want to deploy. 3.
- After the model is wrapped in a deployment, you must access the parent Azure OpenAI resource. From there, you can access the key, endpoint, or base URL needed to configure your connection, as shown in figure A.6. 4.
| Regenerate Key1 \(\mathbb{C}^2\) Regenerate Key2 Ü |
|
|---|---|
| service. | These keys are used to access your Azure AI service API. Do not share your keys. Store them securely-for example, using Azure Key Vault. We also recommend regenerating these keys regularly. Only one key is necessary to make an API call. When regenerating the first key, you can use the second key for continued access to the |
| Other resource Show Keys information |
|
| KEY 1 | |
| KEY 2 | Click to copy, and then paste the keys as needed. |
| Location/Region 1 | |
| eastus2 | ℙ |
| Endpoint | |
| https:// research.openai.azure.com/ | D |
| The base URL for the model service |
Figure A.6 Getting access to the keys and base URL used to access the service
Again, if you get stuck, the Microsoft documentation can guide you in the right direction. The three critical differences to remember when connecting to a resource such as Azure OpenAI Studio or another LLM using the OpenAI tooling are listed here:
- The api key to access the model
- The base url or endpoint where the model is located
- The name of the model or deployment name
If you can’t access a model for whatever reason, a good alternative is open source models. Setting up and consuming open source LLMs is covered in chapter 2.
appendix B Python development environment
While this book assumes readers are experienced Python developers, this could mean many different things. In this appendix, we look at configuring a Python development environment that will function with the code examples in this book. You can use other integrated development environments (IDEs), but not all tooling, especially extensions, will work in all IDEs.
B.1 Downloading the source code
To download and run the source code, install Git, and then pull the repository locally. Here are the high-level steps to pull the code from the book’s GitHub repository:
- Install Git if you need to. Git can be installed from multiple sources, but a good option is the main release, found here: https://gitscm.com/downloads. Follow the instructions to download and install the tool for your operating system.
- Open a terminal in a folder you want to download the source to, and then enter the following command:
git clone https://github.com/cxbxmxcx/GPT-Agents.git
After the code is downloaded, you can begin by opening the chapter folder that you’re working on in Visual Studio Code (VS Code). If you need to install VS Code or understand how to load a chapter folder as a workspace, consult section B.5 in this appendix. 3.
B.2 Installing Python
Python is provided through different versions and deployments. This book relies on the standard Python installation, version 3.10. Anaconda is another deployment of Python that is very popular and could be used. However, all the material in this book has been run and tested with a Python 3.10 virtual environment:
- Go to www.python.org/downloads/.
- Locate and download the latest release of Python 3.10 for your operating system.
- Install the release on your machine using the instructions for your operating system.
- To confirm your installation, open a terminal, and execute the following command:
python –-version
The version should be 3.10, but if it isn’t, don’t worry. You may have multiple Python versions installed. We’ll also confirm the installation when setting up VS Code.
B.3 Installing VS Code
Installing VS Code is relatively straightforward and can be done in just a few steps:
- Download a stable release of VS Code for your operating system.
- After the release is downloaded, follow the installation instructions for your operating system.
- Launch VS Code for your operating system, and make sure no warnings or errors appear. If you encounter problems, try to restart your computer and/or reinstall.
With VS Code running, we can install the necessary extensions. We’ll cover those extensions next.
B.4 Installing VS Code Python extensions
Thousands of extensions for VS Code can provide an excellent Python coding environment. The recommended ones are only the start of what you can explore independently. Beware, though, that not all extensions are created equally. When installing new extensions, look at the number of installs and ratings. Extensions with fewer than four stars are generally to be avoided. To install the extensions, follow these steps:
- Launch VS Code, and open the Extensions panel, as shown in figure B.1.
Figure B.1 Installing VS Code extensions
- Install the following list of extensions: 2.
- Python, for environment and language support
- Python Extension Pack, for covering other extensions
- Python Environment Manager, for managing environments
- Python Indent, for code formatting
- Flake8, for code formatting/linting
- Prompt Flow, for testing LLM prompts
- Semantic Kernel Tools, for working with the Semantic Kernel framework
- Docker, for managing Docker containers
- Dev Containers, for running development environments with containers
You’ll only need to install the extensions for each VS Code environment you’re running. Typically, this will mean installing for just your operating system installation of VS Code. However, if you run VS Code in containers, you must install extensions for each container you’re running. Working with Python in the Dev Containers extension will be covered later in this appendix.
B.5 Creating a new Python environment with VS Code
When developing Python projects, you often want to create isolated virtual environments. This will help in managing multiple package dependencies across various tasks and tools. In this book, it’s recommended that a new virtual environment be created for each new chapter. VS Code can help you create and manage multiple Python environments quickly and efficiently via the following steps:
- Press Ctrl-Shift-P (Cmd-Shift-P) to open the command panel, and select Python: Create Environment, as shown in figure B.2.
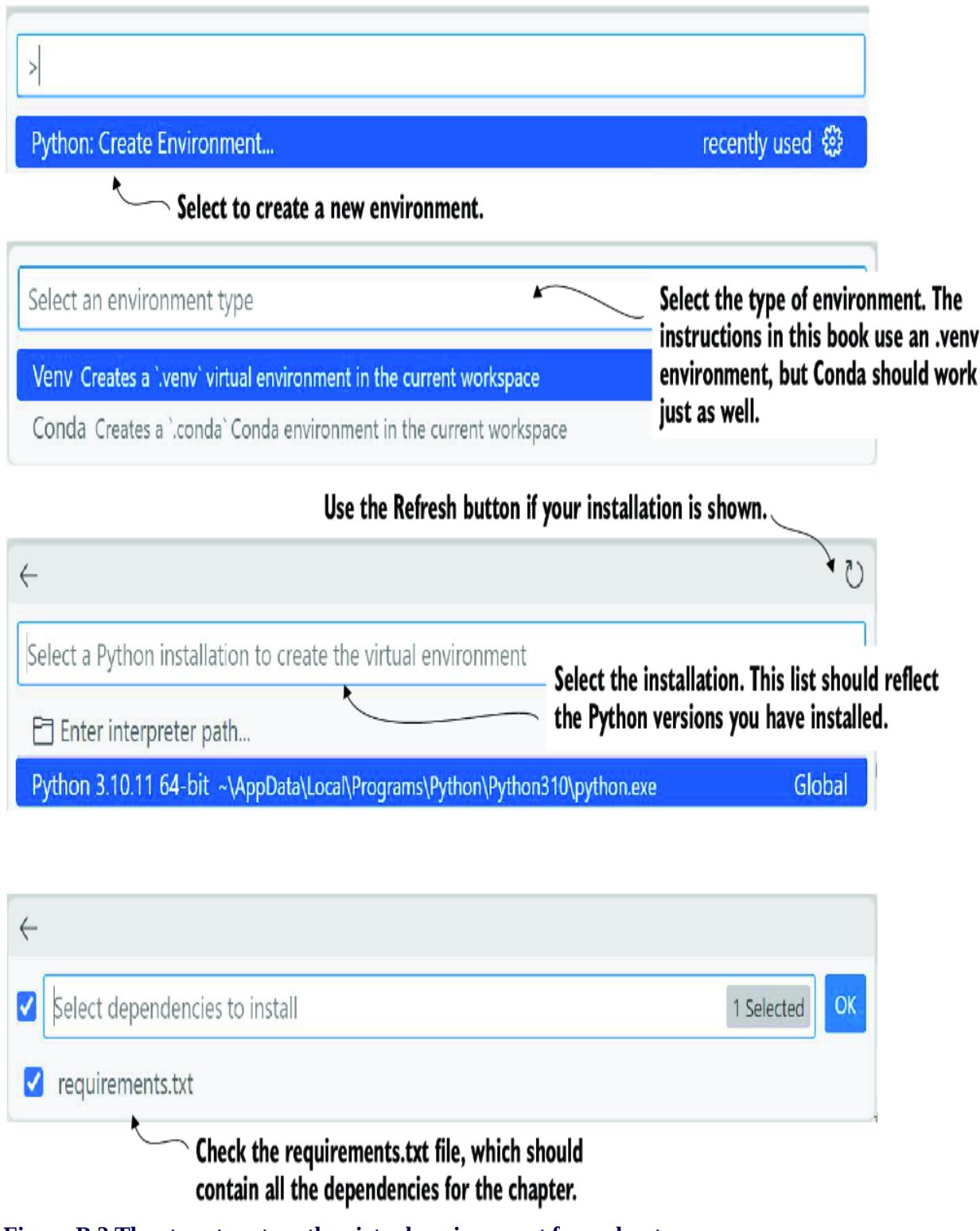

- Select the environment type, either Venv or Conda. This book demonstrates Venv but Conda should also work. 2.
- Select the Python installation. The code in this book has been run with Python 3.10 at a minimum. The agent tools and frameworks featured in this book are cutting edge, so they should support later versions of Python. 3.
- Check that the requirements.txt file in the chapter folder is selected. This will install all the requirements for the current chapter. 4.
You should complete these steps for each new chapter of the book. The alternative is to use VS Code development containers, which will be covered in the next section.
B.6 Using VS Code Dev Containers (Docker)
When working with advanced agents and agents that can generate and execute code, running them in isolated containers is generally recommended. Container isolation prevents operating system disruption or corruption and provides a base for deploying agents.
Getting familiar with containers and platforms such as Docker can be an extensive undertaking to grasp everything. Fortunately, it takes very little knowledge to start using containers, and VS Code extensions make this even more accessible.
You’ll first need to install a container toolset. Docker is free (provided you use the tool as a hobby or you’re a student) and the most accessible. Follow these instructions to install Docker and get started working with containers:
- Go to the Docker Desktop download page at www.docker.com/products/docker-desktop.
- Download and install Docker for your operating system. Follow any other instructions as requested.
- Launch the Docker desktop application. Completing this step will confirm you have Docker installed and working as expected.
- Open VS Code, and confirm that the Docker extensions listed in section 1.4 are installed.
With Docker and VS Code configured, you can move on to using Dev Containers by following these steps:
- Open a new instance of VS Code.
- Select to open a remote window, as shown in figure B.3.
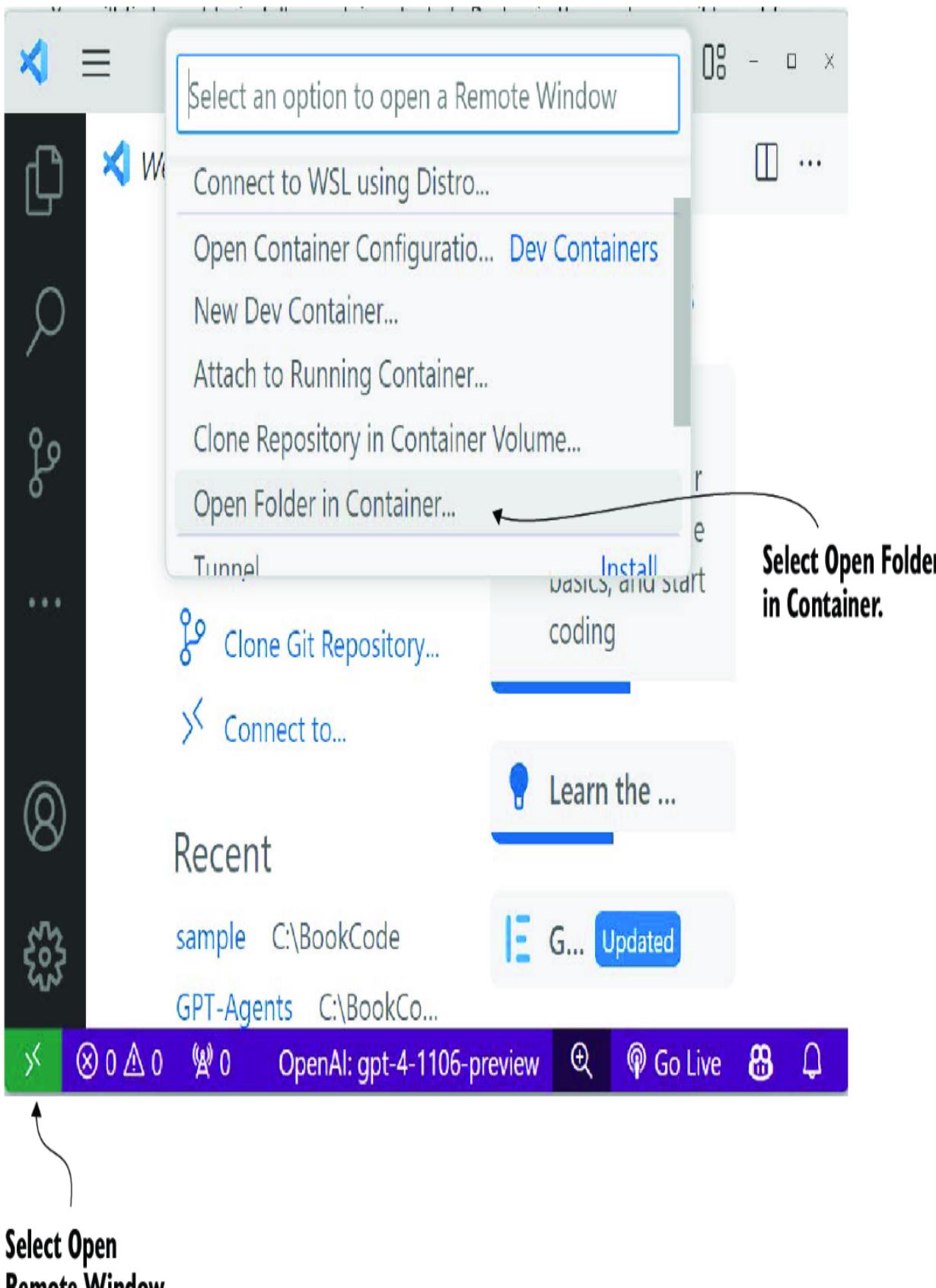
Figure B.3 Opening a remote window to a container in VS Code
Select Open Folder in Container to start a container from a folder, or select New Dev Container to start without a folder. 3.
After the container is launched, your VS Code environment will be connected. This allows you to develop code on the container without worrying about dependencies not working.
index
SYMBOLS
A
agent platforms
developing profiles and personas for agents
ABTs (agentic behavior trees), 2nd
managing assistants with assistants
actions
agent planning
conversational autonomous multi-agents
agents
AGI (artificial general intelligence)
B
C
ChatGPT, engaging assistants through, 2nd
coding challenge ABT (agentic behavior tree)
create\_assistant\_condition helper function
create\_manager\_assistant action
D
direct solution prompting, 2nd
question and answer prompting, 2nd
E
evaluate\_recommendation block
evaluation, employing for consistent solutions
F
functions
feedback
application of feedback to agentic/assistant applications, 2nd
G
GPT Assistants Playground, 2nd
getting assistant to run code locally
installing assistants database
investigating assistant process through logs
using and building custom actions
GPTs (Generative Pretrained Transformers)
GPT (Generative Pretrained Transformer) assistants
get\_response\_stream function
group chat with agents and AutoGen
get\_top\_movie\_by\_genre function
I
IDEs (integrated development environments)
J
K
extending assistants’ knowledge using file uploads
L
LM Studio
M
building agent crew with CrewAI
revisiting coding agents with CrewAI, 2nd
consuming memory stores in Nexus
implementing in agentic systems, 2nd
max\_rpm (maximum requests per minute)
N
Nexus
O
OpenAI
connecting to chat completions model
P
PCA (principal component analysis)
agent profiles, evaluating, 2nd
grounding evaluation with LLM profile
prompt\_engineering.py file, 2nd
Python
profiles
Q
R
RLHF (reinforcement learning with human feedback)
RAG (Retrieval Augmented Generation), 2nd, 3rd
applying to building agent knowledge, 2nd
constructing with LangChain, 2nd
recommender\_with\_LLM\_evaluation flows visual editor
S
semantic skills, creating, 2nd
stepwise planner, OpenAI Strawberry, 2nd
SEO (search engine optimization)
self-consistency prompting, 2nd
embedding native functions within
Streamlit
building chat applications, 2nd
creating streaming chat applications
SK (Semantic Kernel), 2nd, 3rd, 4th
step-by-step with prompt chaining, 2nd
T
tokenization, splitting documents by token with LangChain
TF-IDF (Term Frequency-Inverse Document Frequency)
ToT (tree of thought) prompting, 2nd
U
unstructured memory/knowledge concepts
V
Inverse Document Frequency (IDF)
querying document embeddings from Chroma
VS Code
VS Code Dev Containers (Docker)
VS Code (Visual Studio Code), 2nd, 3rd, 4th
creating new Python environment with
W
WSL (Windows Subsystem for Linux)
X
X (formerly Twitter)
Y
YouTube